一句话总结:本文提出了 Rotary Position Embedding (RoPE),一种全新的位置编码方法——通过旋转矩阵编码绝对位置,同时在自注意力中自然引入相对位置依赖。RoPE 具有序列长度灵活性、随距离衰减的 token 间依赖、以及与线性自注意力兼容等优良特性,成为 LLaMA 系列等主流 LLM 的标准位置编码方案。
Intro
Motivation
位置信息对自然语言理解至关重要。现有位置编码方法分为两类:
- 绝对位置编码(Transformer 的正弦编码、BERT 的可学习 embedding):将位置信息加到 token 表示上
- 相对位置编码(Transformer-XL、T5):在注意力计算中编码相对位置
但现有方法存在根本性局限:它们都是通过”将位置信息加到上下文表示中”来实现的,这使得它们与线性自注意力架构不兼容(线性注意力需要位置编码通过乘法操作融入表示)。
贡献
- 提出 RoPE:通过旋转矩阵将绝对位置编码乘性融入 token 表示,在注意力点积中自然产生相对位置依赖
- 理论性质分析:证明 RoPE 具有随相对距离衰减的依赖(这对语言建模至关重要)和长序列外推能力
- RoFormer 模型:验证了 RoPE 在长文本分类任务上的有效性
- 与线性自注意力的兼容性:RoPE 是目前唯一能与线性自注意力架构兼容的相对位置编码方案
Method 核心方法
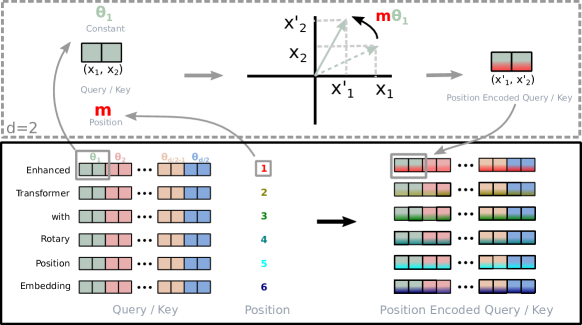
Figure 1: Rotary Position Embedding(RoPE)的实现示意图。通过旋转矩阵将位置信息乘性地融入 query 和 key 表示。
核心思想
RoPE 的数学基础:将 d 维空间的 token 向量划分为 d/2 个 2 维子空间,对每个子空间根据其位置 m 施加一个旋转角度为 m*theta_i 的旋转矩阵。
形式化表示:
对于位置 m,RoPE 对查询 q 和键 k 的操作是:
其中 R_m 是对角分块的旋转矩阵,每个 2x2 块为:
其中 theta_i = 10000^{-2i/d}, i = 0, 1, …, d/2 - 1。
相对位置的自然导出
当计算注意力分数 q_m^T k_n 时:
由于旋转矩阵的正交性(R_m^T R_n = R_{n-m}),点积结果仅依赖于相对位置 (n-m),而非绝对位置 m 和 n。
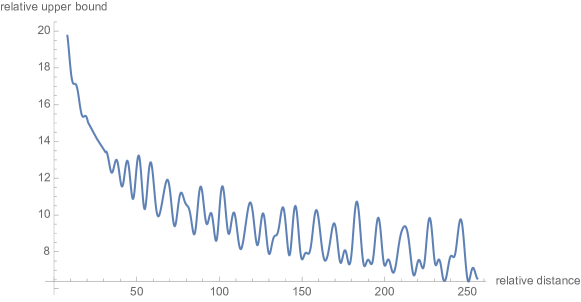
Figure 2: RoPE 的远程衰减性。注意力权重随相对距离增大而自然衰减,模拟了”近处词更相关”的语言学特性。
关键性质与设计原理
| 性质 | 机制 | 意义 |
|---|---|---|
| 相对位置自然依赖 | 点积 仅含 (n-m),无需额外计算 | 比 Transformer-XL 的显式相对编码更简洁 |
| 远程衰减 | $ | n-m |
| 序列长度灵活 | 可外推到训练未见长度(只需修改频率 θ) | LLaMA 系列支持的上下文扩展直接受益 |
| 线性注意力兼容 | 位置信息通过乘性(旋转)融入,非加性 | 唯一与线性/稀疏注意力架构兼容的相对位置编码 |
与现有方法的对比
| 方法 | 类型 | 乘法/加法 | 相对位置 | 线性注意力兼容 |
|---|---|---|---|---|
| 正弦编码(Transformer) | 绝对 | 加法 | - | - |
| 可学习 embedding(BERT) | 绝对 | 加法 | - | - |
| Transformer-XL 相对编码 | 相对 | 加法 | + | - |
| T5 bias | 相对 | 加法 | + | - |
| RoPE | 绝对+相对 | 乘法(旋转) | + | + |
实验/评估/结果
长文本分类
在多个中文长文本分类数据集上,RoFormer 对比多种基准:
- RoFormer 在所有评估数据集上一致优于基线方法
- 在超长文本(>500 tokens)上的优势尤为明显
预训练语言模型
部分实验在预训练语言模型上进行,代码和 checkpoint 发布在 GitHub。RoFormer 已正式集成到 HuggingFace Transformers 库中。
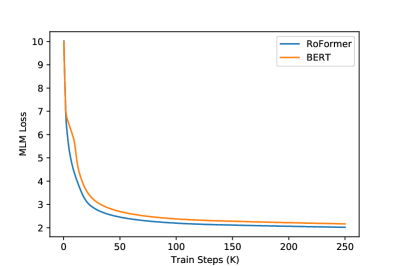
Figure 3: 语言建模预训练中 RoPE 的效果评估。(左)BERT 和 RoFormer 的训练 loss,RoFormer 收敛更快;(右)PerFormer 使用/不使用 RoPE 的训练 loss,RoPE 带来更快收敛和更低 loss。
结论
RoPE 通过旋转矩阵实现了位置信息的乘性编码,在自注意力中自然引入相对位置依赖。它兼具绝对位置编码的简洁性和相对位置编码的表达力,序列长度灵活性、远程衰减性和线性注意力兼容性使其成为位置编码领域的重大突破。RoPE 后来被 LLaMA 系列等主流 LLM 广泛采用,证明了其在实际大规模预训练中的有效性。
思考
优点
-
数学优雅性:RoPE 的设计极其优雅——用简单的 2D 旋转实现位置编码,通过矩阵正交性自然导出相对位置依赖。这是典型的”数学上正确、工程上可用”的研究。
-
乘法 vs 加法的范式突破:此前几乎所有的位置编码方案都是通过”加”到 token 表示中的(绝对位置编码加到 embedding 上,相对位置编码加到注意力分数上)。RoPE 是第一个成功的”乘性”位置编码,通过旋转将位置信息融入 query 和 key。
-
线性注意力的前瞻性:在 2021 年就论证了 RoPE 与线性自注意力的兼容性。如今随着长上下文 LLM 对效率的要求越来越高,线性注意力的重要性在持续增长,RoPE 的前瞻性更加凸显。
-
实际影响力的广度:LLaMA、LLaMA-2、LLaMA-3、Mistral、Qwen、ChatGLM 等几乎所有主流开源 LLM 都使用 RoPE。这种行业范围内的采用是对其价值的最好证明。
缺点与局限
-
实验范围较小:本文仅在长文本分类任务上做了实验,没有在大规模预训练语言模型(如 BERT 规模)上验证 RoPE 的效果。RoPE 在大规模预训练中的优势,更多是被后来的 LLaMA 等模型侧面验证的,而不是原论文直接证明的。
-
理论基础可进一步深入:论文使用了”远程衰减性”作为 RoPE 的理论优势,但这个性质是否严格对应语言建模的最优行为,并没有深入的理论分析。
-
与线性注意力结合的实践效果:虽然理论上兼容,但 RoPE + 线性注意力的实际效果在当时未经过大规模验证。
与已有 Wiki 的连接
- 关联概念:位置编码(Positional Encoding)、RoPE(旋转位置编码)、线性自注意力、相对位置编码
- 关联论文:Transformer(正弦位置编码的原作)、LLaMA(第一个大规模使用 RoPE 的 LLM)
- 关联比较:RoPE vs ALiBi(另一种主流位置编码方案,MosaicML/MPT 使用)
- 关联实体:RoPE