多模态 情感 AIM [2505.18699] Affective Image Editing: Shaping Emotional Factors via Text Descriptions [2504.09689] EmoAgent: Assessing and Safeguarding Human-AI Interaction for Mental Health Safety [2501.05710] EmotiCrafter: Text-to-Emotional-Image Generation based on Valence-Arousal Model
《EmotiCrafter: Text-to-Emotional-Image Generation based on Valence-Arousal Model》
- 目标: 开发一个模型,能够根据文本提示和连续的情感数值(Valence-Arousal),生成内容可控且情感丰富、准确的图像。
Info
Valence (愉悦度): 1.65 (比较积极) Arousal (激动度): -0.12 (比较平静) 均介于
- 方法:作者提出了 EmotiCrafter,一个基于稳定扩散模型 (Stable Diffusion XL) 的情感图像生成框架。
- 核心思想: 不直接生成图像,而是通过一个情感嵌入网络 (Emotion-Embedding Network),将用户指定的连续情感值(Valence-Arousal)注入到文本提示的特征中,从而引导图像生成模型产生带有特定情感的图像。
整体流程
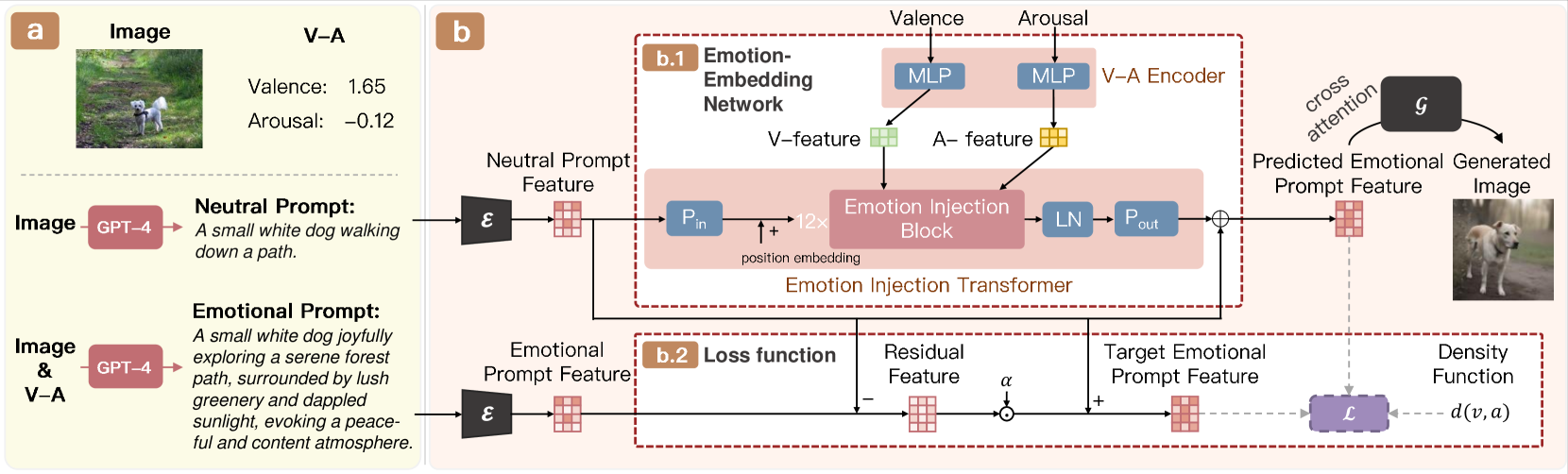
- 输入: 一个描述图像内容的中性文本提示 (Neutral Prompt) 和一对表示情感的V-A值 (Valence, Arousal)。
- 情感嵌入网络 (M):
-
首先,一个V-A编码器 (V-A Encoder) 将V-A数值对通过两个独立的多层感知机(MLP)转换为V特征向量()和A特征向量()。
-
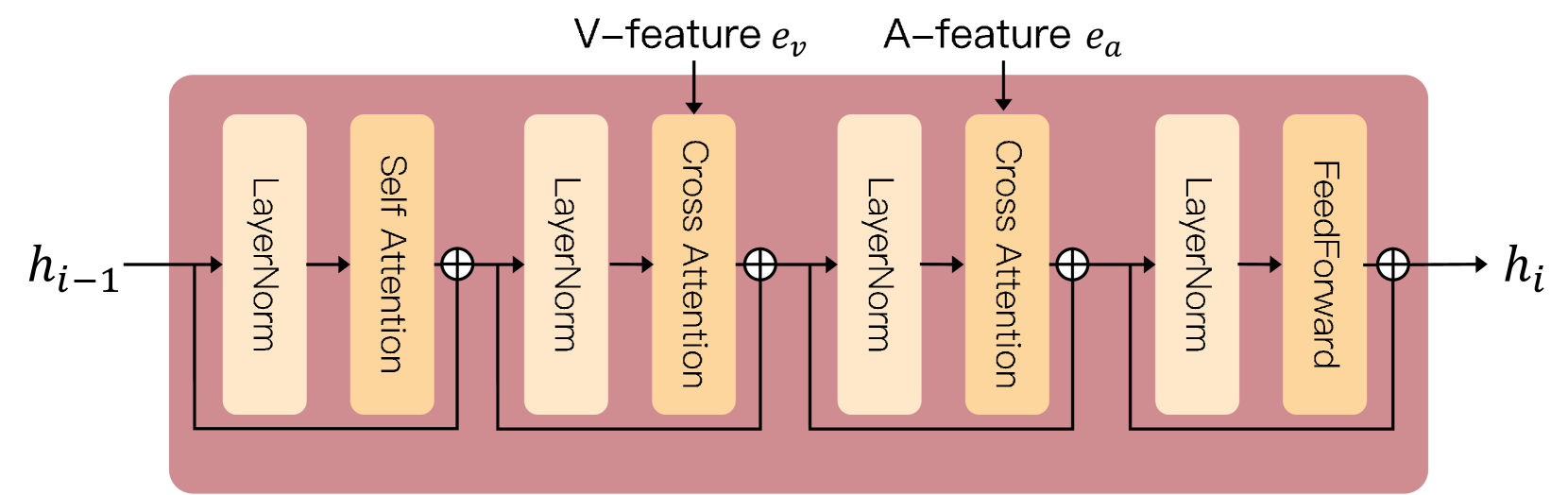
-
然后,一个情感注入转换器 (Emotion Injection Transformer, EIT) 将中性文本的特征和V-A特征向量融合。它通过交叉注意力机制,将情感特征注入到文本特征的处理流程中,生成带有情感信息的情感化特征 (Emotional Prompt Feature)。
-
- 图像生成 (G):
- 将生成的情感化特征输入到预训练的SDXL模型的U-Net中,通过交叉注意力机制指导图像的去噪生成过程,最终输出符合文本内容和指定情感的图像。
《Affective Image Editing: Shaping Emotional Factors via Text Descriptions》
1. 论文简介
- 目标:优化处理情感需求,目前模型存在缺陷:
- 情感理解能力弱: 通用编辑模型(如 InstructPix2Pix)无法准确理解和执行带有情感色彩的编辑指令。
- 控制粒度粗糙: 现有情感编辑方法多依赖离散的情感类别或只关注单一情感因素,限制了用户表达细腻、复杂情感的能力。例如EmoEdit

- 方法:作者提出了 AIEdiT (Affective Image Editing using Text descriptions),一个基于扩散模型的、通过文本描述进行情感编辑的框架。
- 核心思想: 设计一个情感映射器 (Emotional Mapper),将用户输入的、视觉上抽象的情感文本请求,转化为视觉上具体的语义表示,并利用多模态大语言模型 (MLLM) 作为监督,确保编辑结果能够准确唤起目标情感。
2. EmoTIPS 数据集
- 方法: 从EmoSet 中收集情感图像,并使用 MLLM 为每个样本生成相应的情感文本描述,包括三个阶段:标注、验证和评估
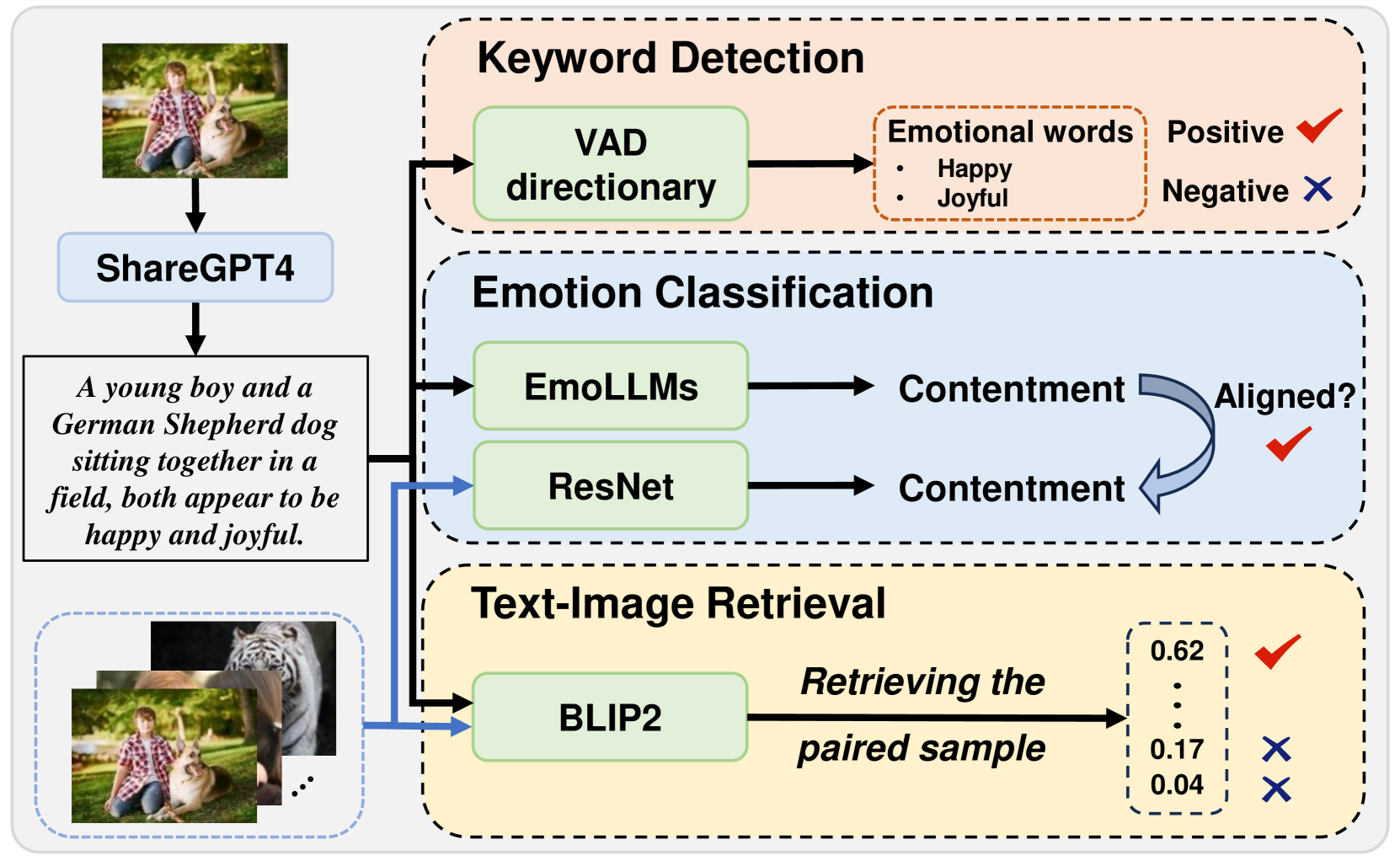
- 步骤:
- 通过GPT4生成描述
- 将生成的文本输入到一个VAD词典 (VAD dictionary) 中。VAD代表Valence(效价)、Arousal(唤醒度)、Dominance(支配度),是描述情感的维度。这里主要用它来识别情感词
- 使用EmoLLMs和 ResNet,验证从文本中识别出的情感与从图片中识别出的情感是否一致,
- 用BLIP2进行图文检索,:验证生成的文本描述是否足够具体和独特
3. AIEdiT
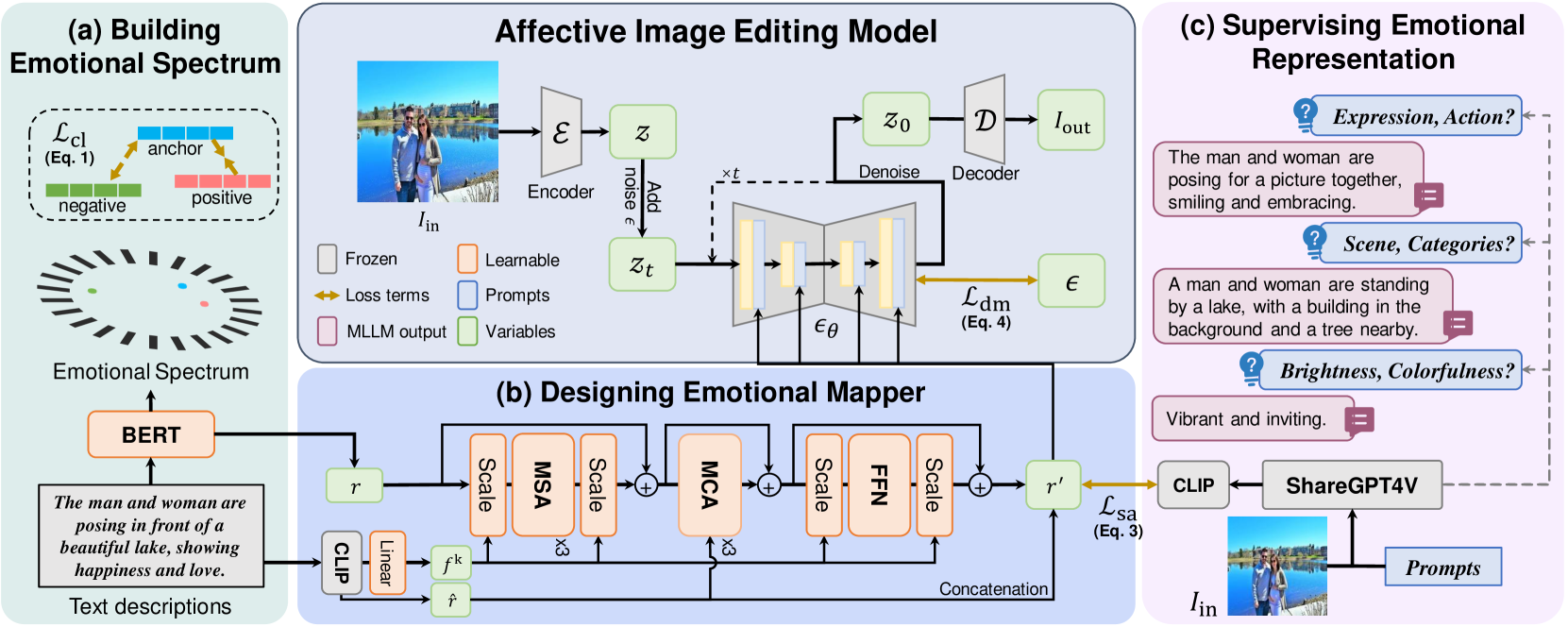
3.1 情感光谱构建
- 目的: 学习一个能够表示普适情感的连续空间。
- 方法:
- 使用BERT提取文本的情感请求 。
- 使用预训练的ResNet估计图像的情感类别分布 (基于Mikel’s wheel)。
- 将 配对,构成样本 。
- 通过连续情绪表征学习,使得在情感上相似的样本在特征空间中距离更近,情感上对立的样本距离更远。
3.2 情感映射器设计
- 目的: 将抽象的情感文本请求 翻译成具体的视觉语义表示 。
- 结构: 一个多模态Transformer,包含自注意力(MSA)、交叉注意力(MCA)和前馈网络(FFN)。
- 工作流程:
- 输入情感请求 、文本语义 (来自CLIP) 和关键语义特征 。
- 在每个子模块后对情感特征进行缩放,动态调整情感的表达强度。
- MCA模块负责将情感语义与相关的视觉元素进行融合。
- 最终输出与视觉对齐的情感表示 。
3.3 MLLM监督与训练
- 挑战: 缺乏目标情感图像,无法直接监督情感映射器的学习。
- 解决方案: 使用MLLM (ShareGPT4V) 进行自监督学习。
- 方法:
- 针对输入图像,向MLLM提出关于色调、场景、表情/动作等情感相关因素的问题。
- 将MLLM的回答作为“真实”的语义表示。
- 设计情感对齐损失 (Sentiment Alignment Loss, ),最小化情感映射器生成的语义表示与MLLM回答的CLIP嵌入之间的差距。
- 总损失 的计算公式为:
3.4 情感图像编辑
- 图像编辑流程:
- 编码: 输入的原始图像 被 Encoder 编码为潜在表示 。
- 加噪: 向 中加入一定量的噪声 ,得到带噪的 。这是扩散模型的标准步骤。
- 去噪 (核心控制点): 去噪网络 (也就是我们常说的U-Net) 开始工作。它在去噪的每一步,都会将从 (b)中得到的情感指令 r’ 作为条件输入。这就是控制的关键所在: 告诉去噪网络应该朝着哪个情感方向恢复图像,比如是让颜色更鲜艳,还是让人物表情更微笑。
- 解码: 去噪完成后得到干净的潜在表示 ,再通过 Decoder 恢复成最终的输出图像 。
- 损失 : 这是标准的扩散模型损失,用于训练去噪网络。