Diffusion_Models Generative_Models
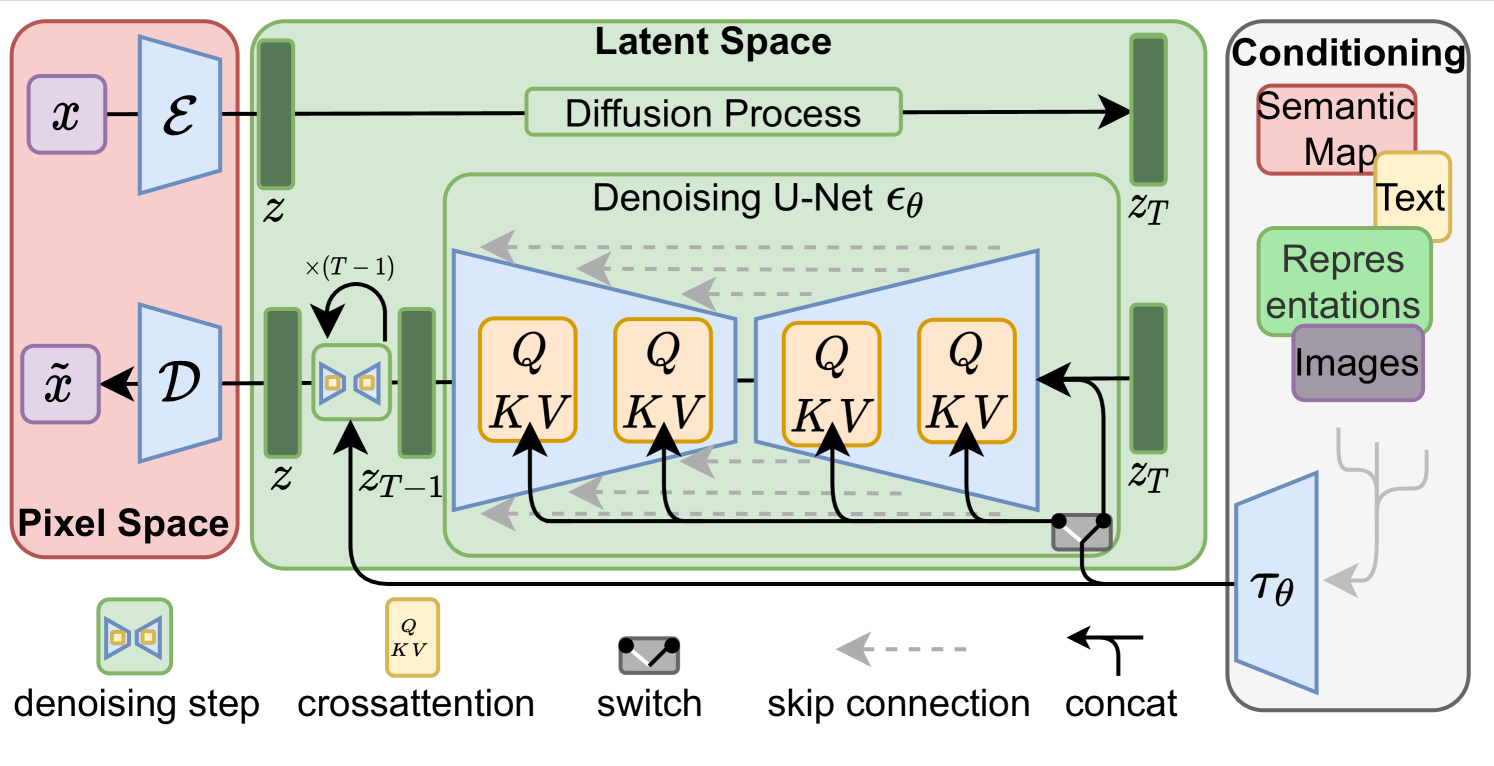
1. Pixel Space(像素空间)
这部分本质上是一个 变分自编码器,encoder负责将高分辨率的图片输入降维到潜空间表示,decoder将潜空间中已经完成去噪的潜向量解码,还原成一张高分辨率的、人眼可见的图像
变分自编码器
变分自编码器(Variational Autoencoder,VAE)是对自编码器(Autoencoder,AE)的改进,不再输出一个确定的点,而是输出一个概率分布的参数
2. Latent Space(潜空间)
2.1 Diffusion Process(扩散过程)
将潜向量添加步高斯噪音到,采用的1.1 去噪扩散概率模型(DDPM)
2.2 U-Net网络
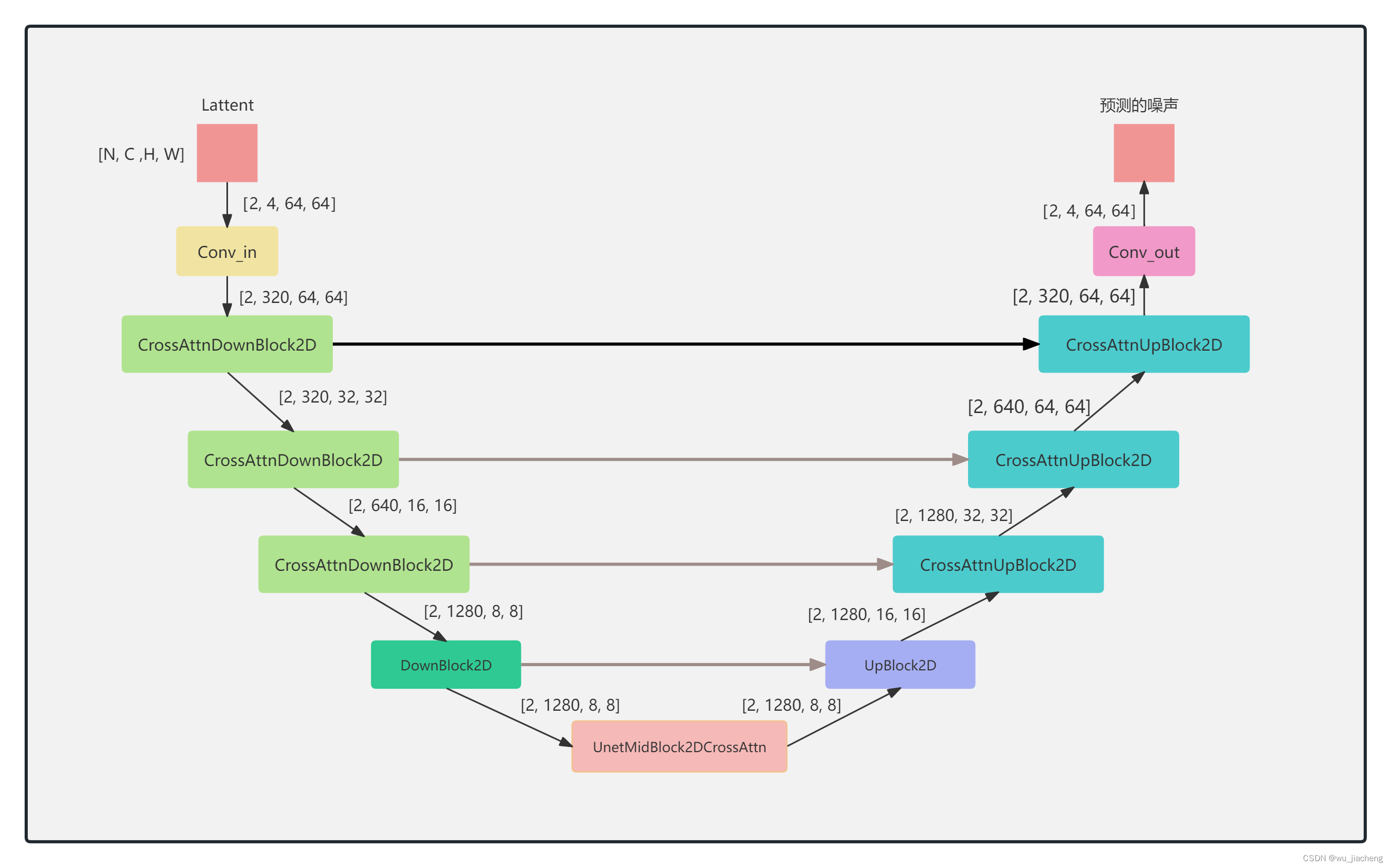
四维数据
N: Batch Size (批次大小) C: Channels (通道数),在像素空间中表示颜色通道,潜空间中表示特征通道 H: Height (高度) & W: Width (宽度)
2.2.1 CrossAttnDownBlock2D
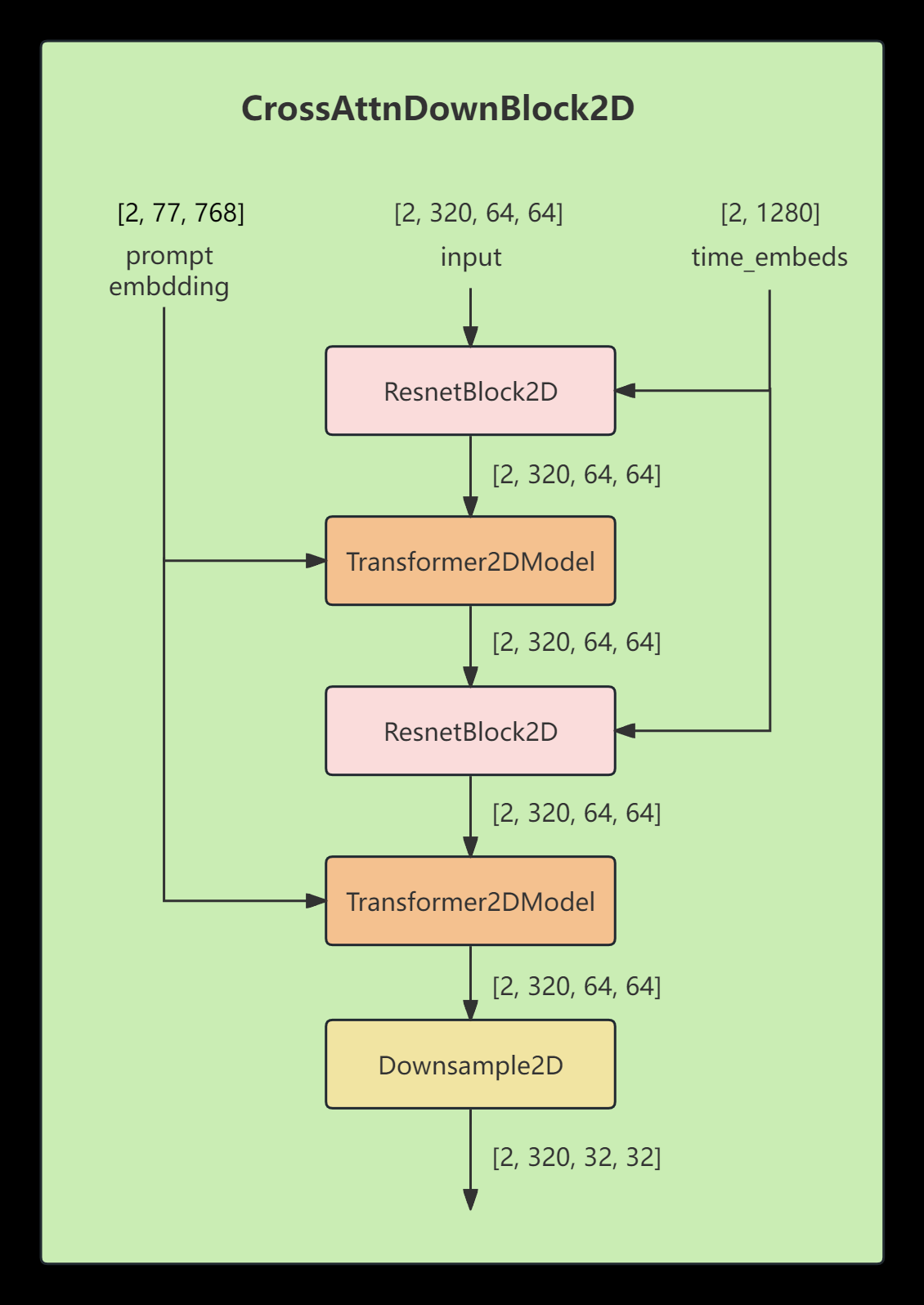
每个ResnetBlock2D的输入有两个:
- 一个是来自上一层的输出lattent,
- 另一个来自时间步编码模块的输出time_embeds ( shape=[2, 1280])
Note
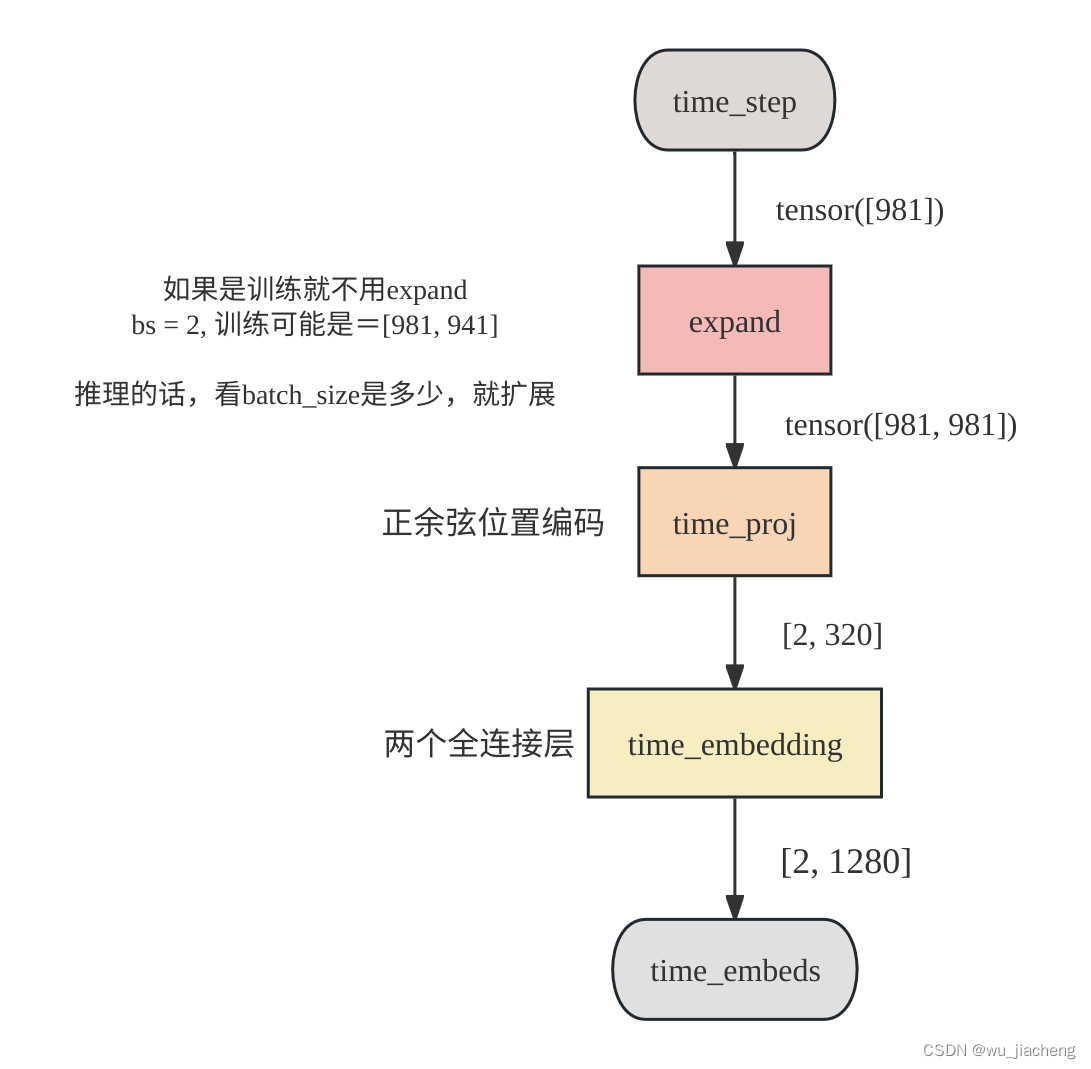
U-Net 必须知道当前正在处理第几步的去噪,才能知道应该去除多少噪声。time_embeds就是这个“时间”信息的载体。 模型需要一种方式来感知自己正处于哪个阶段。如果直接将整数 t 作为输入,会有几个问题:
- 数值不稳定:神经网络对输入值的范围很敏感。一个从 0 到 1000 的整数,其数值本身对于网络来说意义不大,且难以泛化。
- 缺乏连续性:网络无法从 t=500 和 t=501 的输入中,直观地理解它们代表的噪声水平非常接近。
- 信息量不足:一个标量整数所含的信息太少,不足以有效调节一个庞大神经网络的行为。 因此,我们需要将标量 t 转换成一个高维、信息丰富、且对网络友好的向量——这就是 time_embeds。
Note
time_embeds 的生成通常分两步: 4. 正弦位置编码 5. 通过一个小型神经网络 (MLP)
每个Transformer2DModel输入有两个
- 上一层的输出
- CLIP text_encoder的文本编码text embedding,或者叫提示词编码prompt embedding,其shape=[2, 77, 768]
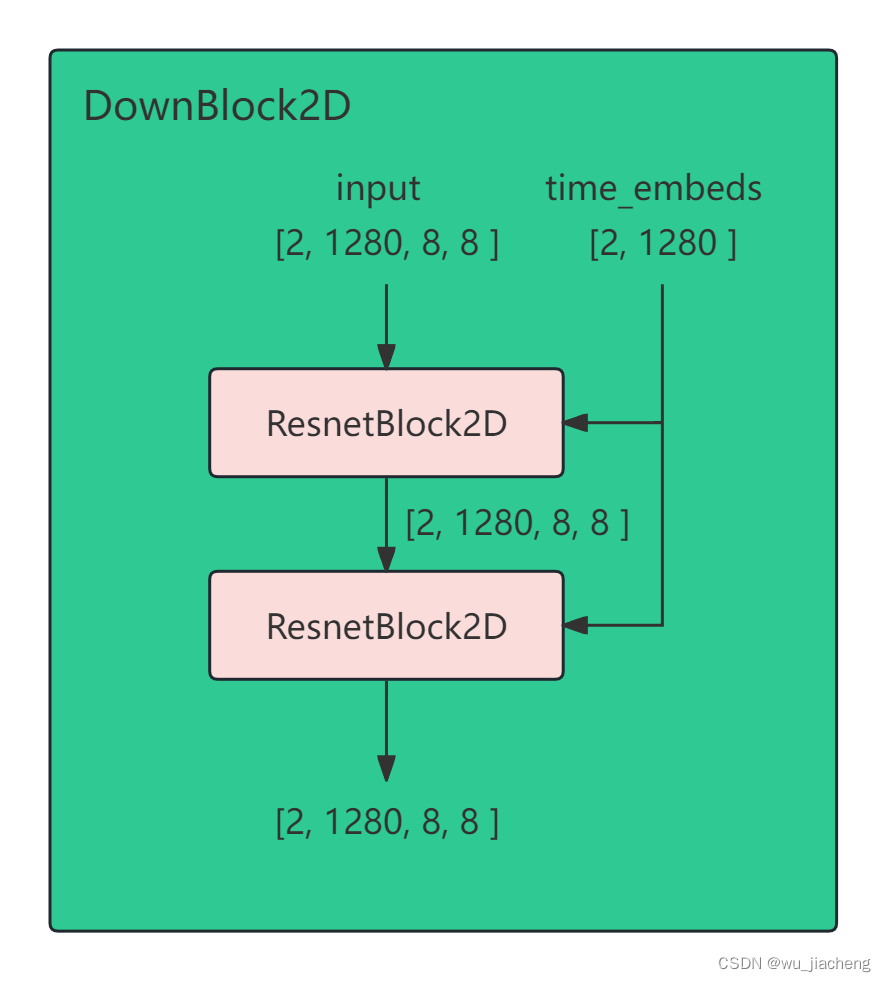
2.2.2 DownBlock2D
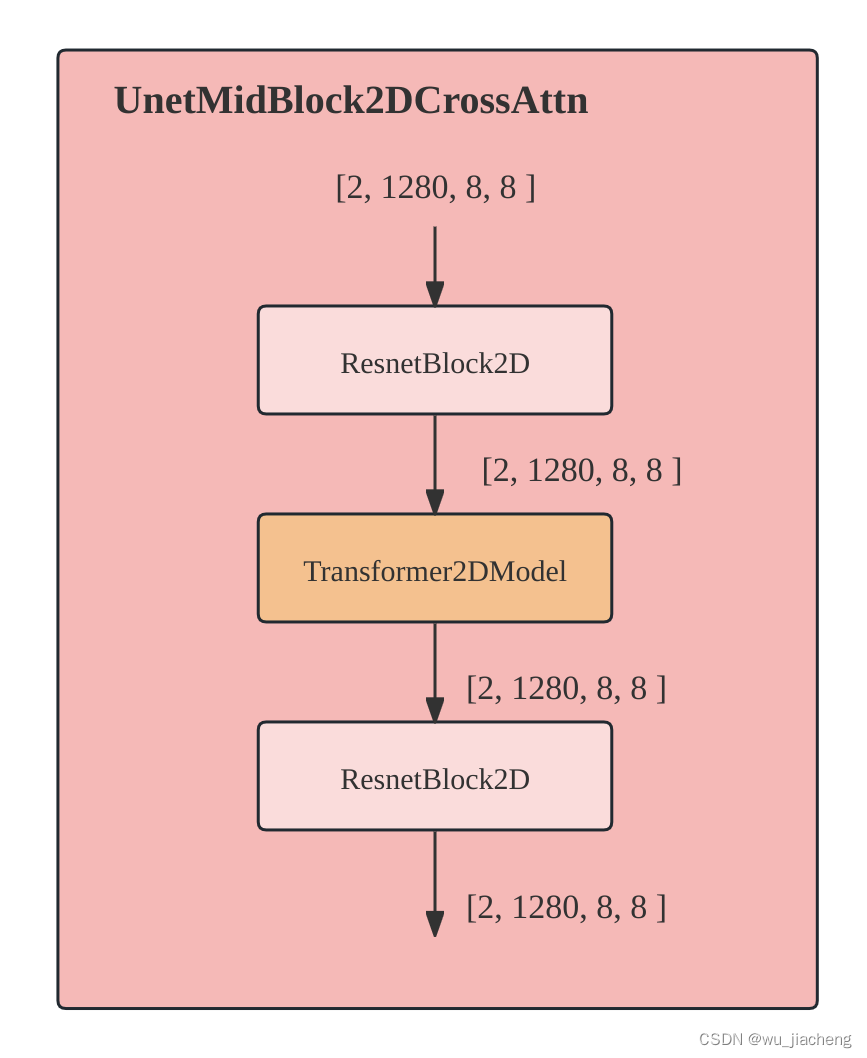
2.2.3 UnetMidBlock2DCrossAttn
2.2.4 UpBlock2D
UNet右边部分的ResnetBlock2D模块,其输入除了有来自上一层的输出和time_embedd之外,还有自UNet左边部分输入,具体做法是将上一层的输出和UNet左边部分输入进行拼接之后送进ResnetBlock2D模块,然后和time_embedd相加
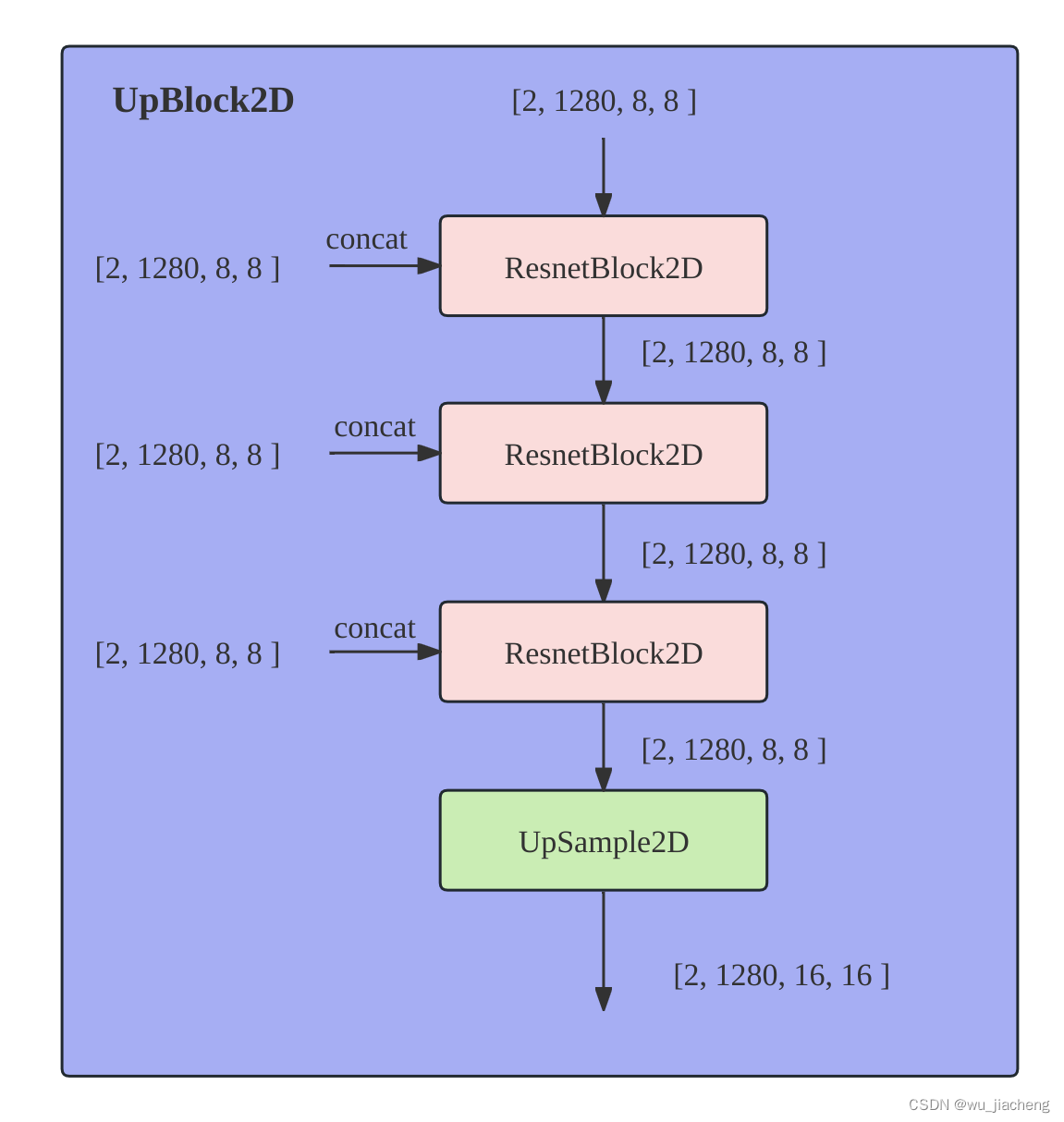
进行concat 的目的:U-Net 有一个下采样路径和一个上采样路径。下采样路径会逐步缩小特征图的 H 和 W,同时增加通道 C,以提取高级语义特征。但这个过程会丢失很多精细的空间细节。为了解决细节丢失问题,U-Net 会将下采样路径中、尺寸较大的特征图,通过“跳跃连接”(图中灰色虚线箭头)直接传送到上采样路径中对应的层
3 Conditioning(条件控制区域)
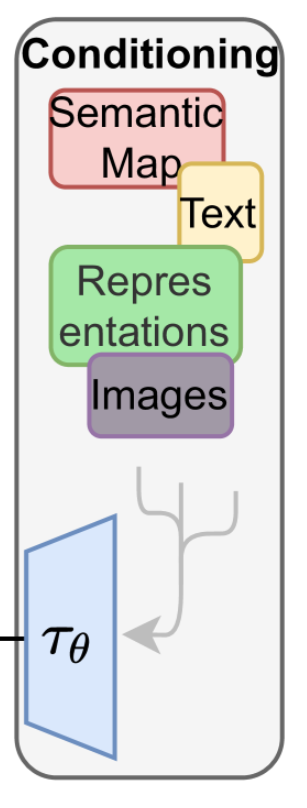
Conditioning Inputs (条件输入):可以是多种形式的信息,如图所示:
- Text (文本):最常见的,例如 “一只猫在垫子上”。
- Semantic Map (语义图):用不同颜色表示不同对象的分割图。
- Images (图像):用于图生图 (Image-to-Image) 的任务。
- Representations (其他表示):例如姿态骨架等。 Encoder (τθ, 条件编码器):
- 作用:将这些非数字化的条件信息(如文本)转换成模型可以理解的数字嵌入向量 (numerical embeddings)。
- 例子:对于文本,Stable Diffusion 通常使用一个预训练好的 CLIP Text Encoder 来完成这个任务。 Cross-Attention (交叉注意力机制):
- 这是将条件信息注入到 Denoising U-Net 中的关键机制。
- 工作原理(简化版): U-Net 内部的图像特征生成一个 Query (Q)。 来自条件编码器 τθ 的文本嵌入向量提供 Key (K) 和 Value (V)。 通过 Q、K、V 之间的计算,U-Net 可以在生成图像的特定区域时,“关注”到文本描述中最相关的部分。