1. Vision Transformer
- 核心思想: 传统上,计算机视觉领域由卷积神经网络(CNN)主导。而 ViT 借鉴了自然语言处理(NLP)领域的成功经验,将 Transformer 模型应用于图像识别任务。
- 基本原理:
- 图像分块 (Patching): 将输入的图像分割成一系列固定大小的小块(Patches)。
- 线性嵌入 (Linear Embedding): 将每个小块展平并线性投影到一个固定维度的向量中,这被称为 “Token”。
- 位置编码 (Positional Encoding): 因为 Transformer 本身不具备处理序列顺序的能力,所以需要为每个 Token 添加位置信息。
- Transformer 编码器: 将处理后的 Tokens 输入到标准的 Transformer 编码器中,通过自注意力机制(Self-Attention)进行特征学习。
- 分类: 最后,通常会使用一个特殊的 [CLS] Token 的输出来进行最终的分类。
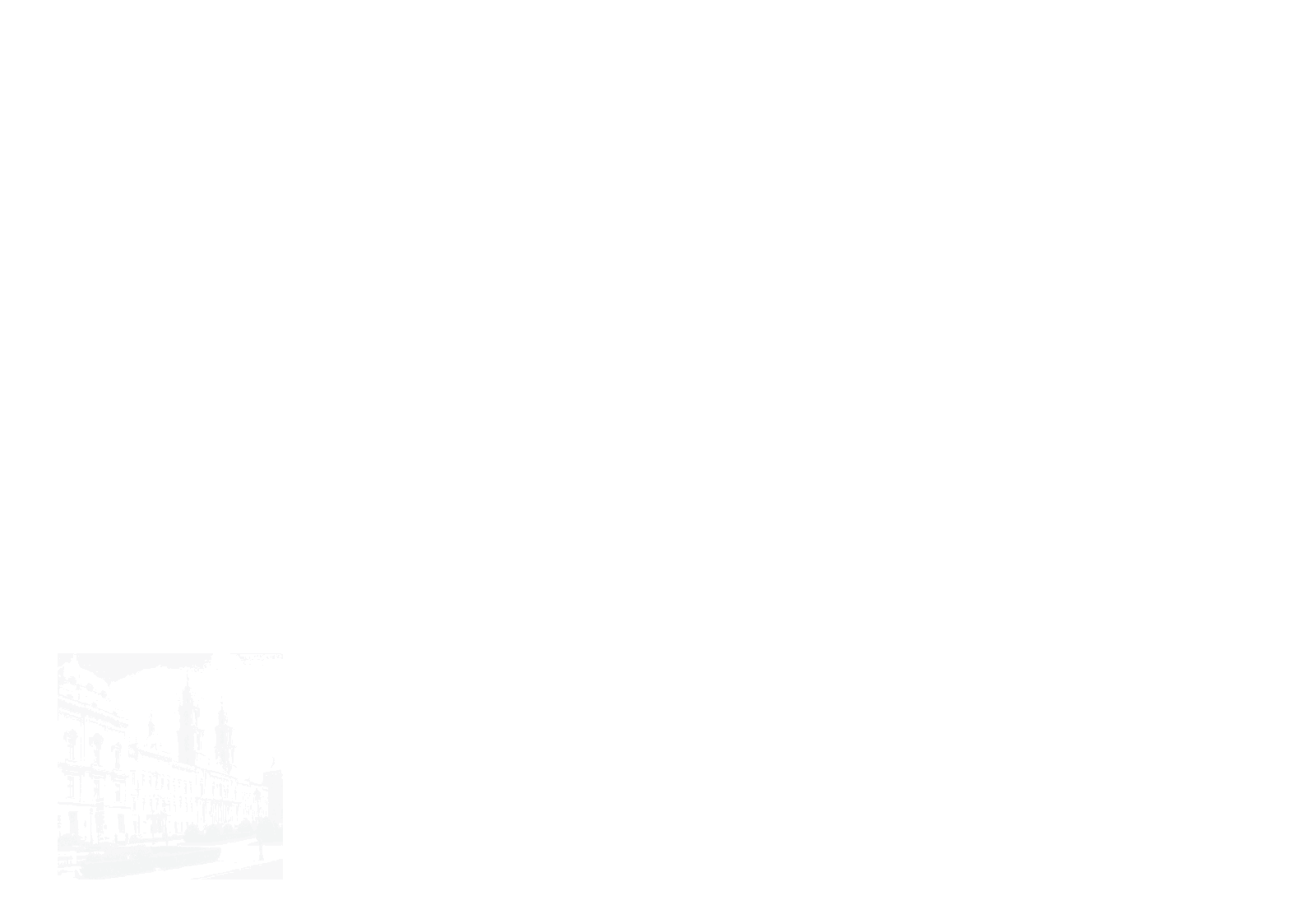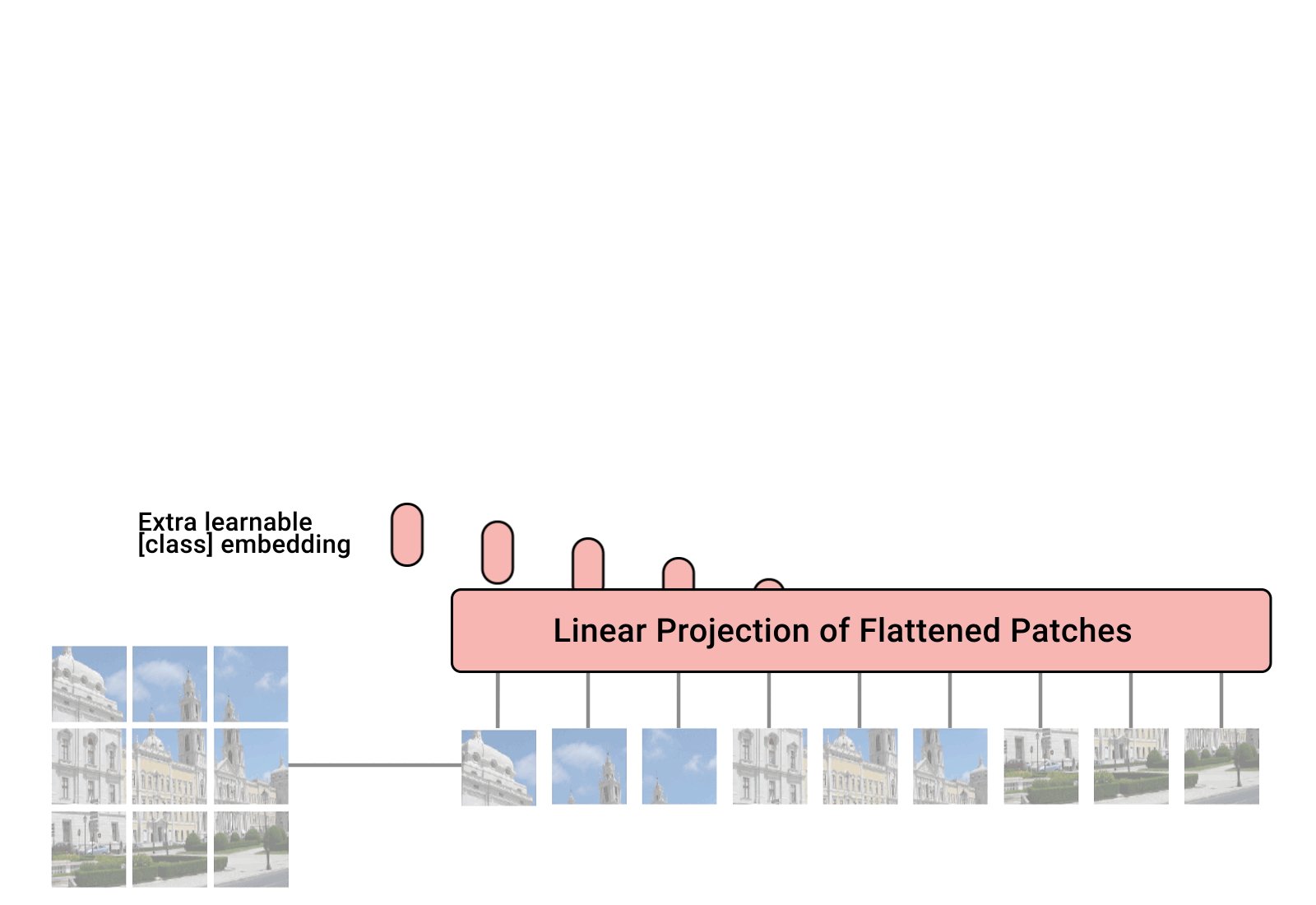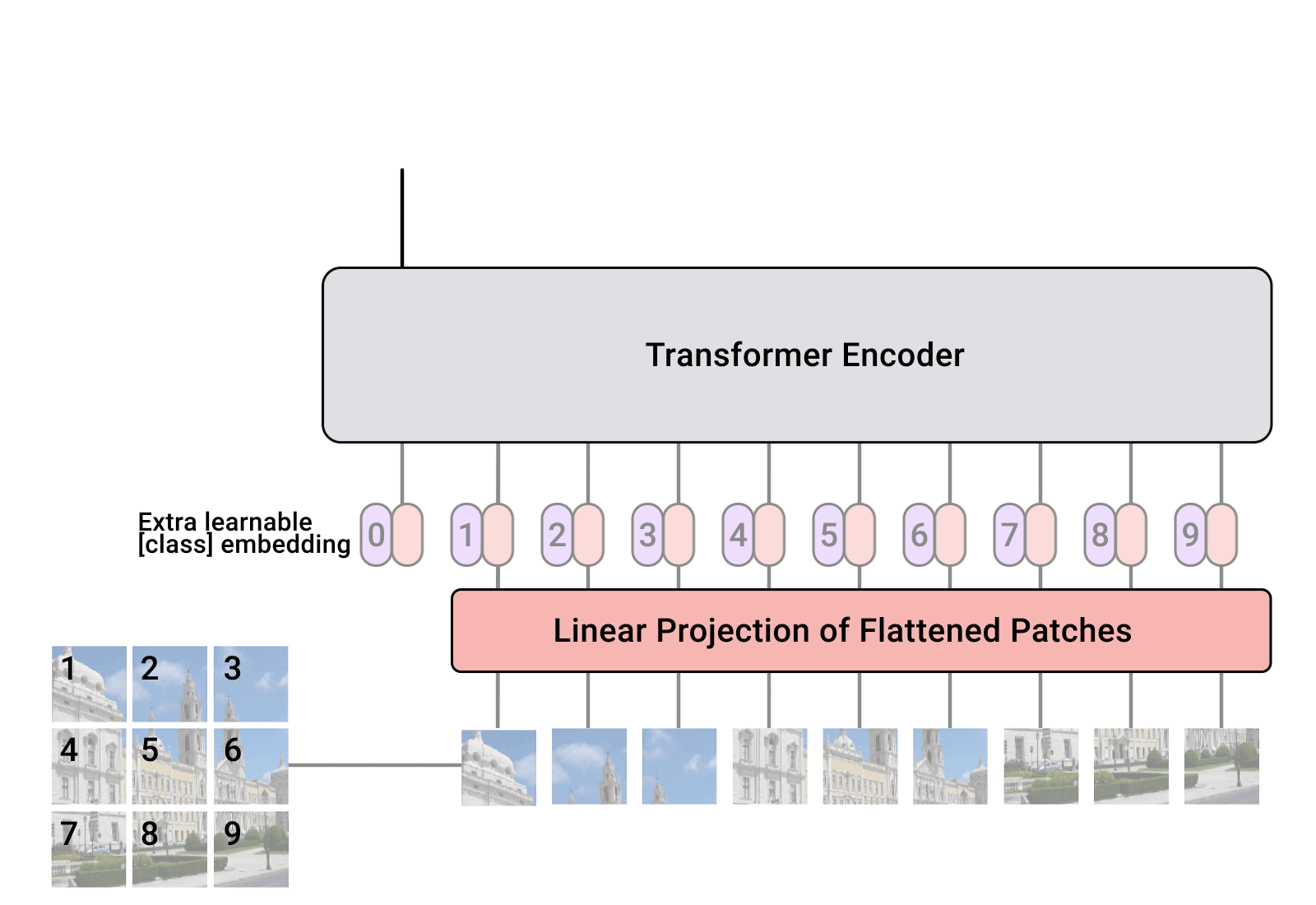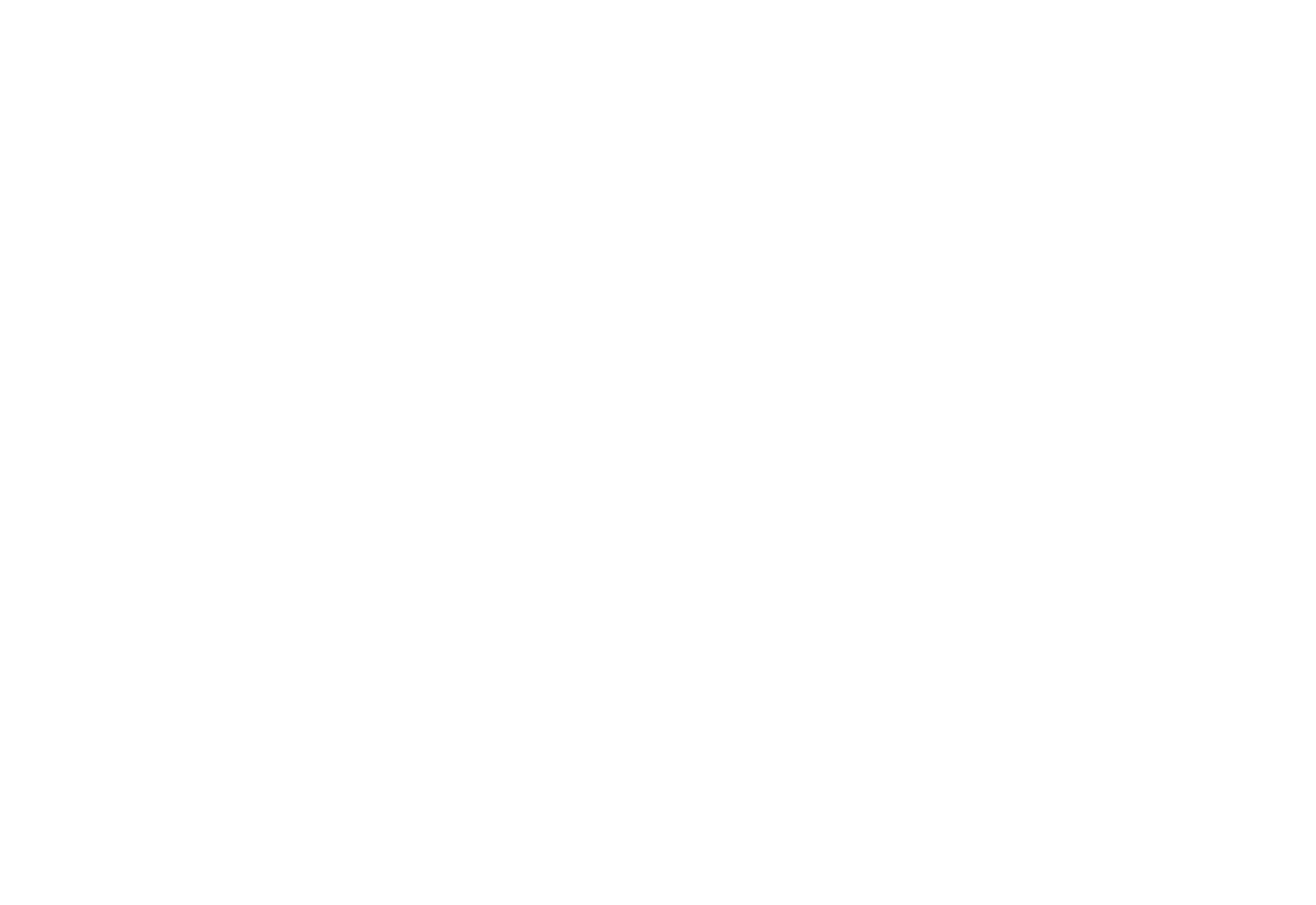
2. 基础 ViT 的实现
import torch
from vit_pytorch import ViT
# 初始化 ViT 模型
v = ViT(
image_size = 256, # 图像尺寸
patch_size = 32, # Patch 块大小
num_classes = 1000, # 分类数量
dim = 1024, # Token 的维度
depth = 6, # Transformer Block 的数量
heads = 16, # 多头注意力的头数
mlp_dim = 2048 # MLP 层的维度
)
# 创建一个随机图像
img = torch.randn(1, 3, 256, 256)
# 进行预测
preds = v(img) # 输出形状为 (1, 1000)3. ViT变体
1. 效率与性能的深化
早期的ViT模型较大且难以训练。后续研究致力于提升其效率和在更深网络中的表现。
- SimpleViT: 作为对原始ViT的简化和优化,它提出使用全局平均池化(替代[CLS] Token)、移除Dropout等措施,配合更强的现代数据增强手段,可以在更快的训练速度下达到更好的性能。
- DeepViT: 针对ViT在层数加深时(如超过12层)性能下降的问题,提出了“Re-attention”机制,通过混合不同头的注意力输出来增强深层网络的信息流。
- CaiT: 同样为了解决深度训练问题,CaiT引入了LayerScale技术(对残差块的输出进行通道级缩放),并将自注意力与类别注意力(CLS Token与Patch Tokens的交互)解耦,只在最后几层进行全局信息聚合,提升了训练稳定性。
2. 融合卷积的混合架构
结合CNN在捕捉局部特征方面的优势和Transformer的全局建模能力,构建了混合模型
- CvT (Convolutional Vision Transformer):在ViT的多个阶段引入卷积。具体而言,使用卷积进行Token的嵌入和下采样,并在注意力机制中也引入了深度可分离卷积来生成Query、Key和Value,有效增强了模型的局部信息感知能力。
- LeViT: 将卷积思想更深度地融入Transformer,包括使用卷积替代Patch投影、在注意力中加入非线性激活、使用BatchNorm替代LayerNorm等,构建了一个为快速推理而设计的混合架构。
- MaxViT: 提出了一种多轴(Multi-Axis)混合架构,在一个模块中交替使用卷积(MBConv)、局部窗口注意力(Block Attention)和稀疏全局注意力(Grid Attention),实现了效率和性能的平衡。
3. 多尺度与分层处理
原始ViT在单一尺度上处理Token,缺乏对图像层次化特征的建模。后续工作借鉴了CNN中特征金字塔的思想。
- PiT (Pooling-based Vision Transformer):在不同阶段通过一个基于深度可分离卷积的池化层来对Token序列进行下采样,从而构建了特征金字塔,有效减少了计算量并提升了性能。
- Twins SVT: 通过混合使用在局部窗口内计算的自注意力(LSA)和在全局稀疏采样点上计算的自注意力(GSA),在不同阶段逐步降低特征图分辨率,实现了类似Swin Transformer的效果,但结构更简单。
- CrossViT: 设计了一个双分支架构,两个Transformer分别处理高分辨率和低分辨率的Patches,并通过一个跨注意力模块周期性地进行信息交互,从而同时捕获图像的精细细节和全局上下文。