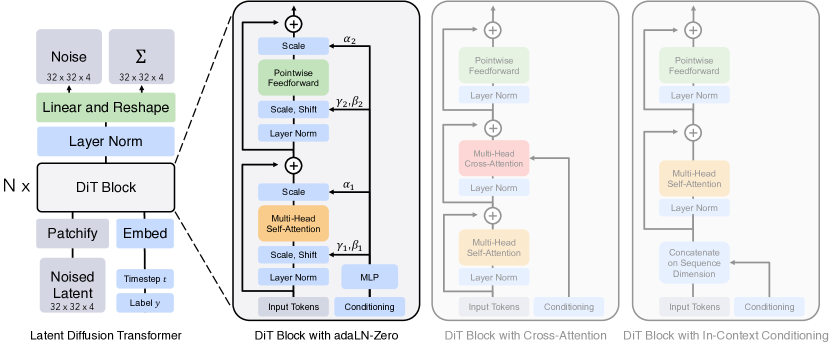
DiT通过模仿ViT,使用Transform架构替换U-Net架构实现了性能提升
Latent Diffusion Transformer
- Noised Latent (带噪的潜空间表示):输入不是原始的像素图像,而是在潜空间(latent space)中经过加噪处理的表示。
- Timestep t 和 Label y:
- Timestep t: 告诉模型当前处于去噪过程的第几步
- Label y: 类别标签,告诉模型要生成哪个类别的图像。
- 两个被嵌入后采用的相加方法拼接作为condition
- Patchify & Embed (分块与嵌入):
- Patchify: 将潜空间特征图分块
- Embed: 将时间步t和标签映射为向量
- DiT Block (N x):这是模型的核心,由N个相同的DiT Block堆叠而成。
- Output (输出):经过N个DiT Block处理后,输出的Tokens会经过Linear and Reshape层,重新组合成潜空间特征图
- Noise & Σ:模型预测的不是去噪后的图像,而是应该从当前输入中移除的噪声。Σ表示模型的另一个可选预测,即去噪过程的协方差,用于更高级的采样策略。
DiT Block with adaLN-Zero
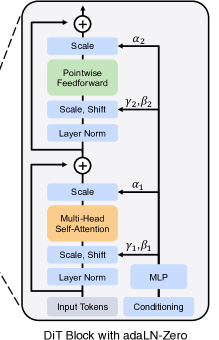
- Conditioning → MLP: 首先,时间步t和标签y的Tokens被送入一个MLP),生成用于控制的参数 γ 和 β
- adaLN (Adaptive Layer Norm): γ和β被用来对Layer Norm层的输出进行仿射变换(Scale, Shift)。这是一种条件注入方式,通过动态调整归一化的结果来控制生成内容。adaLN
- Multi-Head Self-Attention: 这是Transformer的核心,用于计算输入Tokens之间的关系。
- Pointwise Feedforward: 这是Transformer的另一个标准组件,通常是一个MLP,用于对每个Token进行非线性变换。
- Shortcut: 图中带+号的圆圈代表残差连接。
- adaLN-Zero: 除了adaLN,这里还引入了α (alpha) 参数,它也被条件控制。α被初始化为0,所以在一开始训练时,整个残差块是“关闭”的(相当于一个恒等映射),这有助于稳定训练初期的过程。
class DiTBlock(nn.Module):
"""
A DiT block with adaLN-Zero conditioning.
"""
def __init__(self, hidden_size, num_heads, mlp_ratio=4.0, **block_kwargs):
super().__init__()
self.norm1 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
self.attn = Attention(hidden_size, num_heads=num_heads, qkv_bias=True, **block_kwargs)
self.norm2 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
mlp_hidden_dim = int(hidden_size * mlp_ratio)
approx_gelu = lambda: nn.GELU(approximate="tanh")
self.mlp = Mlp(in_features=hidden_size, hidden_features=mlp_hidden_dim, act_layer=approx_gelu, drop=0)
self.adaLN_modulation = nn.Sequential(
nn.SiLU(),
nn.Linear(hidden_size, 6 * hidden_size, bias=True)
)
# zero init
nn.init.constant_(adaLN_modulation[-1].weight, 0)
nn.init.constant_(adaLN_modulation[-1].bias, 0)
def forward(self, x, c):
shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.adaLN_modulation(c).chunk(6, dim=1)
x = x + gate_msa.unsqueeze(1) * self.attn(modulate(self.norm1(x), shift_msa, scale_msa))
x = x + gate_mlp.unsqueeze(1) * self.mlp(modulate(self.norm2(x), shift_mlp, scale_mlp))
return x