提出了 Gen-Searcher,这是首个通过强化学习训练的搜索增强图像生成智能体,它能够执行多跳推理和网络检索,主动收集文本事实和视觉参考图,从而大幅提升知识密集型场景下的图像生成准确性 。
Intro
Motivation
仍然是静态参数模型无法处理长尾 ip 和新事件,此前的 Mind-Brush 是一个框架,没有训练模型的能力,提出一个自然的问题:能否训练一个用于图像生成的搜索智能体,使其主动执行多跳网络搜索和推理,从网络上收集知识,以实现接地的图像生成?
本文的解决方案与贡献:
-
构建了首个此类数据集:通过大模型(Gemini 3 Pro)协助,利用提示词工程和转换现有的 DeepResearch QA 数据集,构建了一套自动化数据闭环,提纯出 SFT 和 RL 需要的训练轨迹 Gen-Searcher-SFT-10k 和Gen-Searcher-RL-6k。
-
双重奖励反馈 (Dual Reward Feedback):在进行 GRPO 智能体强化学习时,作者敏锐地发现:纯图像生成的奖励噪音太大,因此创新性地加入了文本级别的信息覆盖率奖励,两者结合使得策略优化非常稳定 。
-
提出了综合基准测试 KnowGen:全面评估生成图像的客观对齐程度(视觉属性正确性与文本准确性),并开源了所有工具 。
Method
1. 数据集构建 (Data Pipeline)
高质量的“多跳搜索-图像生成”对齐数据在自然界是不存在的,必须自行构造 。流水线分为四个阶段:
-
Text Prompt Construction:使用 Gemini 3 Pro 撰写了涵盖 20 多个领域(天文、生物、动漫、游戏等)的强搜索需求 prompt,以及将现有深度研究 QA 问答集转化为图像生成任务 。
-
Agentic Trajectory Generation:赋予 Gemini 3 Pro 三个工具:
search(查文本内容)、image_search(查参考图特征)、browse(精读网页细节) 。让它像人类一样多轮交互,留下完整的试错、分析轨迹,最终吐出一个高度丰富且包含了“选定参考图”的 Grounded Prompt 。 -
Ground-Truth Image Synthesis:将上一步整理好的完善文本和参考图送入专有模型 Nano Banana Pro,合成出完美的 Ground Truth (GT) 图像(约 30K 原始样本) 。
-
Data Filtering:利用 Seed1.8 模型和规则引擎(查验文本清晰度、美学、安全性、事实正确性),最终洗出 17K 高质量数据,拆分为 SFT、RL 和测试集 。
2. KnowGen 基准测试及 K-Score
专门用于评估此任务,包含了 630 个极具挑战的真实世界用例,分为“Science & Knowledge”和“Pop Culture & News”两个宏观子集 。 采用 GPT-4.1 作为裁判评估 K-Score,
四个维度对生成结果进行评分:忠实度、视觉_正确性、文本_准确性和美学。
- 忠实度衡量生成的图像是否在场景结构层面遵循提示,包括所需的主体、关系、场景和要求的格式。
- 视觉正确性评估关键接地视觉属性相对于目标概念是否正确,并且与参考图像保持一致,例如主体外观、物体特征或其他外部可验证的视觉线索。
- 文本准确性衡量图像中任何提示要求的可读文本是否存在、是否清晰可辨且正确;当提示不要求可读文本时,此维度被视为不适用,不计入平均分数。
- 美学衡量生成图像的整体视觉质量和艺术吸引力,包括构图、色彩协调、光照等。此维度评估图像是否看起来视觉上精致且具有美学吸引力。
3. 训练方案 (Two-Stage Training)
使用 Qwen3-VL-8B-Instruct 作为基础大模型 。
-
Stage 1: 监督微调 (SFT):在 10k 数据上微调,教会模型最基础的工具调用语法,如何读反馈,如何组装出最后的 Grounded prompt 。
-
Stage 2: 智能体强化学习 (Agentic RL via GRPO):固定后端的 Qwen-Image 图像生成器不更新,仅训练前端的搜索大模型 。
-
核心痛点与双重奖励反馈:如果直接使用最终生成的图像质量来给模型发 Reward,训练会彻底崩溃。因为开源图像生成器(如 Qwen-Image)本身的生成方差太大了。即使搜索模型完美找出了正确的物理定理和参照图,Qwen-Image 在生成时也可能因为自身缺陷把图画崩,这会给搜索智能体传递一个“巨大的错误惩罚” 。
-
解决方案:引入文本奖励 。由 GPT-4.1 单独评估搜索智能体最后生成的 prompt 是否在逻辑和文本层面补齐了需要的信息 。最终的 Reward 设计为:
(实验中最佳均衡点 ) 。
-
使用 GRPO 算法
-
实验/评估/结果
硬件与实现:8 张 H800 用于训练智能体,外加 16 张 H800 部署 Qwen-Image-Edit-2509 用来在强化学习的 Rollout 阶段实时合成图像测算 Reward,另外还有 8 张卡部署 Qwen3-VL-30B 用于处理网页摘要提取
KnowGen
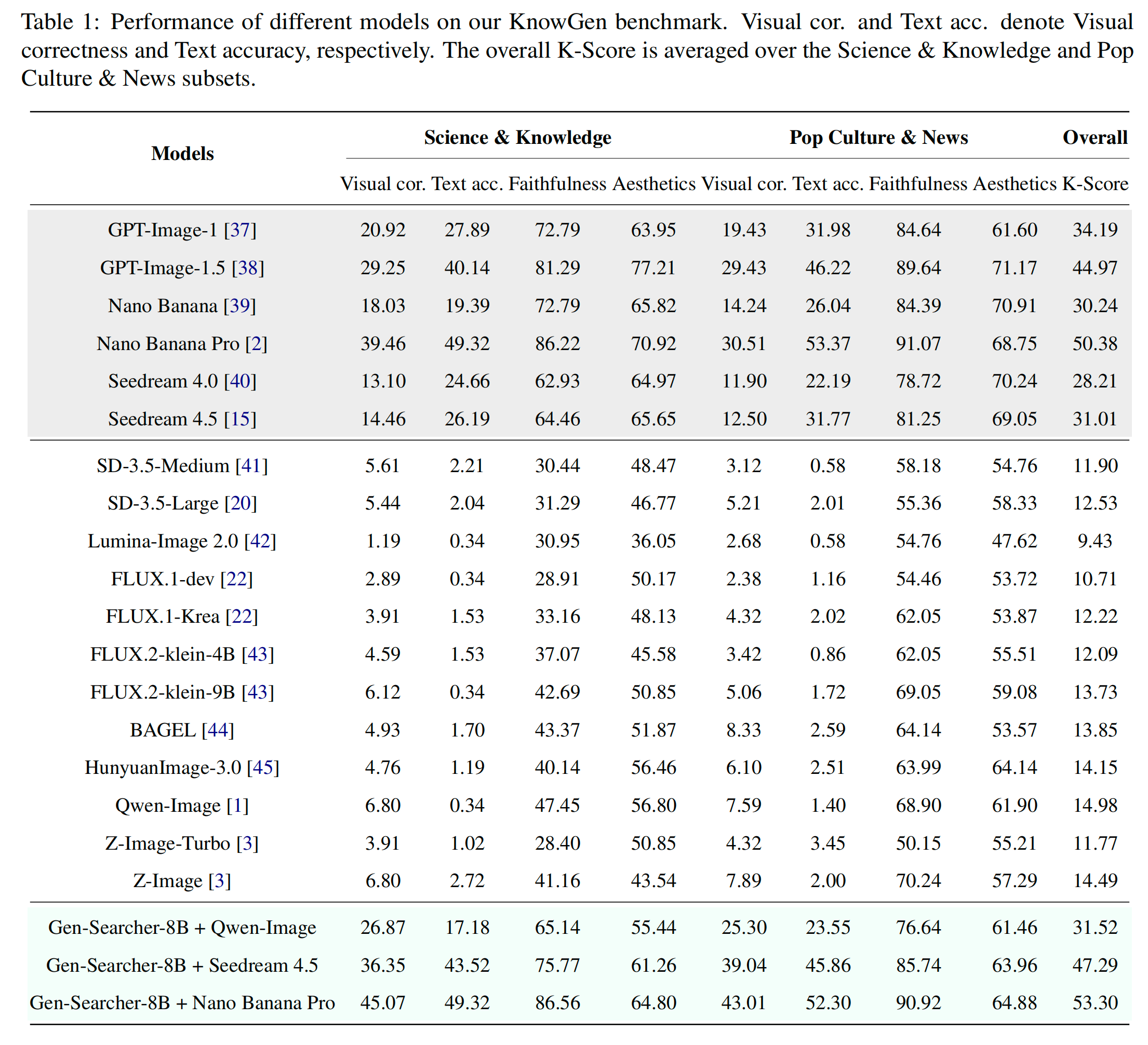 极强的插件级泛化性:这个搜索智能体并不是过拟合了 Qwen-Image,它是一个通用的“外脑”。将其作为前端直接给 Seedream 4.5 提供 Prompt,分数能从 31.01 提升到 47.29;甚至给自带搜索的 Nano Banana Pro 用,也能弥补其无法搜索视觉参考图的短板,将巅峰得分继续推高到 53.30 。
极强的插件级泛化性:这个搜索智能体并不是过拟合了 Qwen-Image,它是一个通用的“外脑”。将其作为前端直接给 Seedream 4.5 提供 Prompt,分数能从 31.01 提升到 47.29;甚至给自带搜索的 Nano Banana Pro 用,也能弥补其无法搜索视觉参考图的短板,将巅峰得分继续推高到 53.30 。
WISE
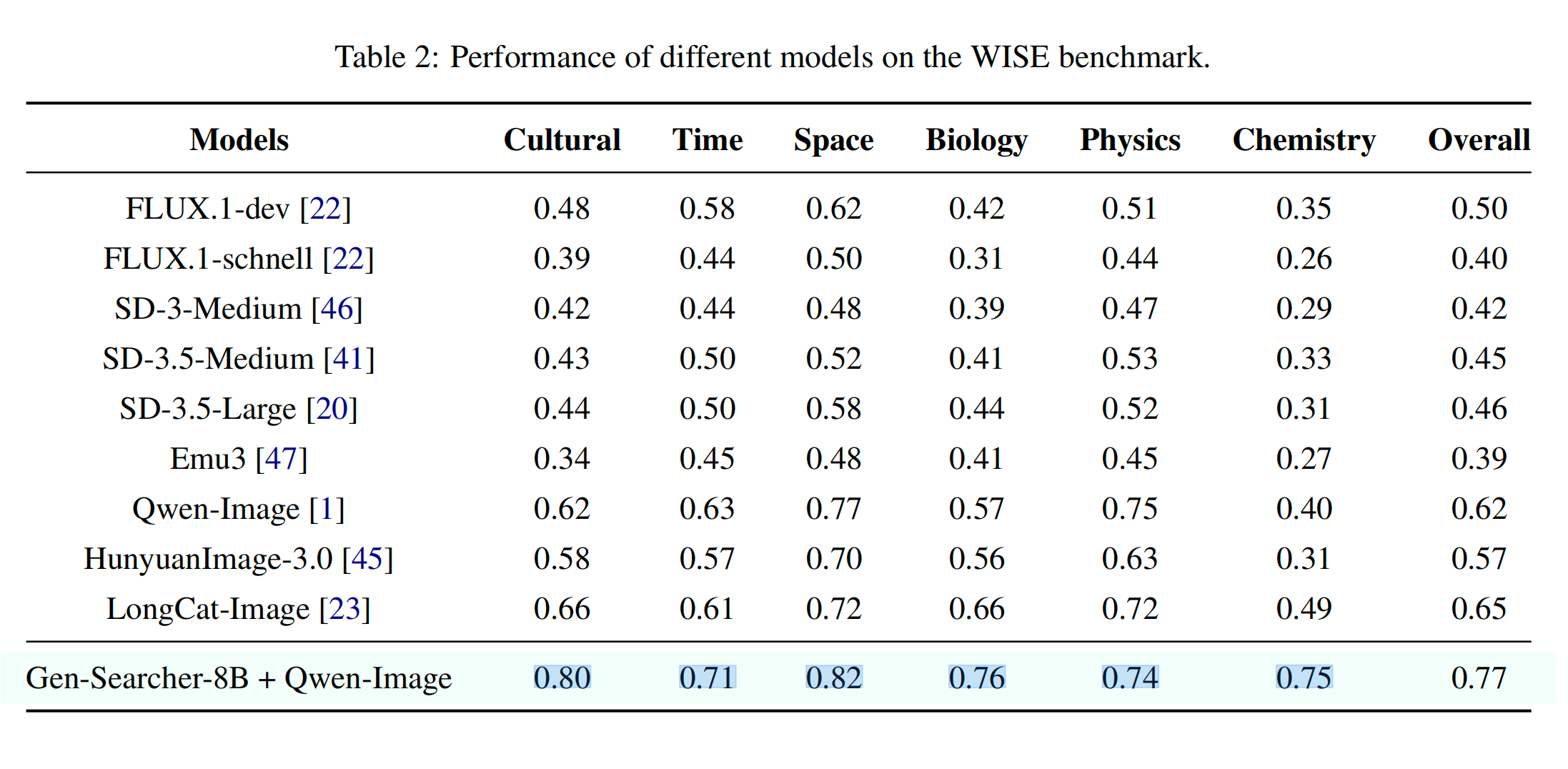
WISE
指向原始笔记的链接
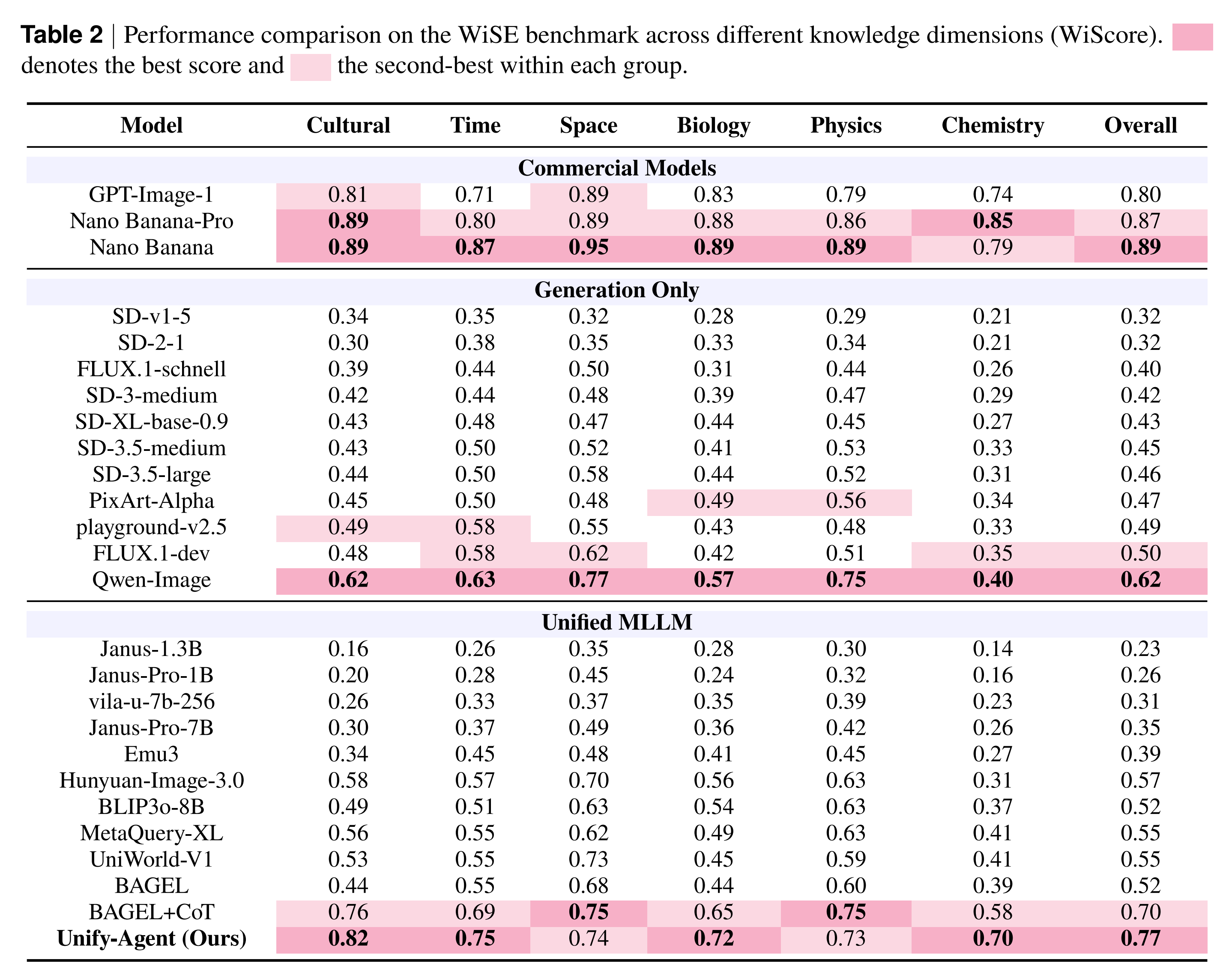
Transclude of Mind-Brush#wise
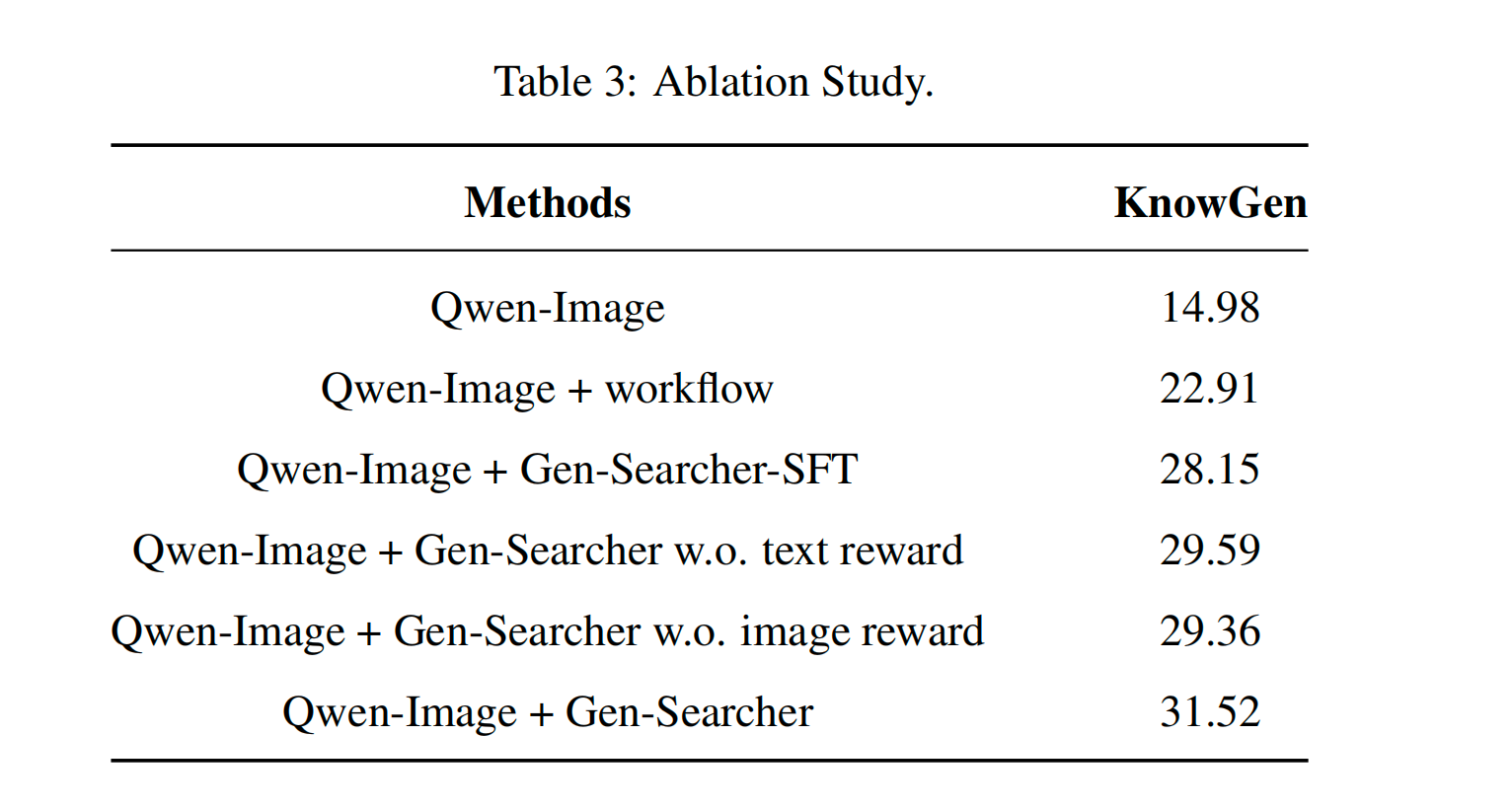 消融实验:清楚地证明了纯 SFT (28.15 分) 是不够的,引入 RL 有效;而在 RL 中去掉文本奖励或去掉图像奖励都会导致掉分,证明了双重反馈缺一不可 。
消融实验:清楚地证明了纯 SFT (28.15 分) 是不够的,引入 RL 有效;而在 RL 中去掉文本奖励或去掉图像奖励都会导致掉分,证明了双重反馈缺一不可 。
结论
作者成功提出并验证了 Gen-Searcher,这是第一个将 Agentic RL 引入图像生成“知识收集”阶段的深度多模态搜索智能体。配套的数据集构造流水线、KnowGen 评测基准以及双重奖励训练方案,有力地解决了当下文本到图像生成大模型“缺少外部动态知识且自身生成方差大导致强化学习困难”的痛点。这种将推理与生成解耦的架构展现了极强的泛化能力 。
思考
优点
- Reward Shaping 设计
- 数据飞轮:用极强闭源模型蒸馏产出数据,用规则大模型清洗数据,最后喂给小模型 RL