一句话总结:本文提出了 GPT-3,一个 175B 参数的自回归语言模型,通过海量数据上的预训练,在不进行任何梯度更新(仅通过上下文中的 few-shot 示例)的情况下,在众多 NLP 任务上展现出强大的性能,证明了”规模本身就是一种涌现”。
Intro
Motivation
近年来 NLP 的预训练+微调范式虽然有显著效果,但存在两个问题:
- 需要大量标注数据:每个下游任务都需要数千到数十万标注样本
- 泛化能力有限:微调后的模型往往在分布外数据上表现不佳
人类智能的特点是从极少量示例中即可学习新任务。作者希望通过扩大模型规模和训练数据量,让语言模型获得类似的能力——在推理时仅通过上下文中的少量示例(in-context learning)即可执行新任务,而无需任何梯度更新。
贡献
- 训练了 175B 参数的 GPT-3:比当时最大的模型大 10 倍
- 系统研究 in-context learning:在 zero-shot、one-shot、few-shot 三种设定下评估,无需微调
- 在多个 NLP 任务上达到 SOTA:包括翻译、QA、数学推理、新闻生成等 42 个 benchmark
- 验证了 scaling 趋势:随着模型从 125M 增大到 175B,few-shot 性能持续提升
Method 核心方法
GPT-3 的核心方法论不复杂——标准 decoder-only Transformer + 海量数据预训练——其真正贡献在于系统性地展示了规模本身如何催生涌现能力。
1. 模型架构与自回归公式
GPT-3 使用与 GPT-2 相同的 decoder-only Transformer 架构。自回归语言建模目标:
即最大化给定前文条件下每个 token 的预测概率。唯一的架构差异:GPT-3 在各层交替使用 dense attention 和 locally banded sparse attention(类似 Sparse Transformer)。
8 种模型规模用于系统性研究 scaling 行为:
| 模型 | 参数量 | 层数 | d_model | 头数 | Batch Size | LR |
|---|---|---|---|---|---|---|
| GPT-3 Small | 125M | 12 | 768 | 12 | 0.5M | 6.0e-4 |
| GPT-3 Medium | 350M | 24 | 1,024 | 16 | 0.5M | 3.0e-4 |
| GPT-3 Large | 760M | 24 | 1,536 | 16 | 0.5M | 2.5e-4 |
| GPT-3 XL | 1.3B | 24 | 2,048 | 24 | 1M | 2.0e-4 |
| GPT-3 2.7B | 2.7B | 32 | 2,560 | 32 | 1M | 1.6e-4 |
| GPT-3 6.7B | 6.7B | 32 | 4,096 | 32 | 2M | 1.2e-4 |
| GPT-3 13B | 13B | 40 | 5,120 | 40 | 2M | 1.0e-4 |
| GPT-3 175B | 175B | 96 | 12,288 | 96 | 3.2M | 0.6e-4 |
上下文窗口统一为 2048 tokens。学习率随模型增大而降低——大模型对梯度更新更敏感。
2. 训练数据——Common Crawl 过滤是关键
总规模约 500B tokens(~570GB)。5 个来源:
| 数据集 | 占比 | Token 数 | 说明 |
|---|---|---|---|
| Common Crawl(过滤后) | 60% | ~300B | 用高质量语料训练分类器过滤,是最大创新 |
| WebText2 | 22% | ~110B | Reddit 高赞链接的扩展版本 |
| Books1 + Books2 | 16% | ~80B | 两大互联网书籍语料库 |
| Wikipedia | 3% | ~15B | 英文维基百科 |
数据质量的核心创新——Common Crawl 过滤 pipeline:用 WebText(被视为正例)作为正样本,训练一个二分类器对 Common Crawl 页面打分。分类器特征包括:页面是否包含大量重复内容、是否为密码/垃圾页面、是否与高质量语料有词汇重叠。这一步骤将原始 45TB 的 Common Crawl 压缩到 ~570GB 的高质量版本。
数据污染控制:对所有下游 benchmark 进行了 n-gram 重叠检测,移除训练集中与测试集有显著重叠的文档(尽管后来发现某些污染仍存在)。
3. 训练基础设施
| 配置 | 值 |
|---|---|
| 优化器 | Adam(β₁=0.9, β₂=0.95, ε=1e-8) |
| 梯度裁剪 | 1.0(按全局 norm) |
| 学习率调度 | cosine decay(经 260B tokens 衰减至 10%) |
| 权重衰减 | 0.1 |
| 并行策略 | 模型并行(跨层)+ 数据并行(跨 GPU) |
| 硬件 | Microsoft Azure 超级计算机(V100 GPU 集群) |
训练过程中未做任何微调——所有能力完全来自预训练(SPM:Standard Pre-training Model)。
4. In-context Learning——GPT-3 的核心评估范式
不进行梯度更新,仅通过在上下文中拼接示例来引导模型行为:
| 范式 | 输入格式 | 示例数 |
|---|---|---|
| Zero-shot | 任务描述(自然语言) | 0 |
| One-shot | 任务描述 + 1 个示例 | 1 |
| Few-shot | 任务描述 + K 个示例 | 10-100 |
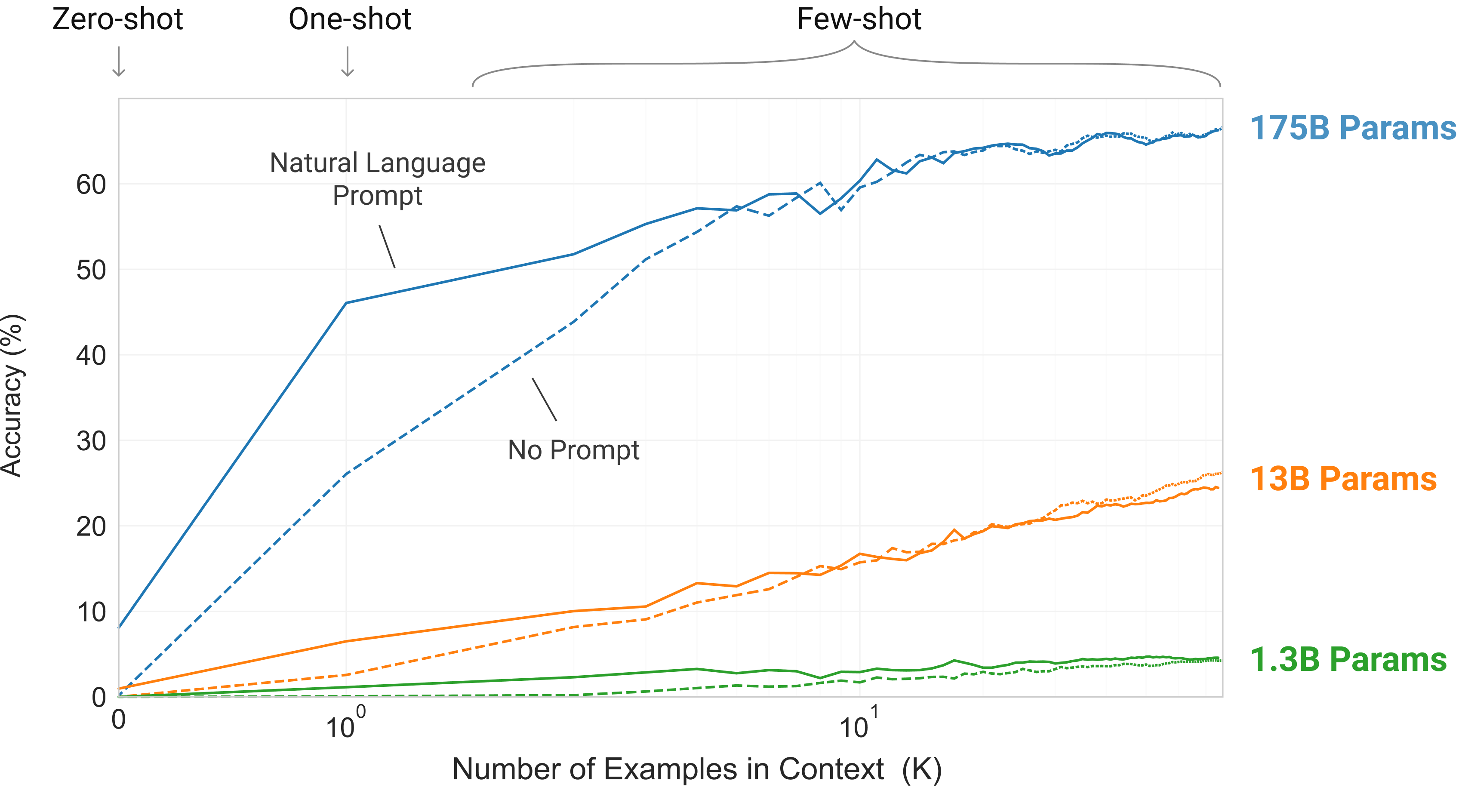
Figure 1.2: 不同规模模型的 in-context learning 能力——大模型的 “in-context learning curves” 斜率更陡,表明从上下文中学习任务的能力随模型规模增强。
计算量与 Scaling Laws:GPT-3 遵循 Kaplan et al. (2020) 的 scaling laws——模型大小增长比数据量增长更快(N ∝ C^0.73, D ∝ C^0.27)。175B 仅训练了 ~300B tokens(远少于 Chinchilla 建议的 “等比例缩放”)。
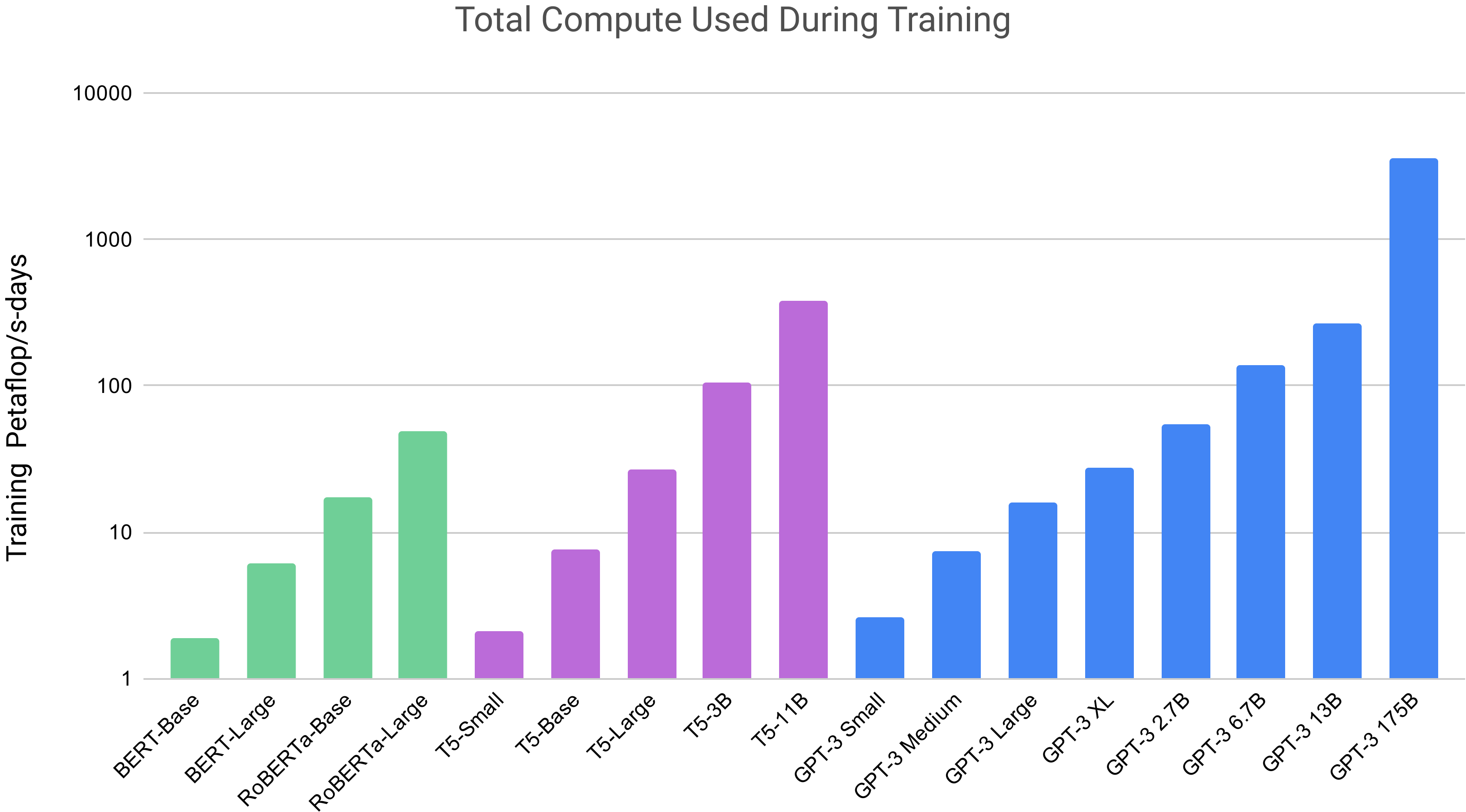
Figure 2.2: GPT-3 各模型的训练计算量(petaflop/s-days)。虽然 GPT-3 3B 几乎比 RoBERTa-Large (355M) 大 10 倍,但两者预训练计算量接近——体现了 scaling laws 的 “模型增长快于数据增长” 策略。
实验/评估/结果
语言建模与 Cloze Tasks
- LAMBADA(zero-shot):GPT-3 86.4%,超越之前 SOTA(68%)超过 18 个百分点
- HellaSwag:79.3%
- Penn Tree Bank:PPL 远超之前方法
问答
- TriviaQA(zero-shot):64.3%,few-shot:71.2%(超越 fine-tuned SOTA)
- WebQuestions(few-shot):41.5%
- Natural Questions(few-shot):29.9%
翻译
- 所有规模下 few-shot 性能随模型增长持续提升
- 英译法、英译德、英译罗等方向表现最好
- 反向翻译(XX→EN)表现较弱:175B 模型反向翻译不敌监督学习小模型
常识推理
- PIQA:82.8%(few-shot)
- ARC(Easy):68.8%,ARC(Challenge):51.4%
- WinoGrande:70.2%
数学推理
- 在加/减法(2-5 位数)上随模型增大持续提升,175B 达到约 90%
- 但模型偶尔会犯非常 basic 的错误
新闻文章生成
- 人类评估中,175B GPT-3 生成的 ~500 词新闻文章,人类仅 52% 能准确区分(接近随机 50%)
局限与失败案例
- 自然语言推理(NLI):ANLI 上 GPT-3 几乎随机(约 40%),可能因为 NLI 需要推理两个句子的关系,in-context learning 难以掌握
- 部分阅读理解:RACE-h 上 few-shot 仅 ~46.8%,远低于 SOTA
- 合成任务的不稳定性:translation、算术等任务在部分设定下表现不稳定
- 生成样本存在重复:上下文越长越容易重复
数据污染的讨论
论文专门讨论了训练数据与测试数据的重叠问题,发现某些数据集的 n-gram 重叠率较高,但去除重叠样本后性能下降通常较小,主要结论不受影响。
结论
GPT-3 证明了:将语言模型的规模提升至 175B 参数并在 ~500B tokens 上训练后,模型在不进行任何微调的情况下,通过 few-shot in-context learning 即可在广泛 NLP 任务上展现出强大的能力。这挑战了”必须为每个任务收集标注数据微调”的固有范式。同时也暴露了在需要深度推理的任务上的明显短板。
思考
优点
-
规模驱动涌现的实证里程碑:GPT-3 是第一个系统证明”规模本身就是一种涌现”的工作。从 125M 到 175B 的 8 种规格的 scaling 曲线,展示了 in-context learning 能力是如何随规模平滑增长的。
-
In-context Learning 范式的开创:在 GPT-3 之前,NLP 主流是 pre-train + fine-tune。GPT-3 证明了不做微调也能执行任务——仅靠 prompt 中的示例即可。这催生了整个 prompt engineering 和 in-context learning 研究领域。
-
训练数据工程的先驱:从 Common Crawl 这一”脏数据”中提取高质量训练数据的方法(用分类器过滤),成为后续大模型训练数据工程的标准做法。
-
对数据污染问题的坦诚:论文公开讨论了训练-测试重叠问题并做了细致的分析(n-gram 重叠、性能影响),这在当时并不多见。
缺点与局限
-
推理能力弱:在 NLI、复杂阅读理解等需要深度推理的任务上表现差。这说明”模式匹配”和”推理”之间存在鸿沟,仅靠规模化不能完全弥合。
-
弱在反向任务:翻译(XX→EN 比 EN→XX 弱得多)暴露了模型本质上是”看多了再复述”,不是真正的双语理解。
-
生成质量与可控性:新闻文章生成虽然难以分辨,但模型缺乏对事实的保证,生成内容可能包含虚假信息。
-
成本极高:175B 参数的训练和推理成本对大多数学术机构不可承受,加剧了 AI 研究的不平等。
-
Ethics/偏见:论文讨论了模型可能包含的偏见和潜在的滥用风险,但讨论深度有限。
与已有 Wiki 的连接
- 关联概念:In-context Learning、Few-shot Learning、Scaling Law、Decoder-only Transformer
- 关联论文:BERT(双向 vs 单向架构之争)、InstructGPT(GPT-3 的指令跟随改进)、Chinchilla 缩放定律(对 scaling law 的修正)
- 后续演进:GPT-3 → InstructGPT/GPT-3.5 → GPT-4
- 关联问题:为什么 decoder-only 架构最终胜出