一句话总结 :OminiControl 通过使用使用参数复用策略,将条件图像和噪声图像的 token 拼接成一个统一序列,并利用自适应位置编码和注意力偏置,以极低的参数开销在 Diffusion Transformer 上实现了对空间对齐和非空间对齐任务的通用、灵活且精确的控制。
1. 总体介绍
1.1 问题背景
现有控制方法的局限性:
- 开销大: 像 ControlNet 这样的方法需要复制整个去噪网络作为控制分支,导致参数量和计算开销巨大。
- 任务偏向性: 无法兼顾空间对齐与非空间对齐
- 与DiT不兼容:现在主流方法是为U-Net设计,无法迁移到DiT
1.2 论文主要贡献
- 提出了OminiControl框架:
- 使用参数复用策略实现最小化框架,仅增加0.1%参数量
- 将条件标记与含噪图像标记直接拼接为统一序列
- 采用动态定位策略,根据任务类型自适应分配位置索引
- 们设计了灵活的注意力偏置机制,可在推理阶段精确调节条件强度
- 构建并开源 Subjects200K 数据集,包含超过 20 万张身份一致性图像
2. 背景知识
DiT
DiT通过模仿ViT,使用Transform架构替换U-Net架构实现了性能提升
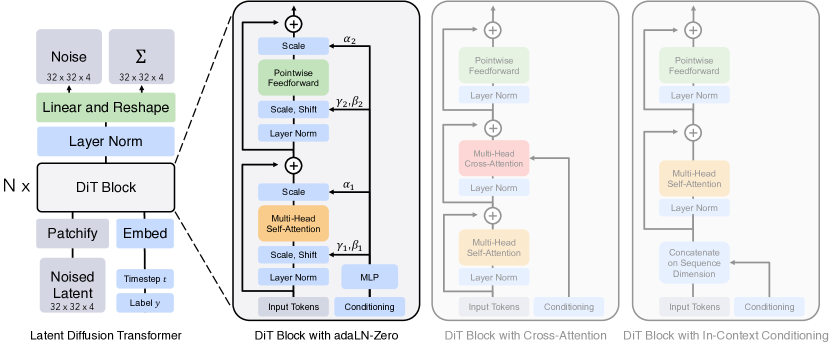
Latent Diffusion Transformer
- Noised Latent (带噪的潜空间表示):输入不是原始的像素图像,而是在潜空间(latent space)中经过加噪处理的表示。
- Timestep t 和 Label y:
- Timestep t: 告诉模型当前处于去噪过程的第几步
- Label y: 类别标签,告诉模型要生成哪个类别的图像。
- 两个被嵌入后采用的相加方法拼接作为condition
- Patchify & Embed (分块与嵌入):
- Patchify: 将潜空间特征图分块
- Embed: 将时间步t和标签映射为向量
- DiT Block (N x):这是模型的核心,由N个相同的DiT Block堆叠而成。
- Output (输出):经过N个DiT Block处理后,输出的Tokens会经过Linear and Reshape层,重新组合成潜空间特征图
- Noise & Σ:模型预测的不是去噪后的图像,而是应该从当前输入中移除的噪声。Σ表示模型的另一个可选预测,即去噪过程的协方差,用于更高级的采样策略。
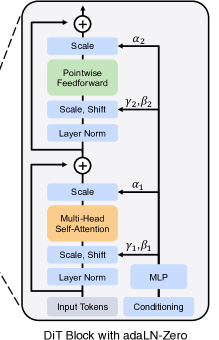
DiT Block with adaLN-Zero
- Conditioning → MLP: 首先,时间步t和标签y的Tokens被送入一个MLP),生成用于控制的参数 γ 和 β
- adaLN (Adaptive Layer Norm): γ和β被用来对Layer Norm层的输出进行仿射变换(Scale, Shift)。这是一种条件注入方式,通过动态调整归一化的结果来控制生成内容。adaLN
- Multi-Head Self-Attention: 这是Transformer的核心,用于计算输入Tokens之间的关系。
- Pointwise Feedforward: 这是Transformer的另一个标准组件,通常是一个MLP,用于对每个Token进行非线性变换。
- Shortcut: 图中带+号的圆圈代表残差连接。
- adaLN-Zero: 除了adaLN,这里还引入了α (alpha) 参数,它也被条件控制。α被初始化为0,所以在一开始训练时,整个残差块是“关闭”的(相当于一个恒等映射),这有助于稳定训练初期的过程。
指向原始笔记的链接 class DiTBlock(nn.Module): """ A DiT block with adaLN-Zero conditioning. """ def __init__(self, hidden_size, num_heads, mlp_ratio=4.0, **block_kwargs): super().__init__() self.norm1 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6) self.attn = Attention(hidden_size, num_heads=num_heads, qkv_bias=True, **block_kwargs) self.norm2 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6) mlp_hidden_dim = int(hidden_size * mlp_ratio) approx_gelu = lambda: nn.GELU(approximate="tanh") self.mlp = Mlp(in_features=hidden_size, hidden_features=mlp_hidden_dim, act_layer=approx_gelu, drop=0) self.adaLN_modulation = nn.Sequential( nn.SiLU(), nn.Linear(hidden_size, 6 * hidden_size, bias=True) ) # zero init nn.init.constant_(adaLN_modulation[-1].weight, 0) nn.init.constant_(adaLN_modulation[-1].bias, 0) def forward(self, x, c): shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.adaLN_modulation(c).chunk(6, dim=1) x = x + gate_msa.unsqueeze(1) * self.attn(modulate(self.norm1(x), shift_msa, scale_msa)) x = x + gate_mlp.unsqueeze(1) * self.mlp(modulate(self.norm2(x), shift_mlp, scale_mlp)) return x
3. Method
3.1 OminiControl
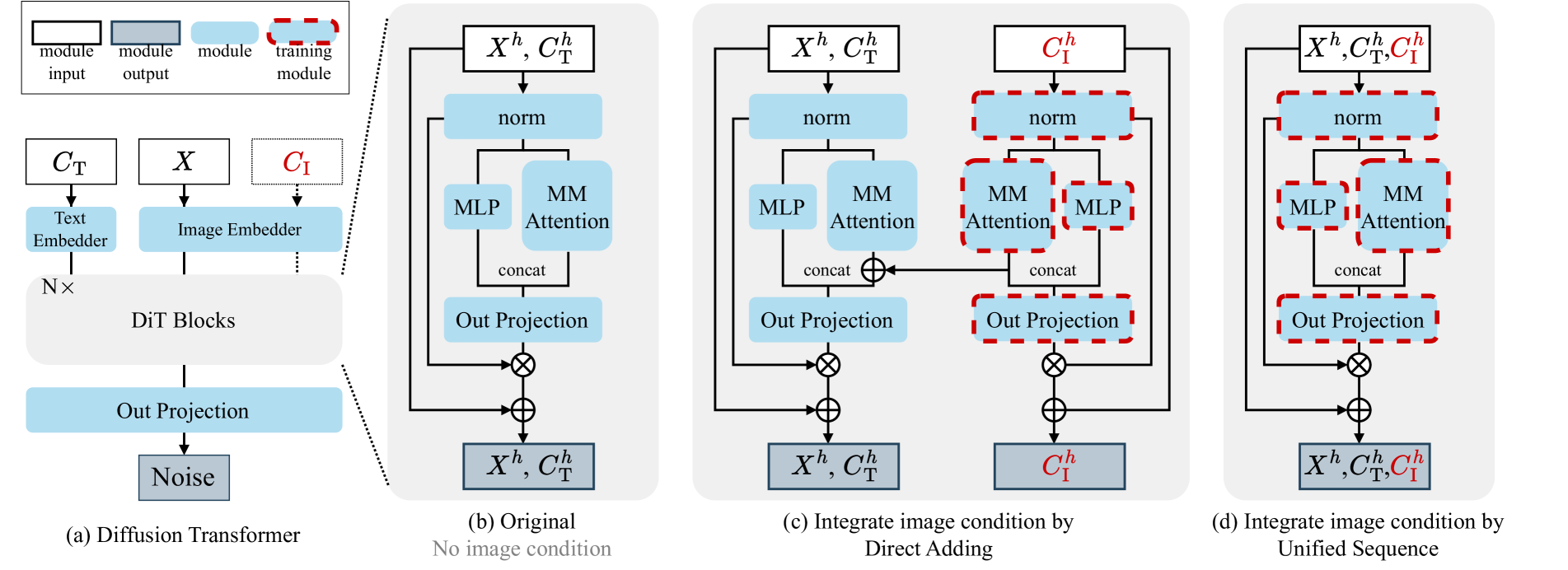
(b)图表示的是原始DiT,无条件控制,(c)图是ControlNet等使用的通过一个独立的、可训练的网络分支来实现条件控制,(d)是 OminiControl 采用的方法
3.1.1 最小化架构
- 参数重用 (Parameter Reuse):
- 重用 VAE 编码器:直接使用 DiT 模型自带的 VAE 编码器来处理输入的条件图像(如 Canny 边缘图),将其映射到与噪声图像相同的潜在空间,无需引入额外的编码器。
- 重用 Transformer 块:条件 token 和图像 token 共享 DiT 模型中的 Transformer 块进行处理。
- 轻量级微调 (Lightweight Fine-tuning):仅使用 LoRA 对共享的 Transformer 块进行微调,以适应新的条件输入,避免了全量参数更新。
3.1.2 Omni-capable token interaction
a)统一序列处理
ControlNet 等方法通过将条件特征图直接加到 U-Net 的中间层特征图上。这种硬性相加的方式天然适合空间对齐任务,但对于非空间对齐任务则显得僵硬,限制了模型学习更复杂的语义关系。
本文将 VAE 编码后的条件 token 、文本 token 和噪声图像 token 直接拼接成一个长序列 。使用注意力机制自由学习token间关系。
b)动态位置编码
根据任务类型动态地选择位置编码策略。
- ---(空间对齐)
- (非空间对齐)
c)灵活的控制强度
将条件拼接后不能直接控制强度,将注意力公示改为
-
对角线上的
0矩阵:- : 内部 token 之间的注意力分数不加偏置。
- : 内部 token 和 内部 token 之间的注意力分数也不加偏置。
- 这意味着模型内部的自注意力关系(文本内部、图像内部)保持原样。
-
非对角线上的
log(γ)矩阵:- 关键部分: 偏置项只被添加到了带噪图像 token
X与 条件图像 tokenC_I相互作用的部分。 - : 这是一个所有元素都为 的矩阵。 是全1矩阵。
- 关键部分: 偏置项只被添加到了带噪图像 token
3.2 Subjects200K 数据集
- 构建流程:
- 提示生成 (Prompt Generation):使用 GPT-4o 生成超过 30,000 个多样化的主体描述。
- 图像对合成 (Paired-image Synthesis):将主体描述构造成“同一主体在两个不同场景”的结构化提示,输入 FLUX.1 生成图像对。
- 质量评估 (Quality Assessment):再次使用 GPT-4o 评估生成的图像对,剔除身份不一致或质量低的样本。
4. 实验/评估/结果
- 基础模型:FLUX.1。
- 训练数据集:text-to-image-2M(for 空间对齐),Subjects200K(for 非空间对齐)
- 对比模型:
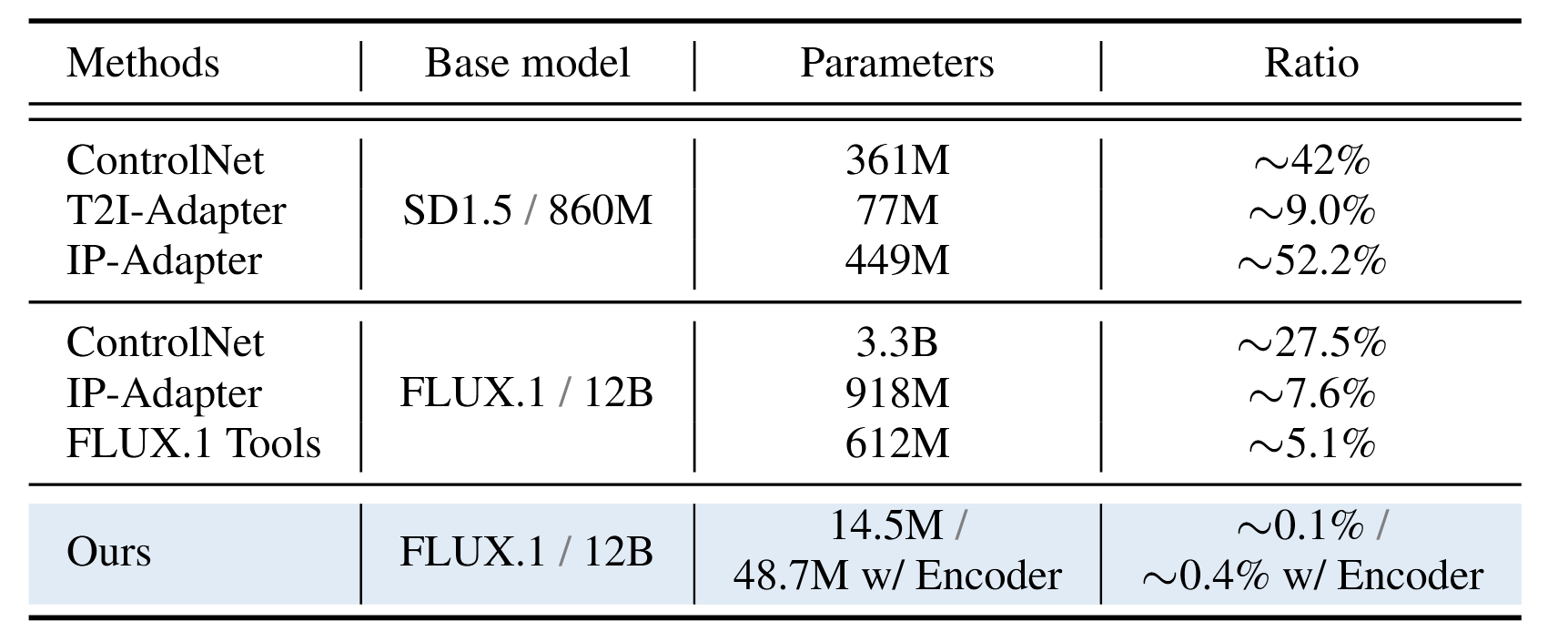
与其他方法相比,OminiControl 仅需 14.5M(约 0.1%)的可训练参数,远低于其他方法
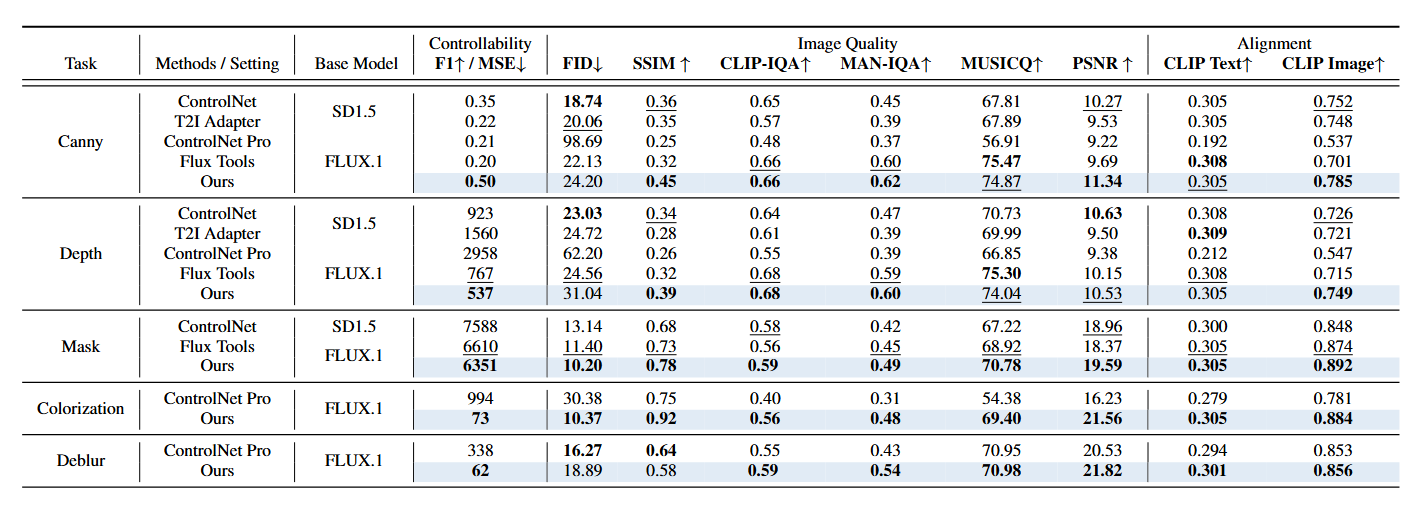
在下面五个Task中,
- Canny: 使用 Canny 算子提取的边缘图作为条件。
- Depth: 使用深度图作为条件。
- Mask: 使用蒙版进行图像修复
- Colorization: 图像上色,输入是灰度图,输出是彩色图。
- Deblur: 图像去模糊。
Note
F1↑:比较↑生成图像的边缘图与输入的原始 Canny 边缘图,F1 分数是精确率和召回率的调和平均值 MSE↓:在任务条件下计算生成与原始图的像素级别的均方误差
FID
FID (Fréchet Inception Distance)
↓指向原始笔记的链接
- 用途: 衡量生成图像集的真实性 (Realism) 和多样性 (Diversity)。
- 原理: FID 认为,如果生成图像集的特征分布与真实图像集的特征分布非常接近,那么生成的图像就足够好。
- 计算方法:
- 准备一个大规模的真实图像集和一个生成图像集。
- 用一个预训练好的 InceptionV3 网络的中间层来提取每张图片的特征向量。
- 假设真实图像和生成图像的特征向量分别服从两个多元高斯分布,计算出这两个分布的均值 () 和协方差矩阵 ()。
- 计算这两个高斯分布之间的 Fréchet 距离(也叫 Wasserstein-2 距离):
- 优缺点:
- 优点: 与人类的感知判断有很强的相关性,是目前公认的评估生成模型质量的黄金标准之一。
- 缺点: 需要大量的样本(通常上万张)才能得到稳定的结果,计算成本较高,且对 InceptionV3 模型有依赖。
- 解读: FID 越低说明生成质量越高
CLIP-IQA:IceClear/CLIP-IQA: [AAAI 2023] 探索 CLIP 在图像视觉感知质量评估中的应用 --- IceClear/CLIP-IQA: [AAAI 2023] Exploring CLIP for Assessing the Look and Feel of Images MAN-IQA:IIGROUP/MANIQA: [CVPRW 2022] MANIQA: 基于多维度注意力网络的无参考图像质量评估 --- IIGROUP/MANIQA: [CVPRW 2022] MANIQA: Multi-dimension Attention Network for No-Reference Image Quality Assessment MUSICQ:anse3832/MUSIQ: Unofficial implementation of MUSIQ (Multi-Scale Image Quality Transformer) PSNR:峰值信噪比SSIM
SSIM (Structural Similarity Index)
↑指向原始笔记的链接
- 用途: 衡量两张图像的结构相似性。
- 计算步骤: SSIM 从三个方面比较图像
x和y:
- 亮度 (Luminance): 比较两张图像的平均像素值
μ_x,μ_y。- 对比度 (Contrast): 比较两张图像的像素值标准差
σ_x,σ_y。- 结构 (Structure): 比较两张图像的协方差
σ_xy。- SSIM = (通常
α,β,γ设为1)。- 意义: SSIM 的取值范围是
[-1, 1],越接近 1,表示两张图像在人眼看来结构越相似。它比 MSE 和 PSNR 更符合人类的视觉感知。CLIP Text
生成图像的特征向量 和文本特征向量 之间的余弦相似度。
指向原始笔记的链接CLIP Image
生成图像与条件图像的特征向量的余弦相似度
指向原始笔记的链接
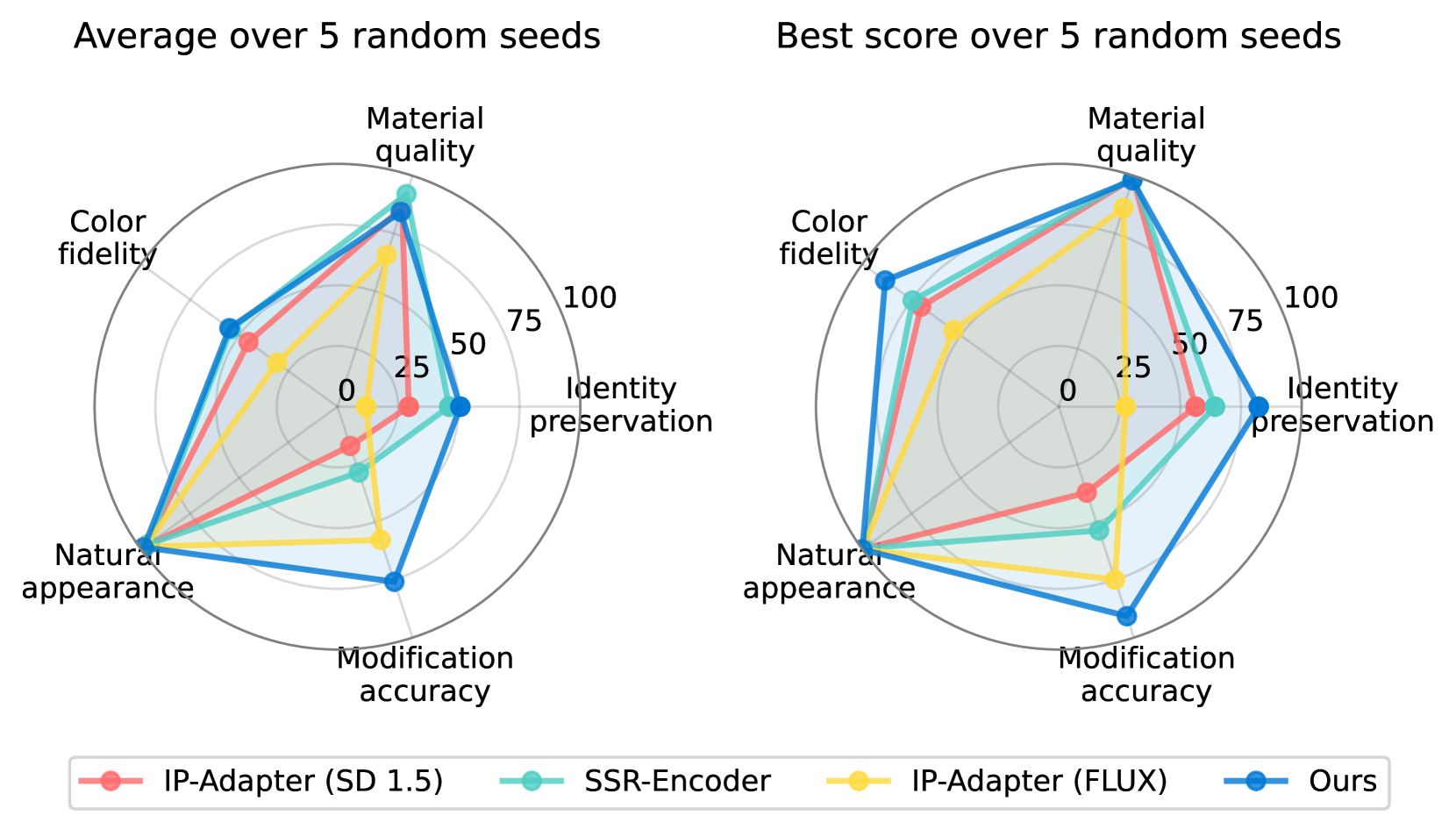
五项评价指标,使用GPT-4o 的视觉能力完成,但未提供具体的计算方法:
- 身份特征保持:评估关键识别特征(如标识、品牌标记、独特图案)的保留程度
- 材质质量:检验材料属性与表面特征是否得到准确呈现
- 色彩保真度:评估未指定修改区域的色彩一致性
- 自然呈现:评估生成图像是否真实且具有连贯性
- 修改准确性:验证文本提示中指定的修改是否被正确执行
5. 结论
OminiControl 通过统一的标记方法,为 DiT 提供了参数高效的图像条件控制,仅需增加 0.1%的参数即可适用于多样化任务。Subjects200K 数据集包含超过 20 万张高质量、主体一致的图像,进一步推动了主体驱动生成领域的发展,实验结果证实了 OminiControl 在空间对齐和非对齐任务中的有效性。