一句话总结:本文提出了 InstructGPT,通过人类反馈强化学习(RLHF)让语言模型更好地遵循用户指令,结果是 1.3B 的 InstructGPT 在人类评估中被偏好于 175B 的 GPT-3,同时降低了有害输出并减缓了”对齐税”(alignment tax)。
Intro
Motivation
GPT-3 虽然通过 few-shot prompting 展现了强大能力,但它的训练目标(预测下一个 token)与用户目标(“安全地、有帮助地遵循指令”)存在根本性的不一致(misalignment)。这导致了:
- 指令遵循能力弱:模型倾向于输出自认为”合理的续写”,而非真正完成用户请求
- 不安全输出:可能生成有害、偏见或虚假内容
- 用户需要精心设计 prompt:普通用户难以有效使用
贡献
- 提出 RLHF 方法论:系统性地展示了”收集人类偏好数据 → 训练奖励模型 → PPO 强化学习优化”的三步流程
- 1.3B InstructGPT 优于 175B GPT-3:证明了 alignment 比 raw scale 更影响用户感受
- 降低有害输出:在 truthfulness(TruthfulQA)和 toxicity(RealToxicityPrompts)上均有显著改善
- “对齐税”可控:公开 NLP benchmark 上的性能回退(alignment tax)较小,可通过 PPO-ptx 变体缓解
Method 核心方法
整体流程
RLHF 包含三个递进步骤,形成数据飞轮:
| 步骤 | 目标 | 数据 | 产出 |
|---|---|---|---|
| SFT | 让模型学会遵循指令格式 | ~13K (prompt, 人工回答) 对 | SFT 模型 |
| RM | 学习人类偏好函数 | ~33K prompt × (K=4-9 回答的排序) | 标量 RM |
| PPO | 最大化 RM 奖励+保持能力 | ~31K prompts(API 真实用户) | InstructGPT |
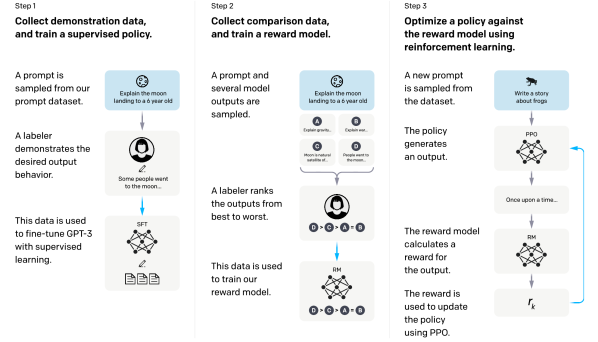
Figure 2: InstructGPT 三步骤:(1) SFT – 收集标注者示范数据微调 GPT-3;(2) RM – 标注者对模型输出排序训练奖励模型;(3) PPO – 用 RM 作为奖励函数通过 PPO 优化策略。
Step 1: Supervised Fine-Tuning (SFT)
- 数据:约 13K 个 (prompt, answer) 对,由 40 个 contractor labeler 撰写
- Prompt 来源:OpenAI API 用户提交的真实 prompt + labeler 撰写的多样性 prompt
- 训练:在 GPT-3 基础上进行有监督微调,得到 SFT 模型
Step 2: Reward Model Training
- 数据:每个 prompt 由 SFT 模型采样 K 个回答(K 通常在 4-9 之间),labeler 对 K 个回答进行排序
- 共收集约 33K 个 prompt 对应的排序数据
- RM 架构:GPT-3 的 6B 版本(移除最后的 unembedding 层,输出标量奖励值)
- 损失函数:pairwise ranking loss(基于排序的交叉熵)
Step 3: PPO 强化学习
- 环境:每次 RL step,随机采样 prompt → 当前策略生成回答 → RM 计算奖励
- 目标函数:
其中:
- 第一项:RM 给出的奖励
- 第二项(KL 惩罚):防止策略偏离 SFT 模型太远
- 第三项(pretraining loss,PPO-ptx 变体):缓解对齐税,保持 NLP 能力
数据
| 步骤 | 数据量 | 数据来源 |
|---|---|---|
| SFT | ~13K prompts | OpenAI API + labeler 撰写 |
| RM | ~33K prompts 的排序 | SFT 模型生成 + labeler 排序 |
| PPO | ~31K prompts | OpenAI API(仅训练期间收集) |
实验/评估/结果
人类偏好评估(核心结果)

Figure 1: 各模型在 API prompt 分布上的人类评估结果,显示各模型输出在多大程度上被偏好于 175B SFT 模型的输出。1.3B 的 InstructGPT(PPO-ptx) 的输出显著优于 175B GPT-3。
- 1.3B InstructGPT 被显著偏好于 175B GPT-3:在 85% 以上的比较中胜出
- 175B InstructGPT 更优,显著领先 175B GPT-3 和 1.3B InstructGPT
- InstructGPT 相比 SFT 模型也有明显偏好优势,证明了 RLHF 带来的增益
真实性(Truthfulness)

Figure 6: TruthfulQA 数据集上的结果。灰色柱表示真实性评分,彩色柱表示真实性和信息量的综合评分。InstructGPT 在真实性上显著优于 GPT-3。
- TruthfulQA 基准:InstructGPT 的真实性显著优于 GPT-3
- 使用 PPO-ptx 的版本在 truthfulness 上也优于纯 PPO
有害性(Toxicity)
- RealToxicityPrompts 基准:InstructGPT 在所有规模下都大幅减少了有毒输出
- 对”安全”prompt(非恶意输入),InstructGPT 的有害输出率接近零
- 对恶意设计的 prompt,InstructGPT 比 GPT-3 产生了更少的有害内容
对齐税(Alignment Tax)
对齐税指的是对齐训练后在公开 NLP benchmark 上的性能退步:
- 纯 PPO 在部分 NLP 任务上有明显退步(尤其小数据集)
- PPO-ptx(混合预训练 loss)显著缓解了对齐税,在大多数 benchmark 上与 GPT-3 持平或接近
- 总体结论:对齐税的代价可控
泛化性
- InstructGPT 对训练期间未见的”held-out” labeler 也表现出更好的指令遵循能力
- 对不同类型 prompt(创造性写作、事实问答、编程等)都有改善
负结果与局限
- 模型可能对简单指令过度优化,忽略一些细微要求
- 改善不一定对全体用户平等(labeler 偏好不代表所有用户的偏好)
- RLHF 训练可能导致模型在某些维度上过拟合奖励模型
结论
InstructGPT 证明了通过人类反馈进行对齐训练(RLHF)是一种有效的方法论:它让语言模型更好地遵循用户意图,输出更真实、更安全的内容,且性能代价可控。这项工作也成为 ChatGPT 的技术基础——ChatGPT 本质上是 InstructGPT 的一个应用实例。
思考
优点
-
开创 RLHF 范式:InstructGPT 系统性地定义并验证了 RLHF 的三步流程(SFT → RM → PPO),这不仅成为 OpenAI 后续模型(GPT-4、ChatGPT)的核心方法,也被几乎所有大模型团队(Anthropic、Google、Meta)采用。
-
“小对齐模型 > 大原始模型”的核心洞察:1.3B InstructGPT > 175B GPT-3 的结论极其有力——它证明了 alignment 比 raw scale 更直接影响用户体验。这重塑了社区对”什么才是好模型”的理解。
-
工程细节的坦诚:KL 惩罚系数、PPO-ptx 的讨论、对齐税的分析——这些工程问题在论文中有实际讨论,而非一味报喜。
-
泛化性分析:使用 held-out labeler 的测试表明 RLHF 学到的不只是迎合特定标注者,而是更泛化的”有用性/安全性”概念。
缺点与局限
-
奖励模型的上限:整个 RLHF 流程的质量被 RM 的能力严格限制。如果 RM 在某些维度上有偏见或不够准确,PPO 优化会放大这些缺陷。
-
“对齐”定义的模糊性:什么是对齐?paper 用 labeler 偏好作为 proxy,但 labeler 偏好只是真实用户偏好的一种近似。文化、任务、场景差异使得”好”的定义并不唯一。
-
安全性的不完整性:TruthfulQA 和 RealToxicityPrompts 只覆盖了安全性的一小部分维度。模型依然可能生成有说服力但错误的内容(hallucination),这是 InstructGPT 没有系统解决的。
-
训练成本:RLHF 需要大量人类标注(SFT ~13K + RM ~33K prompt 排序),成本高且需要持续迭代。
-
与 LLM 推理能力的提升关系不直接:InstructGPT 提升了指令遵循能力,但不直接等同于提升模型的推理能力。后续工作(如 RL on reasoning traces)把 RL 从”对齐偏好”扩展到”提升推理”,是另一个方向。
与已有 Wiki 的连接
- 关联概念:RLHF(人类反馈强化学习)、PPO(近端策略优化)、Alignment Tax、奖励模型
- 关联论文:GPT-3(InstructGPT 的基座模型)、GPT-4(继承了 RLHF 方法论)
- 关联比较:SFT vs RLHF vs DPO(后续出现的更简洁的对齐方法)
- 关联问题:RLHF 的本质是教会模型偏好还是提升推理