本文提出了第一个端到端的统一多模态智能体 Unify-Agent,通过原生的“思考-检索-重写-生成”工作流,解决了大型生成模型在处理现实世界中罕见和长尾概念时面临的事实错误和身份偏移问题
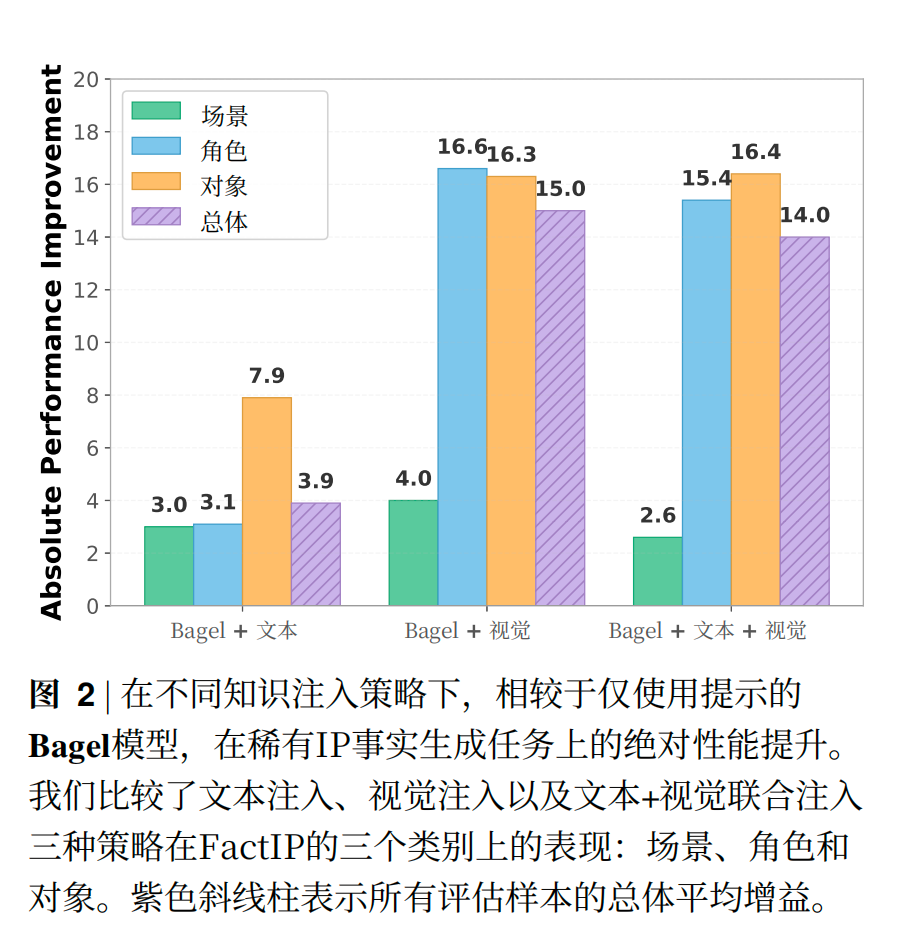
性能提升主要来源于提供的目标IP的两张真实参考图像,我感觉像是I2I 与 T2I 比与目标 IP 的相似度
Abs
motivation
现有的文生图系统主要依赖模型内部冻结的参数化记忆进行“闭卷”生成。当用户的提示词涉及到模型没见过的长尾概念时,模型就会因为缺乏相关的世界知识而产生严重的身份偏离和细节幻觉 。作者希望结合现有的外部检索的 Agentic 系统提升稀有 IP 的生成能力。
解决方案
作者提出了 Unify-Agent,将图像生成重构为一个包含
- 提示词理解
- 多模态证据搜索
- 基于外部证据的重写(Recaptioning)
- 最终图像合成” 的智能体流水线 。
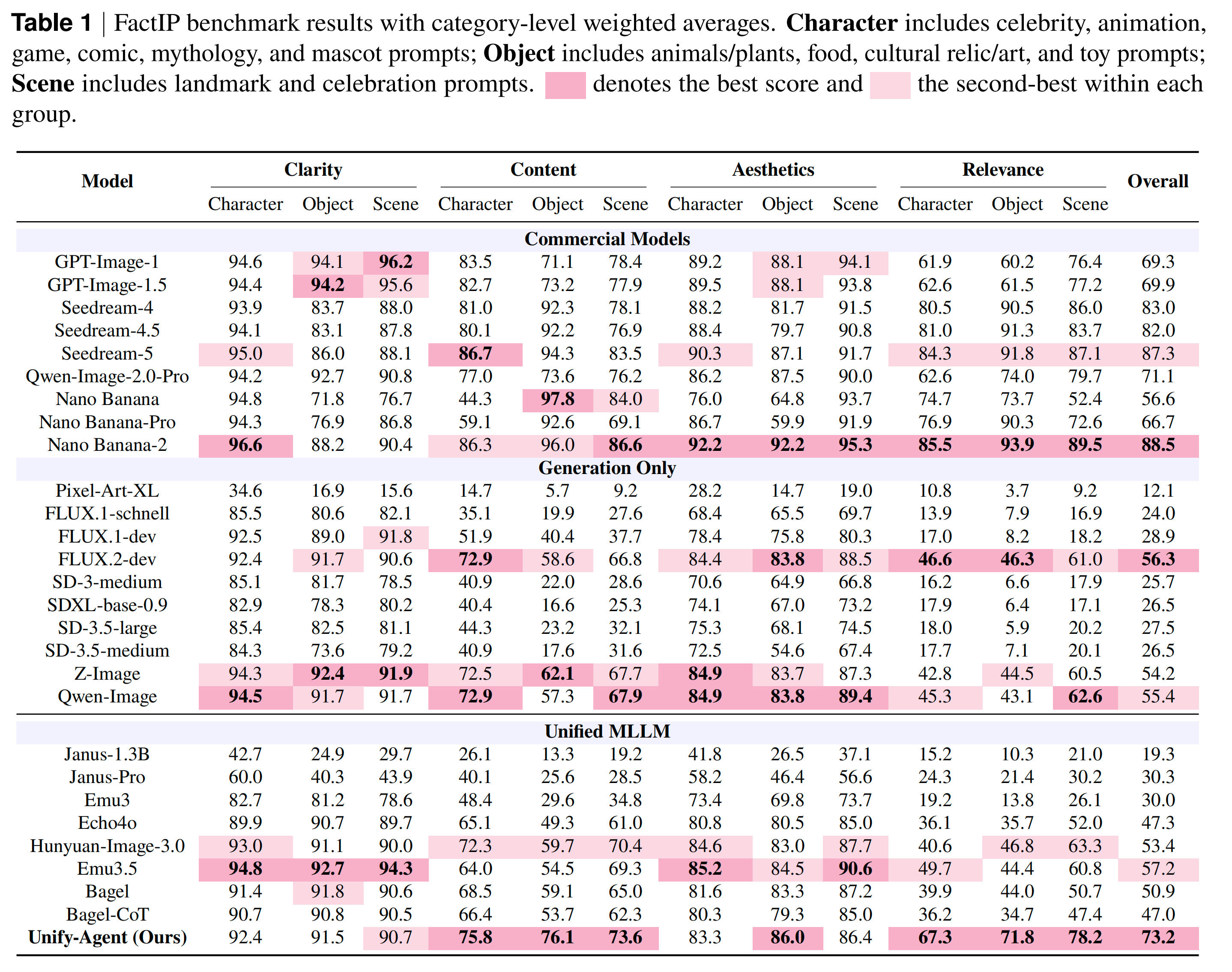
为了训练该模型,作者构建了包含 143K 条高质量智能体轨迹的数据集,并提出了专门评估长尾文化概念事实准确性的新基准 FactIP 。广泛的实验表明,Unify-Agent 显著超越了其基础模型,并在世界知识的表现上逼近了最强闭源模型的水平 。
Method
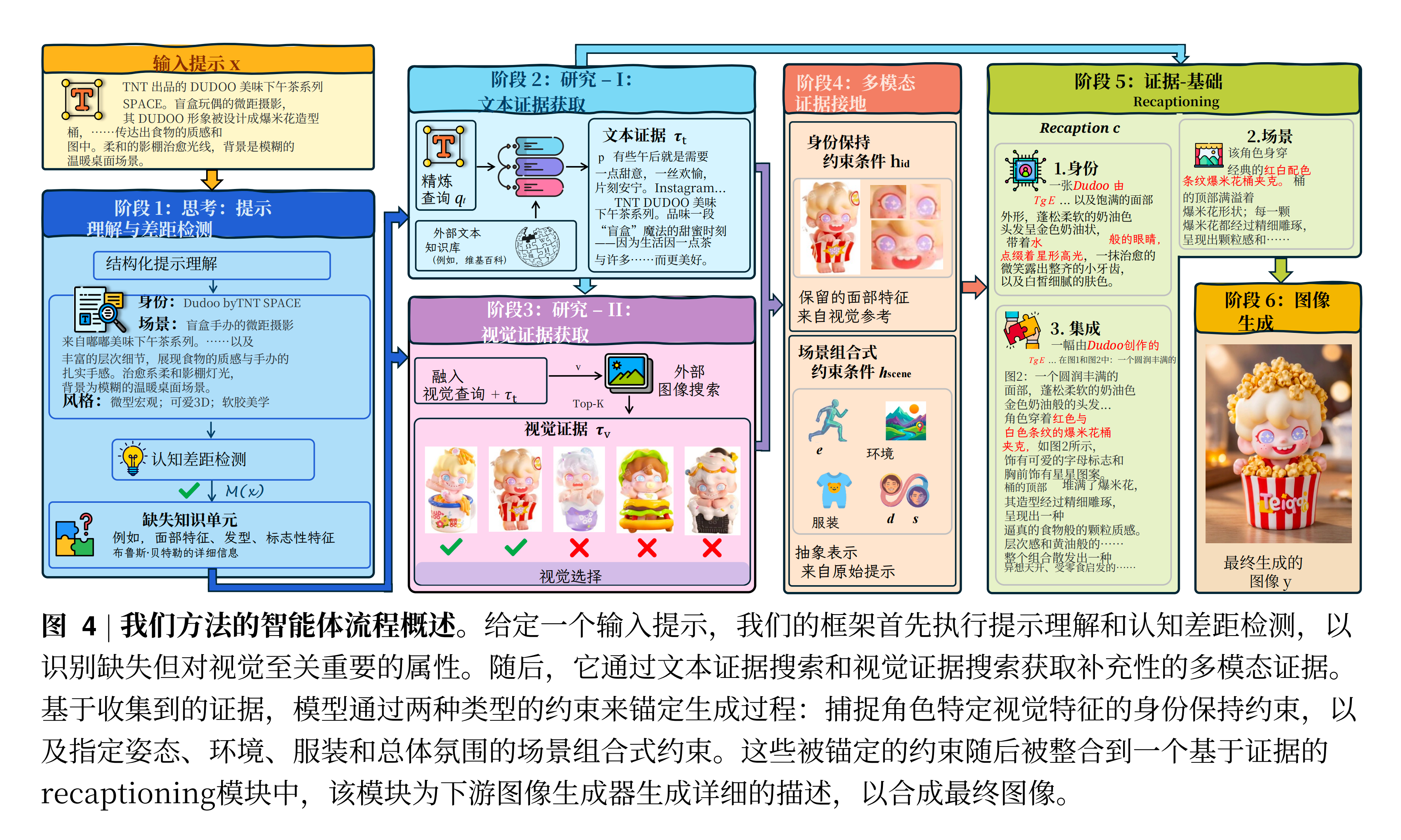
Unify-Agent 构建在ULM Bagel 之上,通过在原生层面整合认知缺口检测、证据获取和生成规划,摒弃了脆弱的 API 管道 。
Unify-Agent 将单步的文本到图像映射重构为在增强状态空间上的连续生成轨迹,包含四个紧密耦合的认知阶段:
-
THINK (认知缺口检测):模型首先解析输入的 Prompt,判断自身参数库中是否缺失实现该图像所需的视觉关键知识。如果存在缺口,则触发后续的外部搜索 。
-
RESEARCH (多模态证据获取):在判断需要外部知识后,模型主动与外部环境交互。为了提高精准度,这被设计为一个有序序列:
-
首先进行文本搜索,发出查询并获取文本证据 。文本提供了语义脚手架(消除歧义、确认背景)。
-
随后结合原始 Prompt 和文本上下文进行视觉搜索,获取具有高保真度的参考图像 作为视觉锚点 。
-
-
RECAPTION (基于证据的重写):这是连接“理解”与“生成”的桥梁。为了解决直接注入原始图片的模态冲突,模型提取两类约束:身份保留约束(从检索图像中提取出的不可变视觉特征)和场景构图约束(原始 Prompt 中要求的姿态、环境和风格)。这些约束被整合成一个高度结构化、面向生成描述词 。
Thinking
实际上感觉是因为原始的prompt 是基于 T2I 的,要重整为 I2I
-
GENERATE (视觉合成):最后的图像合成仅以重写后的文本 和选定的视觉锚点 为条件进行 。
- 注意力掩码机制 (Attention Masking):为了防止长序列中嘈杂的搜索历史和思维链(CoT)推理干扰图像的生成,作者设计了混合注意力掩码。在生成阶段,流匹配的 VAE 潜变量 token 被严格限制,只允许关注之前的重写(Recaption)文本 token 和检索到的视觉图像 token,彻底屏蔽掉了前序的搜索和推理文本
Thinking
因为采用的ULM,而不是组合模型
实验/评估/结果
-
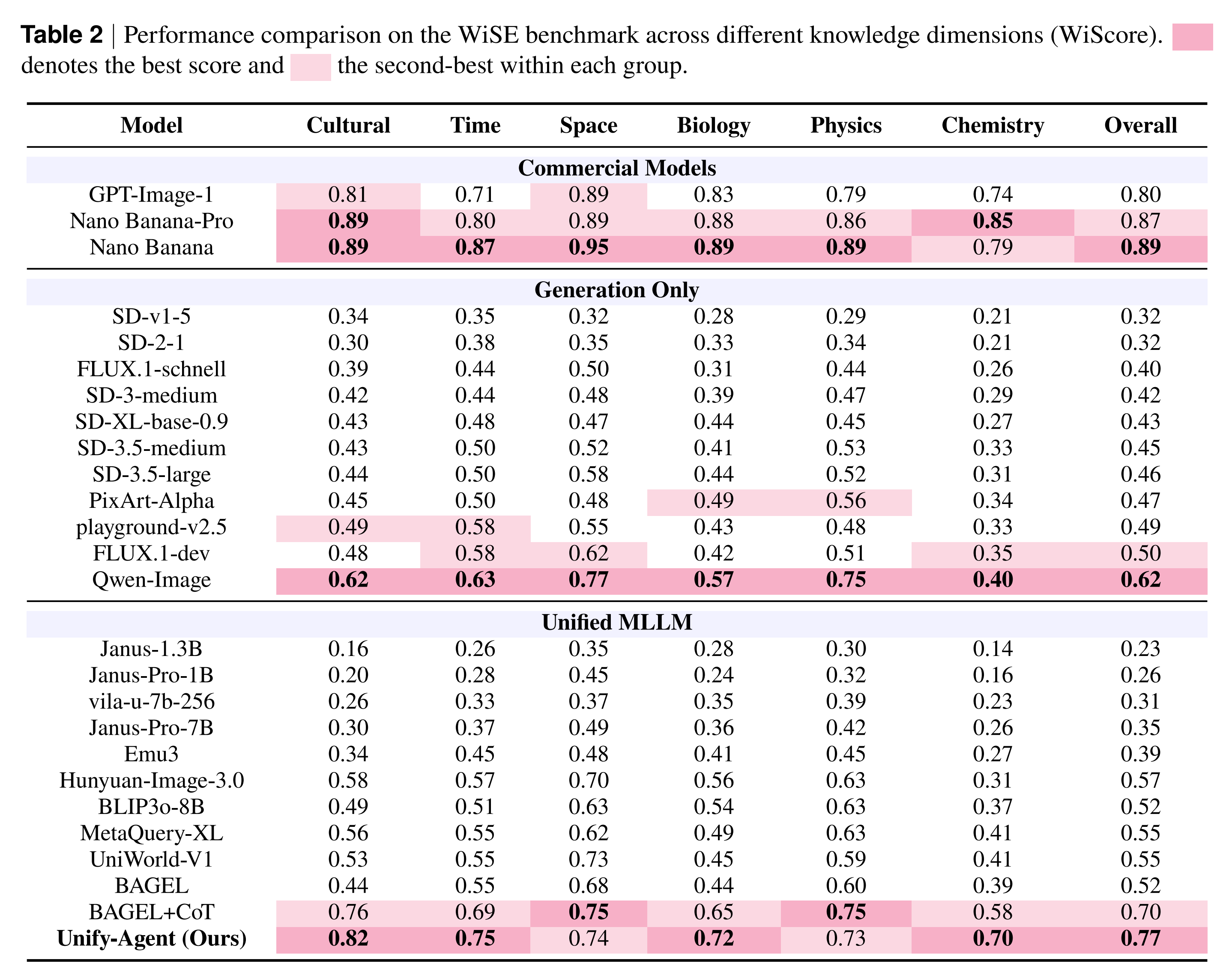
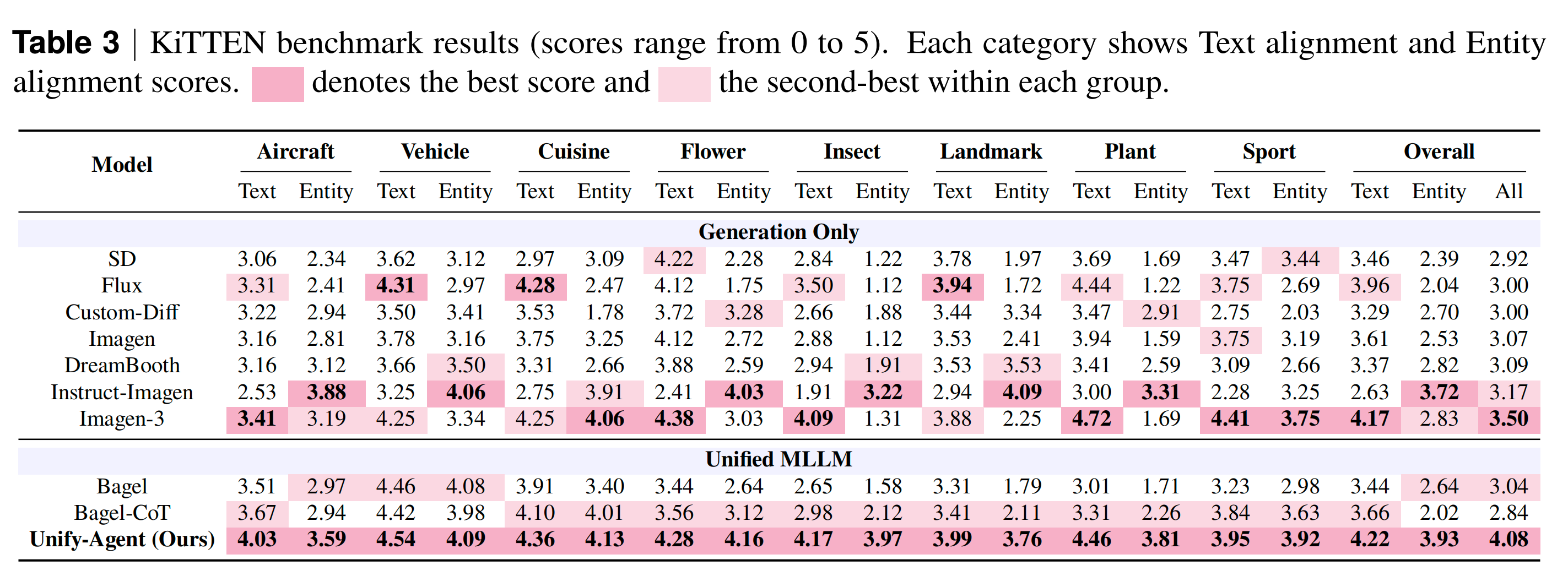
基准 (Benchmarks):除了提出的 FactIP 外,还评估了 WiSE、KITTEN 和 T2I-FactBench 。
-
基线对比:包括闭源商业大厂模型(DALLE-3、Seedream、Nano Banana 2)、开源专精生成模型(Flux.1-dev、SD-3.5-large)和开源 UMM(Janus-Pro、Emu3.5)。
-
评估方式:采用 MLLM-as-a-Judge 范式,使用 GPT-4o 和功能强大的 Seed 2.0 作为专家裁判,依据清晰度、内容、美学和相关性(即对 IP 的忠实度)进行打分
FactIP
WISE
KITTEN
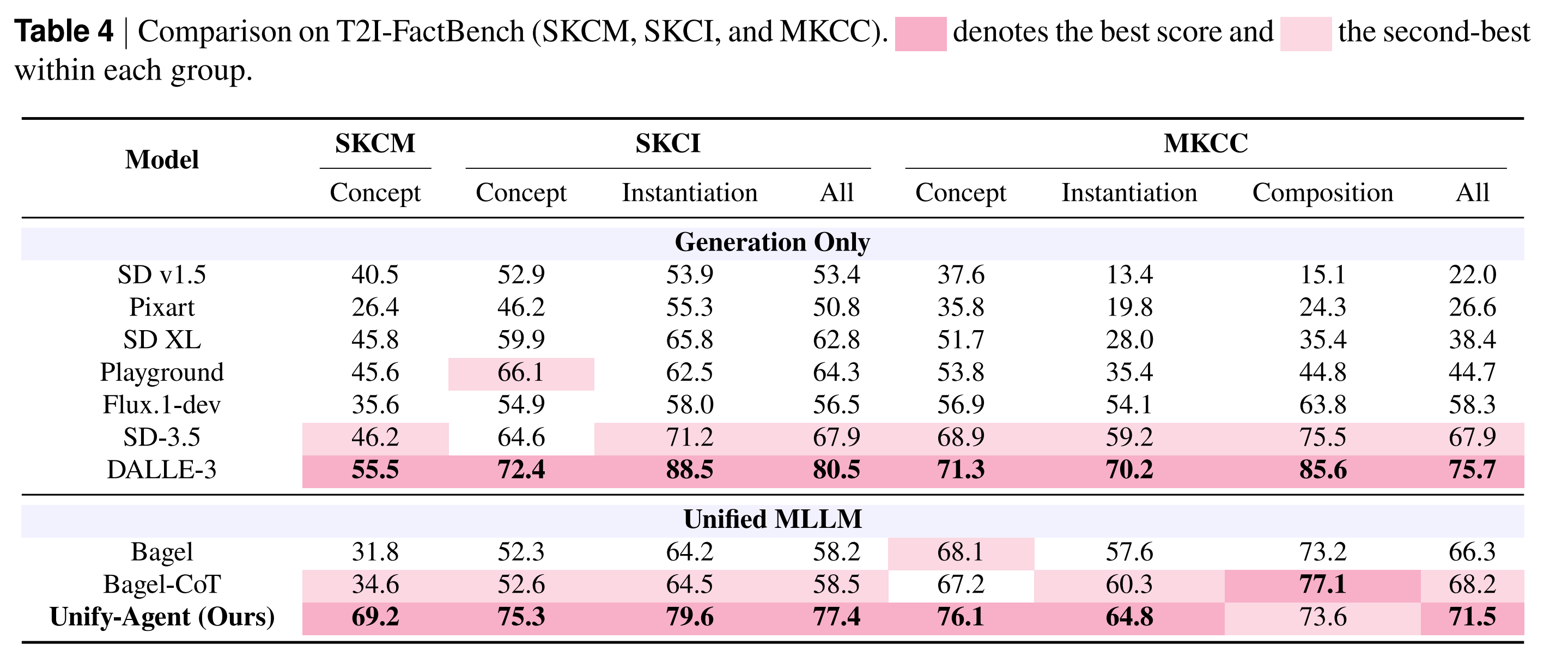
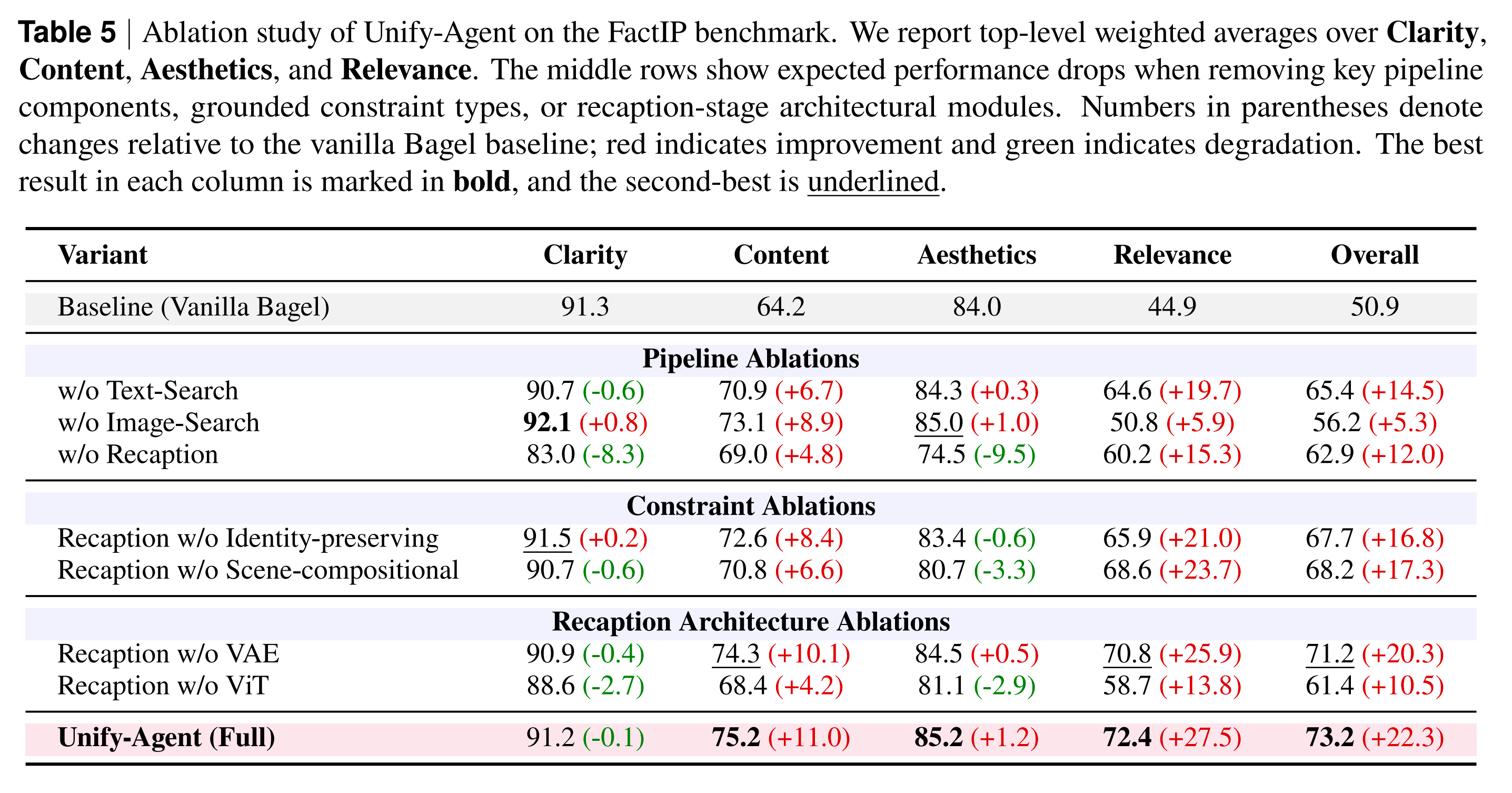
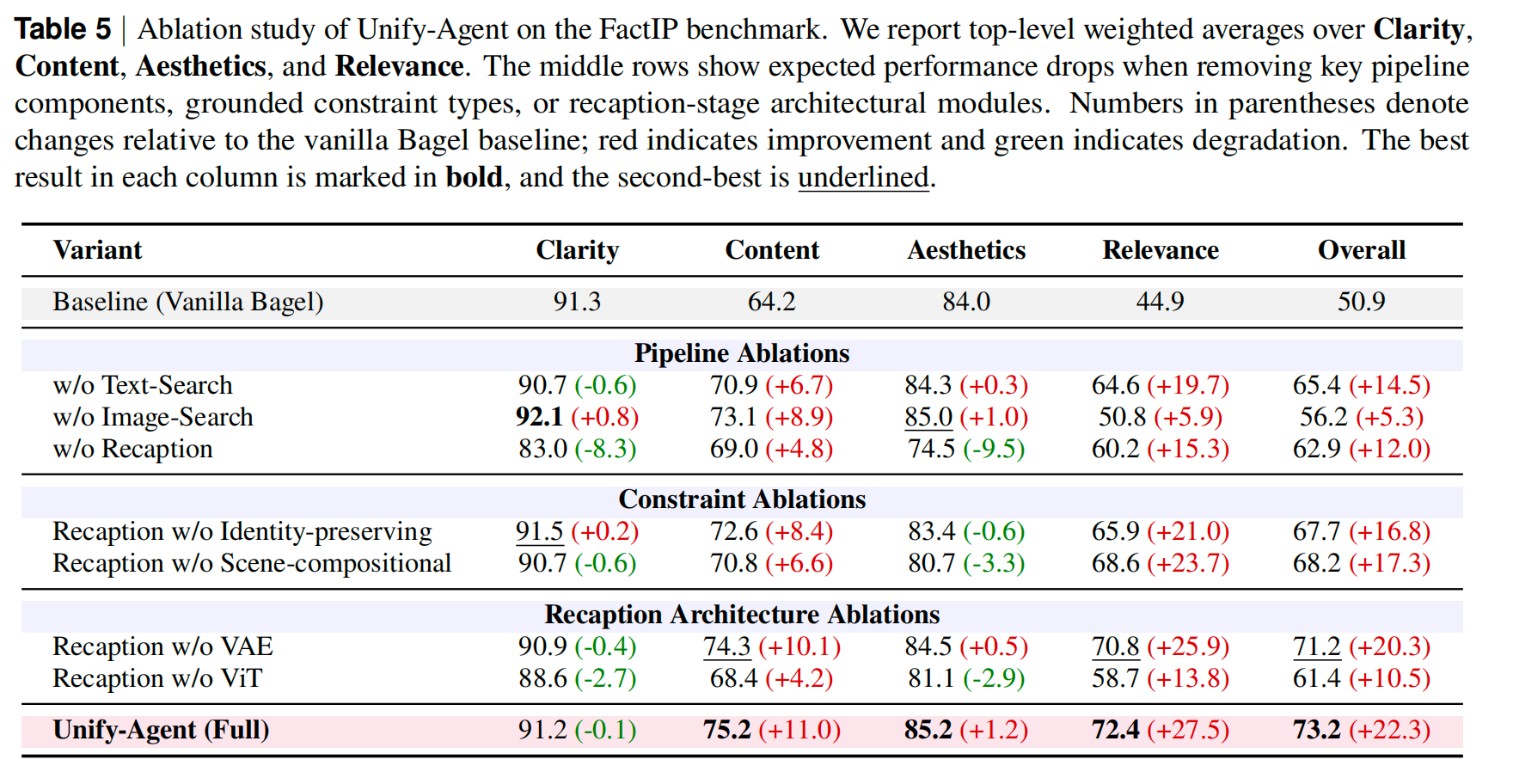
Ablation