一句话总结本文工作
本文提出了首个针对多轮、上下文相关的交织(Interleaved)跨模态理解与生成任务的套件 WEAVE,包含一个大规模训练数据集 WEAVE-100k 和一个高质量人工标注基准 WEAVEBench,旨在解决现有模型缺乏视觉记忆和长程推理能力的问题。
1. 总体介绍
1.1 Motivation
现实背景引入:现实世界的图像编辑是多轮迭代的,人类创作者通常进行可逆的微调,重用之前的素材。 现在的 GAP:当前数据集主要针对单轮编辑。即便有多轮,往往也是伪多轮,本质上是单轮编辑的简单拼接。模型将每一次编辑视为独立的指令,忽略了多轮交互中的时间依赖(Temporal Dependencies)和视觉记忆(Visual Memory)(例如:“把刚才移除的那个花加回来”)

1.2 Contribution
- WEAVE-100k 数据集: 包含大量多轮交错图文数据,包含超过 100 K 个样本、 370 K 个对话回合,以及跨越理解、编辑和生成任务中的 500 K 张图像。
- WEAVEBench 基准: 这是首个用于交错多模态理解和生成的带人工标注的基准
- 验证: 通过微调 Bagel 模型,证明了该数据集能赋予模型“视觉记忆”能力,并显著提升现有 Benchmark 的成绩。
2. WEAVE-100k
作者设计了 4 条不同的pipeline,后验证和理解任务
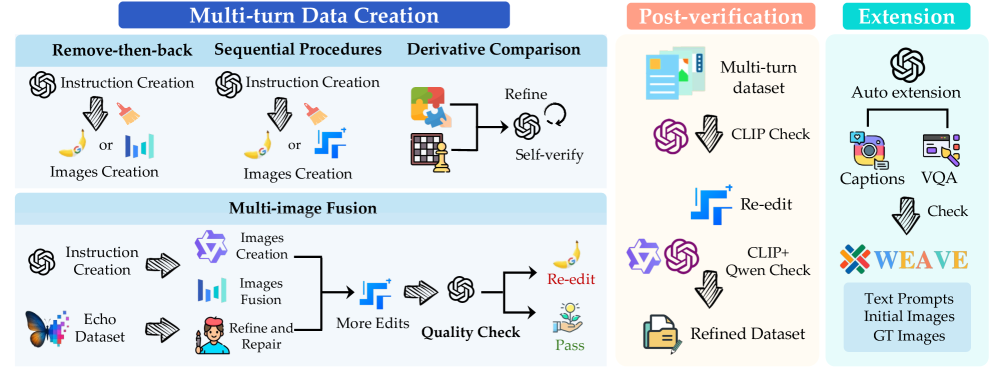
2.1 Multi-image Fusion Pipeline
整体思路:先生成目标图像,再补充中间步骤,类似于倒推法
详细步骤 1. 参考了 Echo-4o 数据集中的多图融合数据。使用 GPT-4.1 优化指令,然后用 Seedream 4.0 重新生成高质量的融合结果图。 2. 逆向构建多轮历史 1. 使用 GPT-4.1 生成单轮融合指令和原图描述,然后用 Qwen-Image 生成原图。 2. 构建编辑链:使用 GPT-4.1 为这些原图生成一系列编辑指令(如:add, remove, replace, color alter, background change)。 3. 执行编辑:使用 Step1X-Edit (v1.2) 模型执行这些单轮编辑。 3. 将这些“编辑过的图”作为历史上下文(Originals),将最终的“多图融合图”作为最后一轮的输出。

2.2 Remove-then-back Pipeline
- 使用 GPT-4.1生成多轮编辑指令要求其中一轮操作需将前几轮中已删除或替换的物体重新添加回来
- 通过 Seedream 4.0 和 Nano Banana 生成输出结果
2.3 Derivative Imagination and Comparison
- 数据源:Zebra-CoT 数据集(包含chess game 和 visual jigsaw)
- 步骤 1:将棋谱缩写改写为显式的编辑指令
- 步骤 2:利用 GPT-4.1 对生成的棋盘状态进行逻辑检查,确保图像生成符合游戏规则
2.4 Sequential Procedures
- 逻辑:模拟叙事进展(Story generation)。
- 要求:(1) 多步骤过程,(2) 步骤间有明确关系,(3) 角色特征必须保持一致。
- 实现:定义了12个类别,使用 GPT-4.1 生成故事脚本,人工筛选质量。
2.5 Post-verification
为了清洗数据,作者设计了多重验证(Appendix A.1):
- CLIP Check:检测图文匹配度。
- Similarity Check:检测编辑前后的图像相似度。如果编辑指令是“微调”,但图像变动过大(相似度低),则剔除或重绘。
- Qwen-VL Check:使用 Qwen-VL 进行语义一致性检查。
- Re-edit:对于验证失败的样本,使用 Step1X v1.2 或 Nano Banana 进行针对性修复。
2.6 Comprehension Extension
- 目的:WEAVE 的目标是训练UMMs,而不是图像编辑模型,需要补充模型
- 操作:在过滤后的生成数据中,使用 GPT-4.1 插入VQA任务。
- 包括:Captioning(描述图)、Counting(数数)、Relationships(物体关系)、Knowledge(背景知识)。
- 策略:每个样本最多插入一轮理解对话,保持生成任务的主导地位。
3. WEAVE-Bench
3.1 Benchmark 构成
- 规模:100 个精心设计的任务,涉及 480 张图像。由理工科研究生(STEM degrees)标注。
- 四大领域:
- Science: 物理规律(光干涉变化)、生物生长过程等。
- Creation: 故事板创作、多图素材合成。
- Logic: 几何题作图、逻辑推演。
- Game: 国际象棋推演、Minecraft 合成表。
3.2 混合评估机制 (Hybrid VLM-as-a-judge)
传统的 FID 或单纯的图文相似度无法评价多轮一致性。作者提出了一种基于 GPT-4o 的混合评估:
-
Hybrid Input: 裁判(GPT-4o)同时接收:
- Reference Image
- Instruction
- Generated Image
-
四大指标 (Appendix B.1 提供了详细 Prompt):
- KP (Key Point Correctness): 关键点是否满足?(权重 0.5)
- VC (Visual Consistency): 非编辑区域是否保持不变?角色ID是否一致?(权重 0.2)
- IQ (Image Quality): 生成质量。(权重 0.3)
- Acc: 用于纯理解任务的准确率。
4. WEAVEBench
-
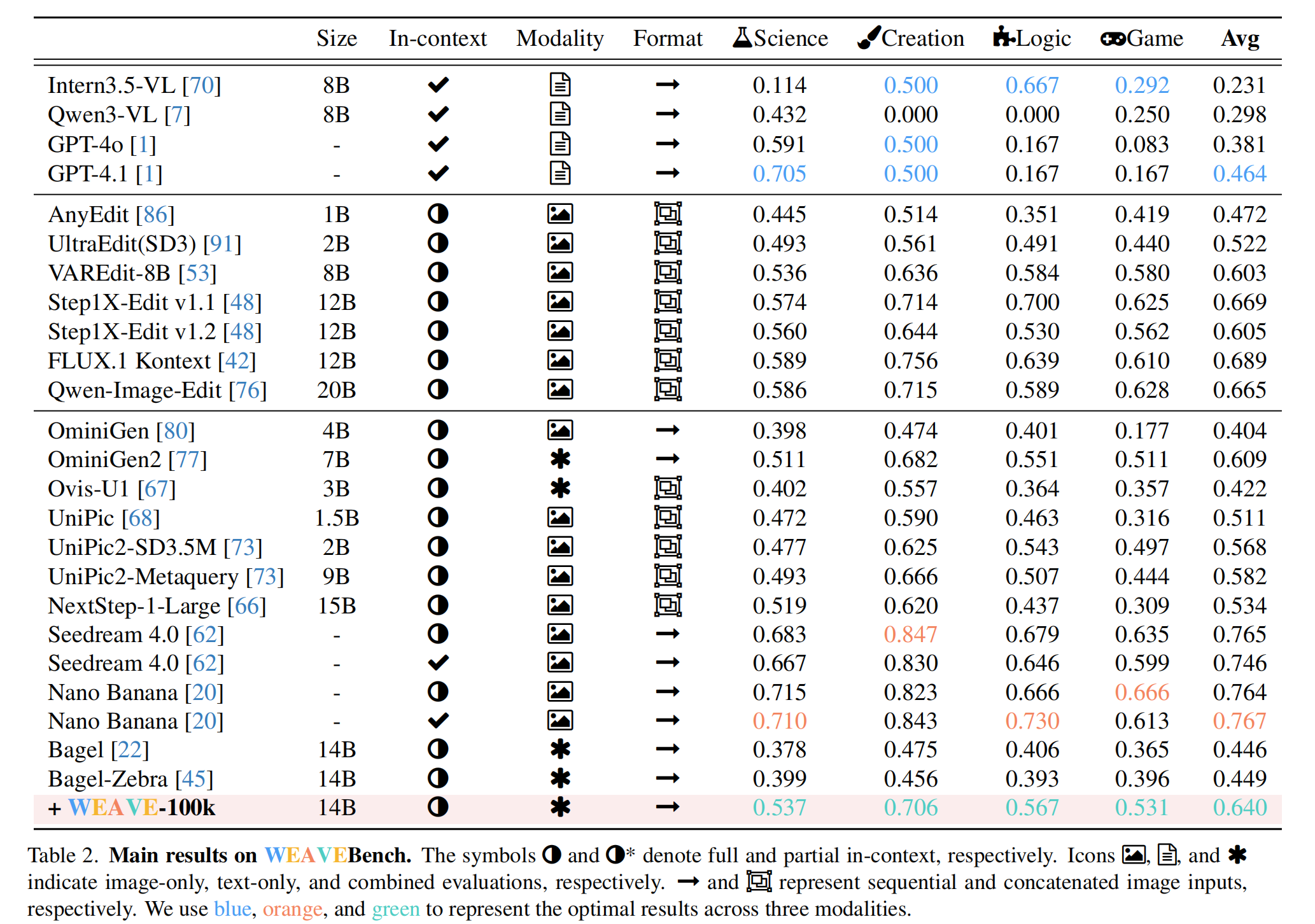
总体表现: 所有模型在整体上表现出在 Creation 这种注重美学的任务上表现更好,在 Science 等需要逻辑推理和世界知识的任务上表现较差。
-
上下文记忆
- 对于生成任务,增加上下文内容对不同模型类型产生了分化效应。单轮编辑能力的开源模型在处理扩展上下文信息时,定位准确性会降低,因而无法有效利用上下文数据(Qwen )。相反,Nano 等专有模型则表现出渐进式改进,表明其成功利用了上下文信息。
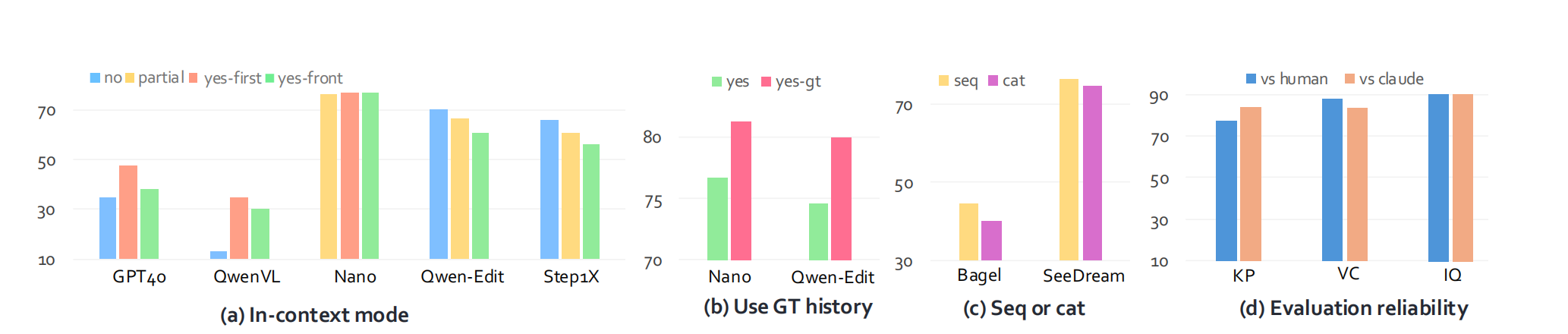
- 对于生成任务,增加上下文内容对不同模型类型产生了分化效应。单轮编辑能力的开源模型在处理扩展上下文信息时,定位准确性会降低,因而无法有效利用上下文数据(Qwen )。相反,Nano 等专有模型则表现出渐进式改进,表明其成功利用了上下文信息。
-
序列输入优于拼接:实验证明,将历史图像作为 Sequential 输入,比简单地将多张图拼接成一张大图输入效果更好。
5. Bagel 训练结果
5.1 实验设置
- 底座模型:Bagel-14B
- 训练细节:8x H100 GPUs,30k steps,Batch size 1
- Context处理:由于 Bagel 是 Token-intensive 的,采用多轮对话直接训练会爆显存,时采用随机采样单轮对话(Random Sampling Single Turn)以适应显存,但在推理时支持多图输入。具体而言是从多轮对话中采样单轮对话,并将之前的图片作为上下文输入,抛弃前文的编辑指令
5.2 实验结果
- WEAVEBench 上的性能提升:微调后从原始 Bagel 的 0.446 升至 0.640。整体性能提升了约 42.5%。全面超越了同量级的开源模型(如 OmniGen, Ovis),甚至在部分指标上逼近了参数量更大或闭源的专用模型。
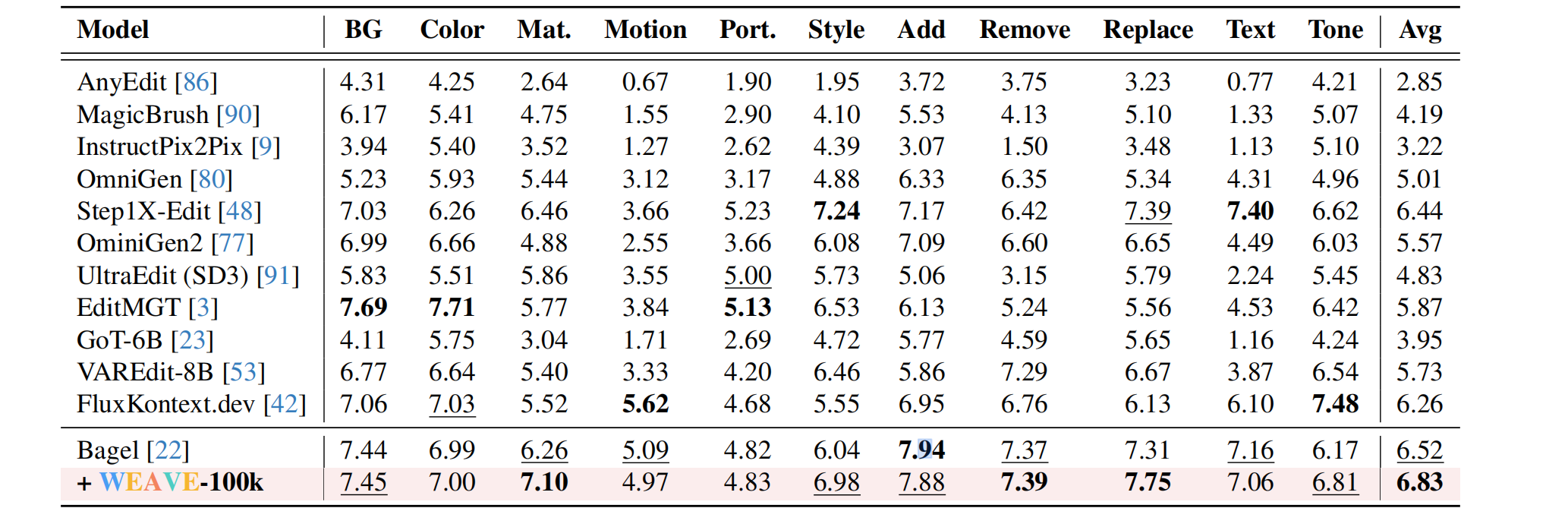
- 泛化能力验证:为了确认模型并非只是“死记硬背”了 WEAVE 的数据格式。作者在通用 Benchmark 上进行了测试,结果证明了能力的泛化,在 understanding 和 GenEVAl 上有很小的提升,没有能力退化,同时在同属于推理能力的 RISEBench 上,有较大的提升。
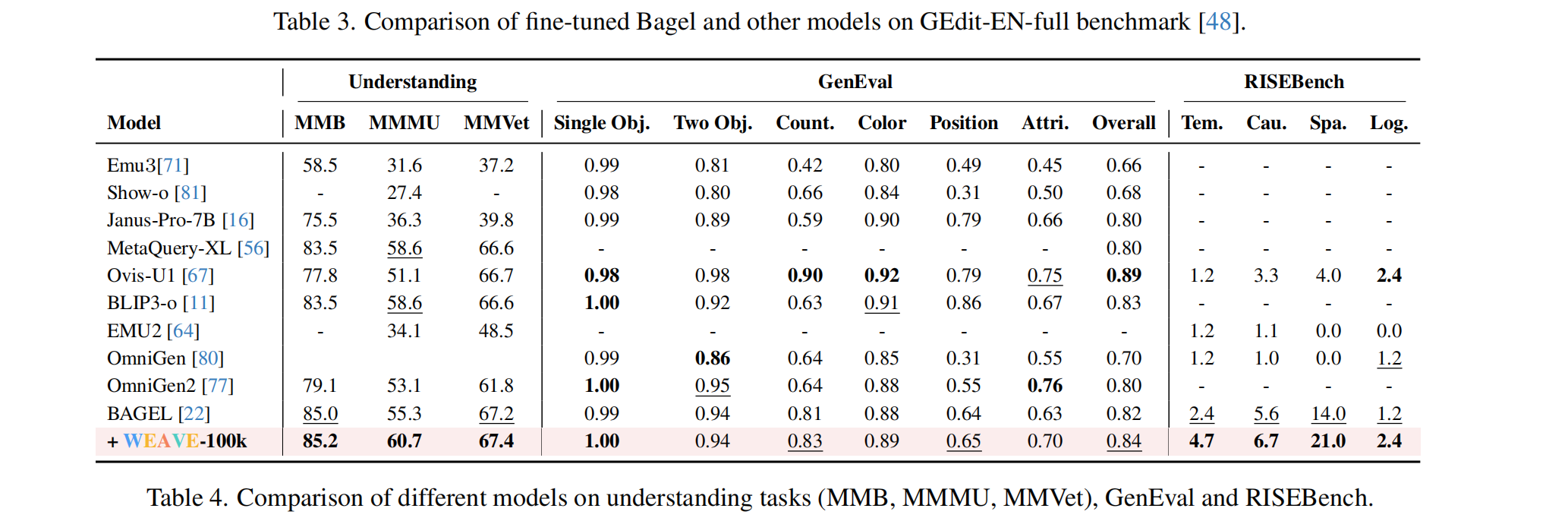
- 涌现的视觉记忆:这证明了 WEAVE-100k 成功赋予了模型在长上下文中保持记忆和 id 一致性的能力。*

6. 结论
本文针对多模态模型在“多轮交互”场景下的短板,构建了 WEAVE-100k 数据集和 WEAVEBench。核心贡献在于证明了:通过高质量的交错图文数据训练,模型可以习得基于上下文的视觉记忆和推理能力,从而实现真正的迭代式图像创作。
7. 收获
- Pipeline 设计巧妙:特别是 “Remove-then-back” 和 “Multi-image fusion” 的逆向构造法,有效地将抽象的“记忆”需求转化为了具体的监督信号。
- 基模的选择,Bagel 是少数具有视觉和生图能力的模型。并且他的基础表现比较差,在训练后的提升更大。同时有架构优势:Bagel 在预训练阶段就已经使用了大量的图文交错数据