一句话总结:本文提出了 LLaMA,一系列仅使用公开数据训练的 7B-65B 开源大语言模型,其中 LLaMA-13B 超越了 GPT-3(175B),LLaMA-65B 与 Chinchilla-70B 和 PaLM-540B 竞争,证明了在”少数据但高质量”的 Chinchilla 最优路线下,用公开数据也能训练出顶尖的 LLM。
Intro
Motivation
在大语言模型的时代,GPT-3(175B)、Gopher(280B)、PaLM(540B)等闭源模型统治了领域。这些模型有两个共同问题:
- 不公开:权重、训练数据、架构细节不透明,社区无法复现和研究
- 训练数据包含私有的非公开数据:无法保证 reproducibility
LLaMA 的目标是:仅用公开数据(CommonCrawl、Wikipedia 等),在 Chinchilla 缩放定律指导下,训练出能匹敌甚至超越闭源模型的开源语言模型。
核心设计哲学
与”大模型+少数据”(GPT-3)相反,LLaMA 遵循 Chinchilla 的”计算最优”原则:在给定算力预算下,用更多数据训练较小模型。LLaMA-7B 训练了 1T tokens,所有模型都在 1T-1.4T tokens 规模上训练——这在当时远超大多数同规模模型的数据量。
贡献
- LLaMA 系列模型:7B、13B、33B、65B 四个规模,全部开源
- 仅用公开数据:证明了不需要私有数据即可达到顶尖性能
- 13B 超越 GPT-3 175B:参数少 10 倍以上仍更强,验证了 Chinchilla 规律
- 引入 SOTA 架构改进:Pre-normalization(RMSNorm)、SwiGLU、Rotary Embeddings(RoPE)
Method 核心方法
1. 架构设计
LLaMA 基于标准 Transformer decoder,集成了三项关键改进(均来自已有工作的最佳实践,LLaMA 的贡献在于系统地组合它们):
| 选择 | 说明 | 对比标准 Transformer |
|---|---|---|
| Pre-norm (RMSNorm) | LN 放子层前 | Post-norm 在大模型中训练不稳定 |
| SwiGLU | 替代 ReLU | PaLM 证明 FFN 中用门控激活提升质量 |
| RoPE | 替代绝对/可学习位置编码 | 更好的长度外推 + 相对位置感知 |
自回归公式:。
各模型规格(训练 token 数远超 Chinchilla 建议的等比例缩放——LLaMA 的策略是”用小模型+大数据”追求推理效率):
| 模型 | 参数量 | 层数 | d_model | 头数 | 训练 tokens | 训练时长 |
|---|---|---|---|---|---|---|
| LLaMA-7B | 6.7B | 32 | 4,096 | 32 | 1.0T | 82K GPU-h |
| LLaMA-13B | 13.0B | 40 | 5,120 | 40 | 1.0T | 135K GPU-h |
| LLaMA-33B | 32.5B | 60 | 6,656 | 52 | 1.4T | 530K GPU-h |
| LLaMA-65B | 65.2B | 80 | 8,192 | 64 | 1.4T | 1,022K GPU-h |
2. 训练数据
全部来自公开来源,总规模约 1.4T tokens:
| 数据集 | 占比 | 规模 | 说明 |
|---|---|---|---|
| CommonCrawl | 67.0% | ~3.3TB | 去重(CCNet 流水线)、语言识别过滤 |
| C4 | 15.0% | ~750GB | CommonCrawl 的清洗版本 |
| GitHub | 4.5% | ~328GB | Apache/BSD/MIT 许可证下的代码 |
| Wikipedia | 4.5% | ~83GB | 多语言 Wikipedia |
| Books | 4.5% | ~85GB | Gutenberg + Books3 |
| ArXiv | 2.5% | ~92GB | 学术论文 |
| StackExchange | 2.0% | ~78GB | 高质量的问答语料 |
数据处理:整体 tokenization 使用 SentencePiece(BPE),数字通过 split digit 方式处理。
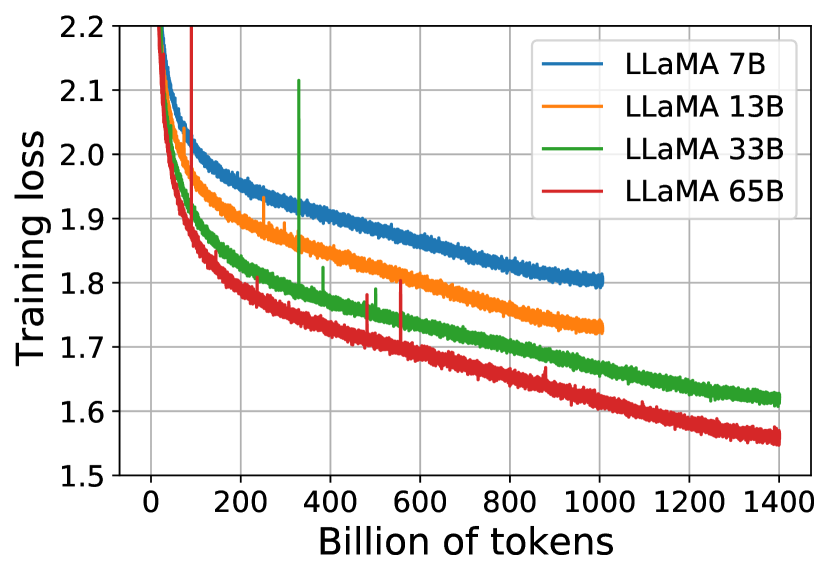
Figure 1: 7B、13B、33B、65B 模型的训练 loss 随训练 token 数的变化。所有模型平滑收敛,展现出良好的训练稳定性。
3. 训练细节
- 优化器:AdamW(b1=0.9, b2=0.95)
- 学习率调度:cosine schedule,Linear warmup
- 权重衰减:0.1
- 梯度裁剪:1.0
- 硬件:A100-80GB GPU,训练时长约 5 个月(开发 + 最终训练),使用了 2048 GPU
- 内存优化:手动实现反向传播,减少 checkpointing 的 activations(尤其对注意力层)
- 多 GPU 并行:模型并行 + 序列并行(减少内存占用)
4. Instruction Fine-tuning
LLaMA 在少量指令数据上的微调(LLaMA-I)在 MMLU 上达到 68.9%,超越 Flan-PaLM(66.1%)、OPT-IML-Max(43.2%)等专用指令微调模型。
实验/评估/结果
常识推理
在 8 个常识推理基准(BoolQ、PIQA、SIQA、HellaSwag、WinoGrande、ARC-e、ARC-c、OBQA)上:
- LLaMA-65B 在大多数 benchmark 上超越或持平 Chinchilla-70B 和 PaLM-540B
- LLaMA-13B 在这 8 个 benchmark 上全面超越 GPT-3 175B
- 所有模型性能随规模增长持续提升,符合 scaling law
MMLU(5-shot)
| 模型 | MMLU | 模型 | MMLU |
|---|---|---|---|
| GPT-3 175B | 43.9 | PaLM-540B | ~57 |
| Gopher 280B | 60.0 | Chinchilla 70B | 67.5 |
| LLaMA-7B | 35.1 | LLaMA-33B | 57.8 |
| LLaMA-13B | 46.9 | LLaMA-65B | 63.4 |
LLaMA-65B(63.4%)接近 Chinchilla-70B(67.5%),远高于 GPT-3(43.9%)。
闭卷问答
Natural Questions 和 TriviaQA:
- LLaMA-65B 在 zero-shot 和 few-shot 设定下均达到或接近 SOTA
- LLaMA-33B 已超越 GPT-3 175B
阅读理解(RACE)
- LLaMA-65B 在 RACE-middle 和 RACE-high 上均超越 PaLM-540B
数学推理(MATH、GSM8k)
- LLaMA-65B 在 MATH 和 GSM8k 上展现出良好的数学推理能力
- 但仍弱于专门微调的 Minerva
代码生成(HumanEval、MBPP)
- LLaMA 系列在 HumanEval 和 MBPP 上持续提升,LLaMA-65B 达到当时开源模型最佳水平
偏置与毒性评估
- RealToxicityPrompts:毒性随模型规模略微增加(65B 在 basic 上 0.128),但总体与 Chinchilla 相当
- CrowS-Pairs:bias 整体评分优于 GPT-3 和 OPT,但宗教类 bias 明显偏高(79.0 vs GPT-3 73.3)
- WinoGender:对 “their/them/someone” 的共指消解准确率(81.7%)明显高于 “his/him/he”(72.1%)和 “her/her/she”(78.8%),表明存在性别偏见
- TruthfulQA:LLaMA-65B 在 truthful 维度上 57%,显著优于 GPT-3 175B(28%),但在绝对水平上仍较低
训练性能追踪
训练过程中 benchmark 性能持续平滑提升,与训练困惑度强相关。例外是 SIQA(方差大,可能说明该 benchmark 不可靠)和 WinoGrande(33B 和 65B 性能接近)。

Figure 2: 训练过程中问答和常识推理的性能演变。随着训练进行,各类 benchmark 性能持续平滑提升。
结论
LLaMA 证明了在 Chinchilla 计算最优范式下,仅用公开数据也能训练出匹敌闭源大模型的开源 LLM。LLaMA-13B 超越 GPT-3 175B 的结果尤其有力地说明了:在给定的计算预算内,更多的高质量数据比更大的参数量更重要。架构方面的选择(RMSNorm、SwiGLU、RoPE)也成为后续开源 LLM 的标准配置。
思考
优点
-
开源精神的里程碑:LLaMA 是第一个真正能与 GPT-3、Chinchilla、PaLM 等闭源模型竞争的开源 LLM,极大推动了开源 LLM 生态的爆发。
-
Chinchilla 定律的最佳实证:LLaMA-13B > GPT-3 175B(9 倍的参数差距,13 倍的参数效率),是 Chinchilla 缩放定律最有力的”side-by-side”验证。
-
架构选择的教科书级融合:RMSNorm + SwiGLU + RoPE 的组合成为后续几乎所有开源 LLM(Alpaca、Vicuna、Mistral 等)的标准配置。
-
仅用公开数据:这一点在方法论上很重要——它证明了 LLM 的能力不来自私有”魔法数据”,而是来自正确的缩放策略和数据处理。
缺点与局限
-
训练数据细节不充分:论文对 CommonCrawl 的过滤方法的描述比较简略,没有像 GPT-3 那样提供详细的数据处理 pipeline。
-
生成可控性未讨论:论文主要关注 benchmark 评估,对各种生成任务的可控性和质量评估不足。
-
安全性讨论浅尝辄止:在 RealToxicityPrompts、WinoGender 上发现了明显的 bias 问题,但没有提出实质性的缓解策略。
-
多语言的局限性:虽然训练数据包含多语言(Wikipedia 多语言),但评估 focus 在英文任务上,对中文等其他语言的能力了解有限。
与已有 Wiki 的连接
- 关联概念:Chinchilla 缩放定律、RoPE(Rotary Position Embedding)、RMSNorm、SwiGLU
- 关联论文:Chinchilla 缩放定律(LLaMA 的计算最优训练理念来源)、RoPE(LLaMA 使用的位置编码)、Llama 3(LLaMA 系列的重要后续)
- 关联实体:LLaMA
- 后续演进:LLaMA → LLaMA-2 → LLaMA-3,成为开源 LLM 的旗舰系列