一句话总结:本文提出了一个大规模、高质量的指令图像编辑数据集ULTRAEDIT,它通过使用真实图像作为锚点来减轻生成偏见,并首次大规模地自动生成带区域掩码的样本,从而显著提升了模型的细粒度编辑能力和泛化性。
1. 总体介绍
1.1 问题背景
- 现有问题:
- 指令多样性不足:人工标注成本高、规模小(如MagicBrush);而完全依赖LLM生成,指令的创造性和泛化能力会受限(如IP2P)。
- 图像数据存在隐性偏见:许多数据集完全依赖T2I模型生成源图像和目标图像,但T2I模型本身存在偏见(比如更倾向于生成卡通风格),导致数据集不均衡,训练出的模型在真实世界图像上表现不佳。
- 缺少基于区域的编辑数据:大多数数据集只支持全局的自由编辑,但实际应用中,用户常常需要对图像的特定区域进行精细修改(即提供一个mask)。缺少这类数据,模型难以学习到细粒度的控制能力。
1.2 论文贡献
- 提出一个系统的、自动化的数据生成流程,旨在解决上述三个问题。
- 构建了ULTRAEDIT数据集:这是一个大规模、高质量的数据集,包含约 400 万编辑样本,涵盖 75 万条独特指令,涉及 9 种以上编辑类型
- 指令多样:结合了LLM和人类先验知识。
- 数据均衡:使用真实图像作为“锚点”来指导T2I模型,减少偏见。
- 支持区域编辑:包含大量自动生成的区域-指令-图像对。
- 进行了广泛的实验:证明了在ULTRAEDIT上训练的模型在多个基准上达到了新的SOTA,并深入分析了数据集设计的关键因素。
2. Method
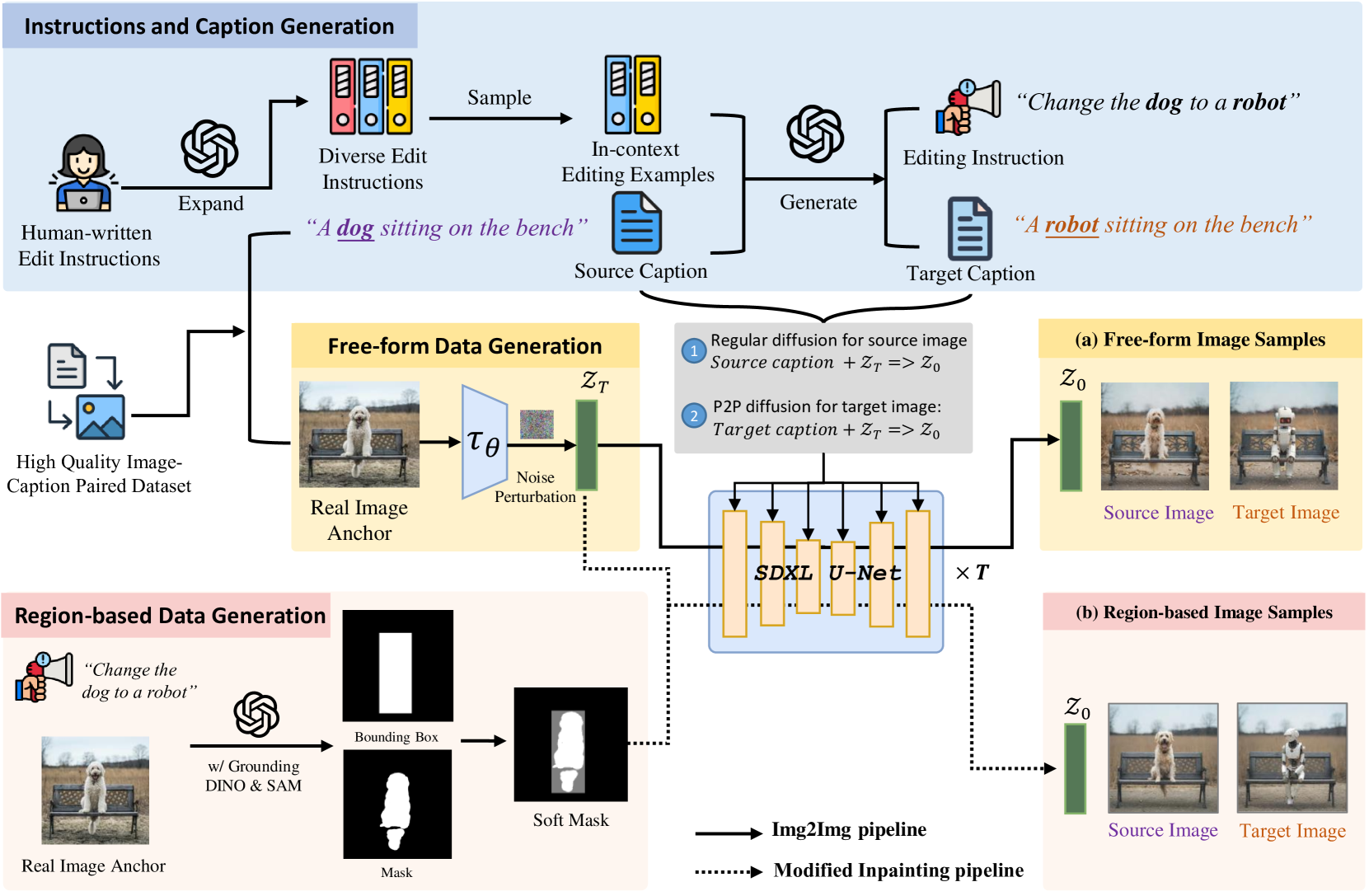
2.1 指令与标题生成 (Instructions and Caption Generation)
- 输入:
- 人类编写的编辑指令 (Human-written Edit Instructions):研究人员先手动编写一批高质量、多样化的编辑指令作为“种子”或示例。
- 高质量图文对数据集 (High Quality Image-Caption Paired Dataset):从COCO等公开数据集中获取大量的真实世界图像及其对应的描述。
- 流程:
- 指令扩展 (Expand & In-context):利用大型语言模型(LLM)将人工编写的“种子”指令进行扩展,形成一个庞大且多样化的“编辑指令池”。
- 指令生成 (Generate):从图文数据集中取出一个真实的图像描述),并从“编辑指令池”中随机抽取一些作为上下文示例(In-context Editing Examples),然后请求LLM完成两件事:
- 生成一条合适的编辑指令 (Editing Instruction)
- 根据这条指令,修改源标题,生成一个目标标题 (Target Caption)
2.2 自由形式数据生成 (Free-form Data Generation)
这条路径负责生成不需要特定编辑区域(Mask)的通用编辑图像对。
- 核心思想: 使用真实图像作为锚点 (Real Image Anchor),以避免完全由T2I模型生成带来的偏见和不真实感。
- 流程:
- 获取锚点: 从图文数据集中取一个真实的图像(Real Image Anchor)和其对应的源标题。
- 准备噪声: 对真实图像的潜在表示(Latent)施加一次噪声扰动 (Noise Perturbation),得到一个初始噪声潜在变量 。这个 是后续生成源图像和目标图像的共同起点,确保了两者结构上的一致性。
- 生成源图像 (Source Image):将初始噪声 和源标题输入到SDXL U-Net(扩散模型)中,生成源图像。由于 zT 源于真实图像,所以生成的源图像在风格和内容上会与真实图像非常相似。
- 生成目标图像 (Target Image):使用完全相同的初始噪声 zT,但这次结合目标标题,并利用 P2P (Prompt-to-Prompt) 控制技术 来生成目标图像。P2P技术能确保图像的非编辑部分(如背景)保持不变,只精确修改指令中提到的内容(把“狗”变成“机器人”)。
2.3 基于区域的数据生成 (Region-based Data Generation)
这条路径是本文的一大创新,负责生成需要对特定区域进行精细编辑的样本。
- 流程:
- 识别编辑区域: 同样从一个真实图像锚点开始。利用 Grounding DINO 和 SAM (Segment Anything Model) 这两个强大的视觉模型,根据“编辑指令”自动定位并分割出需要编辑的物体。
- 生成掩码 (Mask):SAM会输出一个精确的物体分割掩码(Mask)。为了让最终编辑的边界更平滑,这个掩码会被处理成一个软掩码 (Soft Mask)。
- 生成图像 (Modified Inpainting pipeline):
- 源图像的生成方式与自由形式路径相同。
- 目标图像的生成则采用一个改进的修复(Inpainting)流程。这个流程会同时接收初始噪声 、目标标题和上一步生成的软掩码。它的特殊之处在于,它会引导扩散模型只在掩码区域内进行内容修改,同时确保编辑区域与周围背景的无缝融合,避免产生生硬的边界。
2.4 数据集结果
数据集共包含 4,108,262 条基于指令的图像编辑数据,其中自由形式图像编辑(无区域标注 Im )达 4,000,083 例,基于区域的编辑样本为 108,179 个。是目前公开的最大规模数据集,涵盖超过 9 种编辑指令类型
2.5 质量评估
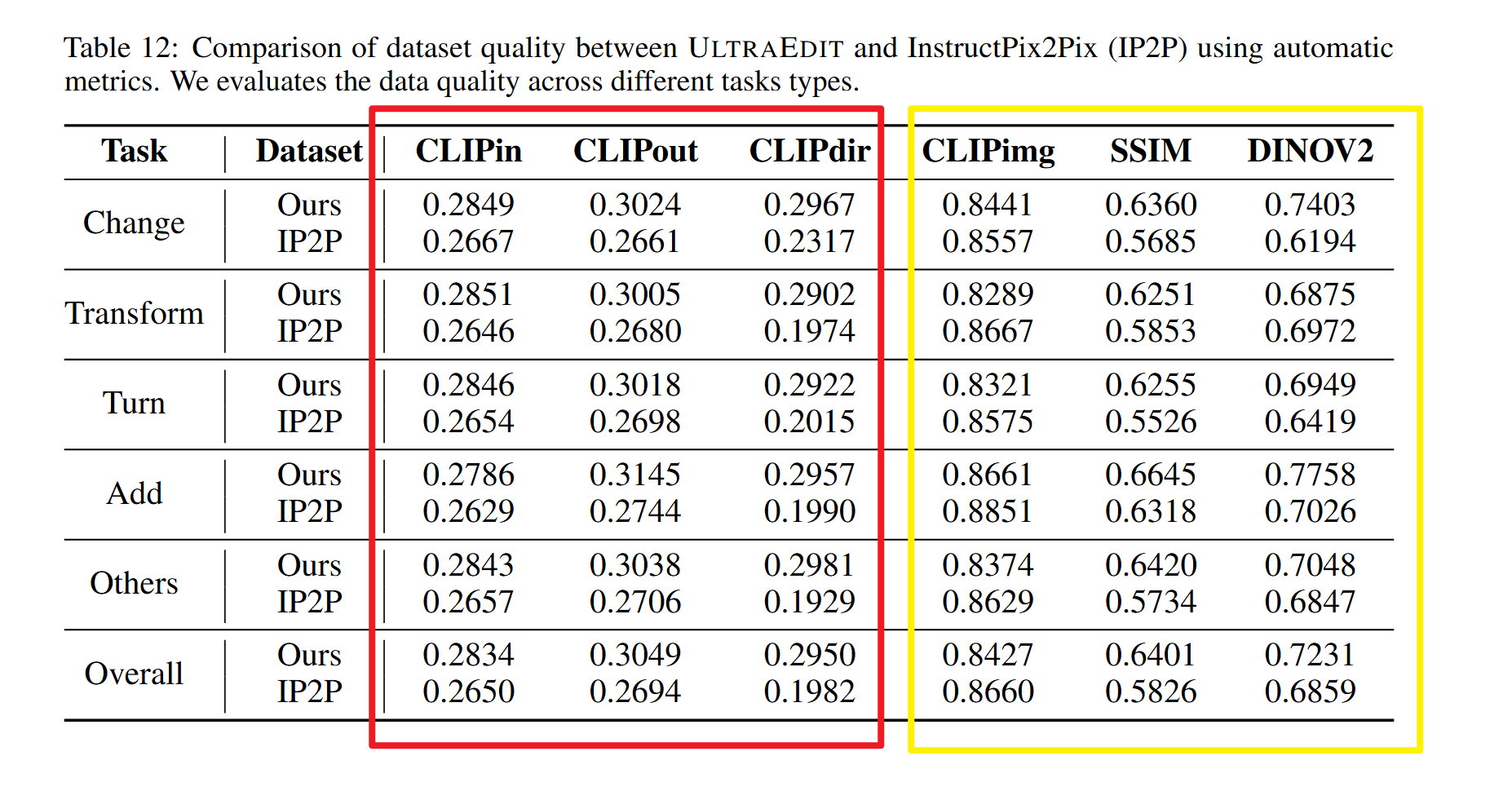
使用DINOv2相似度,CLIP相似度,原图像和目标图像间的SSIM以保证语义相似性与像素级连贯性得以保持,通过CLIP Text来确保生成图像准确反映编辑指令。采用 CLIP 方向相似度来量化图像变化与对应描述变化之间的对齐关系,验证数据集的指令遵循能力
CLIPdir:
- 计算图像变化向量:
- 计算文本变化向量:
- 计算这两个变化向量之间的余弦相似度。
3. 实验/评估/结果
3.1 实验设置
- 模型:为了公平对比,作者使用了经典的InstructPix2Pix模型架构(基于Stable Diffusion v1.5)在ULTRAEDIT上进行训练。为了支持区域编辑,他们修改了模型的U-Net,使其可以额外接收一个mask作为输入。
- 基准 (Benchmarks):在两个公认的基准上进行评估:MagicBrush(评估单轮和多轮编辑能力,有ground truth图像)和Emu Edit Test(评估泛化能力,没有ground truth,更具挑战性)。
- 评估指标:包括L1/L2距离、CLIP图像/文本相似度、DINO相似度等,全面衡量编辑的准确性和图像保真度。
3.2 结果
3.2.1 MagicBrush上的表现
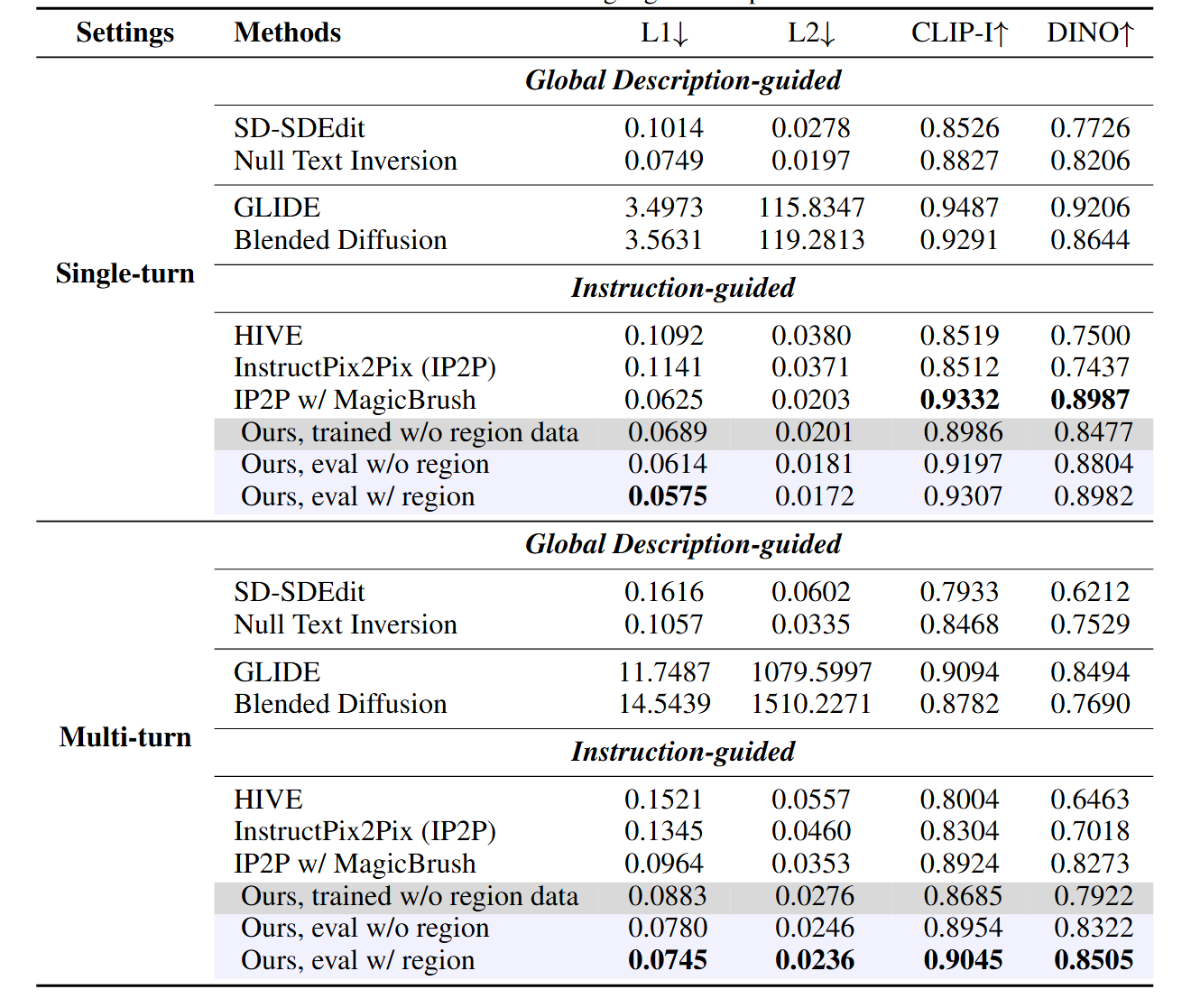
- 仅用ULTRAEDIT的自由形式数据训练,性能就已显著优于基线模型。
- 加入少量区域编辑数据进行混合训练后,即使在测试时不提供mask,模型性能也能进一步提升,说明模型学到了更强的局部控制能力。
- 当在测试时提供mask输入时,模型性能达到SOTA,尤其是在困难的多轮编辑任务上,证明了区域编辑数据的巨大价值。
3.2.2 在Emu Edit上的表现
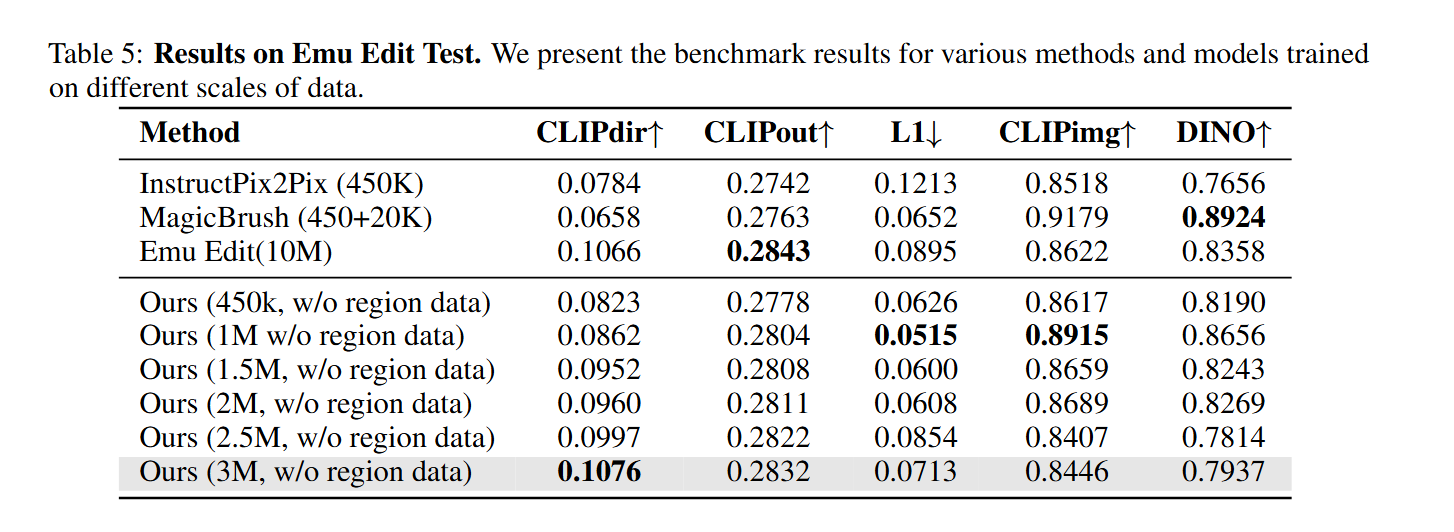
- 展示了规模效应 (Scaling Effect)。随着训练所用的ULTRAEDIT数据量从450K增加到3M,模型的性能(尤其是指令跟随能力CLIPdir)持续提升,最终超越了一个用10M私有数据训练的强大基线(Emu Edit)。
- 这证明了ULTRAEDIT不仅质量高,而且其大规模的特性能够有效提升模型的泛化能力。
3.2.3 消融实验
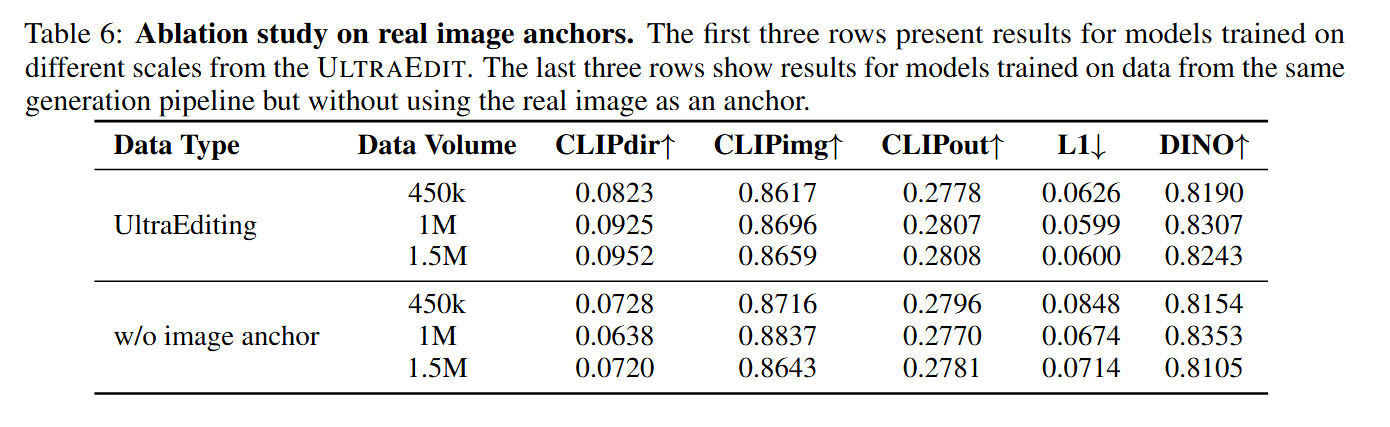
对比了使用和不使用真实图像锚点生成的两个数据集。结果显示,使用锚点的数据集训练出的模型性能更好,并且随着数据规模的扩大,性能提升更明显。这证明了真实图像锚点对于减轻模型偏见、提升数据质量至关重要。
4. 结论
提出了ULTRAEDIT,一个大规模、高质量的指令图像编辑数据集。通过一个系统的自动化生成流程,他们解决了现有数据集在指令多样性、图像偏见和区域编辑支持方面的不足。实验证明,在ULTRAEDIT上训练的模型在多个挑战性基准上取得了优异表现。这项工作为未来的图像编辑研究提供了宝贵的资源和基础。
5. 个人总结
这篇文章的核心贡献是“方法论”+“资源”,为数据质量和多样性提供了一套非常系统和巧妙的解决方案。其中,“真实图像锚点” 的设计解决了纯T2I生成数据带来的“同质化”和“偏见”问题,让合成数据更接近真实世界分布。