本文提出了一个名为 Aes-R1 的图像审美评估框架,通过创新的两阶段训练流程(数据生成+模型训练)和一种新颖的强化学习算法 RAPO,使模型能够同时优化相对美学排序和绝对美学分数,从而实现更接近人类的、可解释的审美判断。
1. Intro
-
背景: 利用MLLMs 的跨模态理解能力进行图像审美评估(Image Aesthetic Assessment, IAA)成为一个新兴的研究热点。这超越了传统的图像质量评估(如清晰度、噪声),转向了对构图、色彩和谐、情感影响等高层次特征的理解。
-
当前问题:
- 监督微调(SFT)的局限性: 需要大量带有人工标注分数的数据,并且模型容易在特定数据集上过拟合,缺乏泛化能力和可解释性。
- 强化学习(RL)的应用困境:
- 缺乏对应语料库的预训练
- 缺少统一的美学偏好标准
- 无法平衡相对优劣和决定分数
-
本文的解决方案和贡献: 针对上述问题,本文提出了 Aes-R1 框架,其核心贡献有三点:
- 构建了 AesCoT 数据管线: 一个高效、自动化的流程,用于生成高质量、包含五个维度(光影、情绪、构图、色彩、曝光)审美分析的训练数据,大大降低了数据标注成本。
- 提出了 RAPO 强化学习算法: 一种新颖的 Relative-Absolute Policy Optimization 算法。它设计了一个双重奖励机制,同时优化模型的相对排序能力和绝对评分精度,使模型的判断更全面、更符合人类复杂的审美直觉。
- 设计了两阶段训练流程: 先通过 1-epoch 的 SFT 进行“冷启动”,为模型注入基础的审美知识和结构化输出能力,然后利用 RAPO 进行强化学习,以实现高效的自我探索和优化。
2. Method
本文的方法分为两个核心部分:AesCoT 数据构建 和 RAPO 策略优化。整个训练流程是一个两阶段的管道。
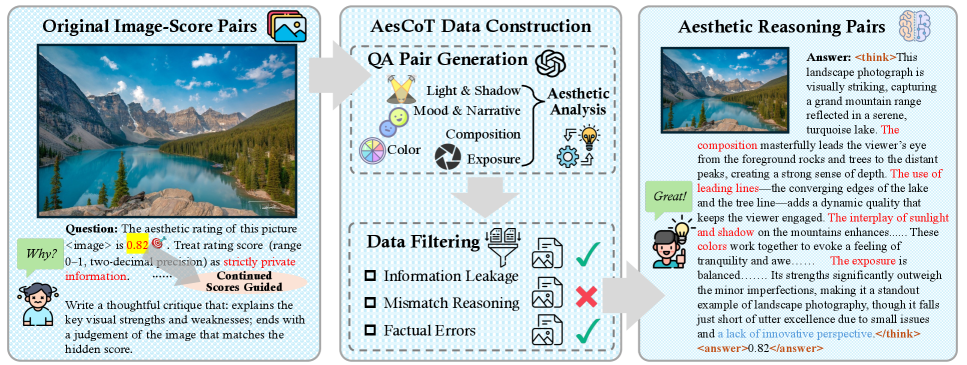
1. AesCoT: 自动化美学推理数据构建
为了解决高质量美学评论数据稀缺的问题,作者设计了 AesCoT 流程,其步骤如下:
-
数据收集: 从公开数据集中收集“图像-分数”对。
-
Prompt 设计与数据生成:
在向GPT-4.1提问时,提供真实分数,要求模型从光影、情绪与叙事、构图、色彩、曝光这五个核心美学维度进行“思维链(Chain-of-Thought)”式的分析。要求在分析中隐藏真实分数
Prompt
用于审美评分的提示 您是审美专家。您对这张图片 <image> 的美感总体评价如何?评级应该是 0 到 1 之间的浮点数,四舍五入到小数点后两位,0 代表质量非常差,1 代表质量非常好。你的任务:1。仔细思考问题,将你所有的思考或推理过程放在一对 <think>…</think> 标签中。2.然后仅在一对 <answer>…</answer> 标签内提供正确的评分。3.这些标签之外没有任何其他信息或文本。例如。你的回答应该是:<think>…</think><answer>…</answer>
Prompt
用于构建AesCoT的提示 您是一位美学专家。这张图片<image>的美学评分为{score}。请将评分(范围0-1,保留两位小数)视为严格保密信息。评分是一个介于0到1之间的浮点数,四舍五入至两位小数,0代表质量极差,1代表质量极佳。请仔细审视图像的构图、光线、色彩协调性、主题内容、技术执行以及情感影响。撰写一篇深思熟虑的评论,要求:阐明图像的主要视觉优势和不足;最后给出与隐藏评分相符的图像评价。切勿提及具体分数数值或该分数已被提供的事实。不要在回答中引用这些指示或任何隐藏变量。请使用英语作为回答语言。
- 数据过滤: 这是保证数据质量的关键一步。通过自动化脚本和人工审核,过滤掉三类错误数据:
- 分数泄露 (Score Leakage): 评语中直接或间接提到了数值分数。
- 推理矛盾 (Reasoning Inconsistencies): 评语的逻辑(例如,高度赞扬)与最终的低分判断相矛盾。
- 事实错误 (Factual Errors): 评语中描述了图像中不存在的内容。
通过这个流程,作者生成了高质量的 (图像, Prompt, 评语, 分数) 数据对,用于模型的第一阶段训练。
2. 两阶段训练流程:SFT 冷启动 + RAPO 优化
本文的方法论核心是一个创新的两阶段训练流程:首先通过监督微调 (SFT) 进行冷启动,然后利用相对-绝对策略优化 (RAPO) 进行强化学习。
阶段一:SFT 冷启动与损失函数
此阶段的目的是让模型学习美学评价的基本结构和语言范式,为后续的 RL 优化提供一个高质量的初始策略。它使用 AesCoT 数据集进行训练。
其损失函数是标准的负对数似然损失 (Negative Log-Likelihood Loss),公式如下:
公式说明:
- 代表 MLLM 模型的参数。
- 是通过 AesCoT 流程构建的高质量数据集。
- 是从数据集中采样的一个样本,分别代表 Prompt、图像、专家的评语 (critique) 和真实美学分数 (score)。
- 是模型在给定 Prompt 和图像 的条件下,生成真实评语 和分数 的概率。
- 优化目标: 训练的目标是最小化该损失函数 。直观地讲,就是调整模型参数 ,使得模型能够以尽可能高的概率生成与数据集中的专家评语和分数一致的输出。
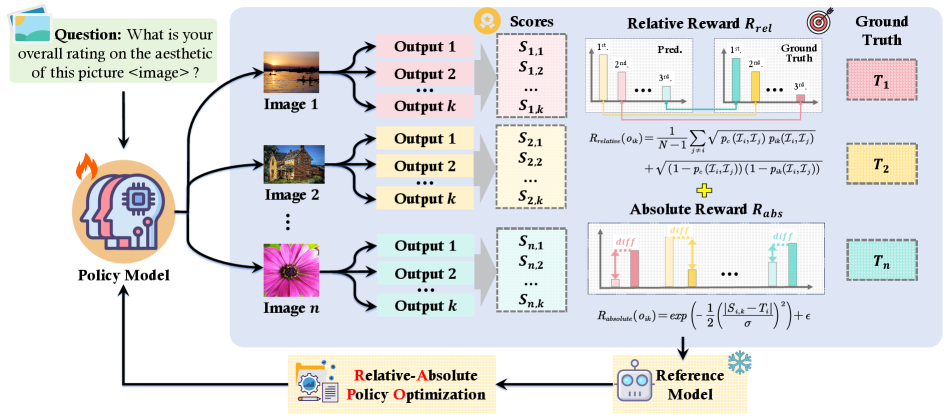
阶段二:RAPO 强化学习与优化目标
在 SFT 的基础上,此阶段通过更精细的奖励信号来进一步提升模型评分的准确性和排序的一致性。该阶段不是最小化一个传统的损失函数,而是最大化一个期望奖励目标函数 。
其核心在于 RAPO 奖励函数 的设计,它由两部分组成:
-
绝对误差奖励 (): 用于校准预测分数的绝对值,使其接近真实分数。
- 是模型对图像 的第 次预测分数, 是其真实分数。
- 是一个超参数,控制奖励对误差的敏感度。
- 这个函数形式使得分数预测越准,奖励越高,且奖励值被平滑地映射到 区间。
-
相对排序奖励 (): 用于优化模型对不同图像进行美学排序的能力。
- 是基于真实分数的二进制偏好(如果图像 的分数高于 ,则为1,否则为0)。
- 是模型预测的图像 优于图像 的概率。
- 该公式衡量了模型预测的偏好排序与真实偏好排序之间的一致性。
总奖励函数是这两部分的简单加和:
最终优化目标: RAPO 采用类似于 PPO (Proximal Policy Optimization) 的算法来最大化以下目标函数 :
公式说明:
- 是新旧策略之间关于动作 的概率比。
- 是优势函数 (Advantage Function),表示在状态 下采取动作 相对于平均预期的好坏程度。优势值由总奖励 计算得出。
- 和 函数是 PPO 算法的核心,通过裁剪概率比来限制单次更新的步长,防止策略剧烈变化,从而稳定训练过程。
- 是一个 KL 散度惩罚项,它确保更新后的策略 不会与某个参考策略 (通常是 SFT 后的模型)偏离太远,有助于保持生成文本的流畅性和多样性。
综上所述,RAPO 阶段通过最大化一个精心设计的、结合了绝对准确度和相对一致性的奖励目标,来驱动模型学习更深层次、更精准的美学判断能力。
3. 实验结果
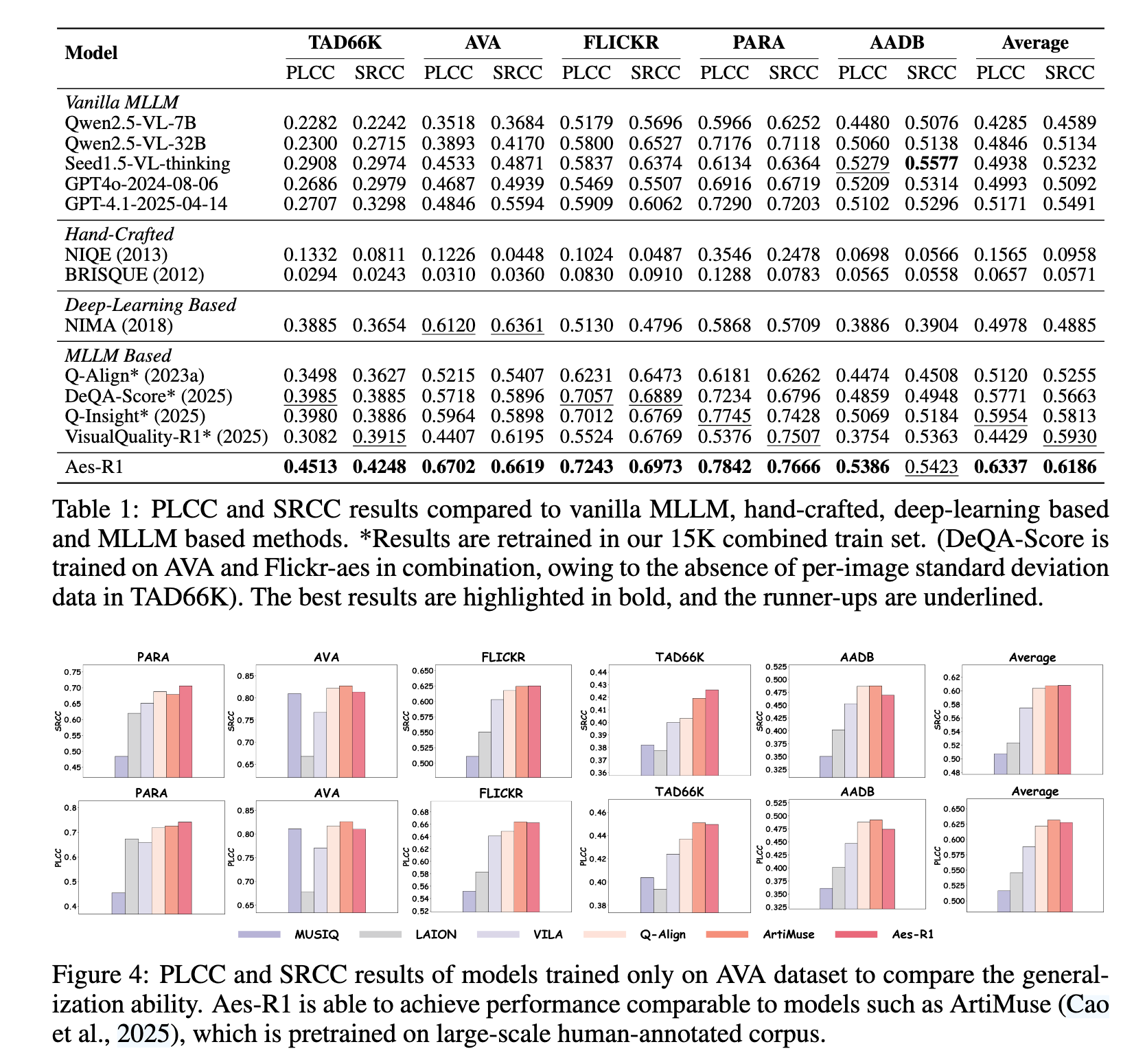
-
数据集: 使用了五个公开的IAA数据集,包括 TAD66K, AVA, FLICKR-AES (用于域内训练和测试),以及 PARA, AADB (用于跨域/OOD泛化能力测试)。
-
骨干模型: Qwen-2.5-VL-7B-Instruct。
-
评估指标:
- PLCC (皮尔逊线性相关系数): 衡量预测分数与真实分数的线性相关性,反映绝对分数的准确性。
- SRCC (斯皮尔曼等级相关系数): 衡量预测分数的排序与真实分数的排序的一致性,反映相对排序的准确性
-
主要结果:
- SOTA 性能: 在所有五个数据集的平均表现上,Aes-R1 的 PLCC (0.6337) 和 SRCC (0.6186) 均显著高于所有基线模型,证明了其方法的优越性。
- 泛化能力: 在OOD数据集(PARA, AADB)上,Aes-R1 同样表现最佳,说明其学习到的美学知识是可泛化的,而不仅仅是记住了训练数据的分布。
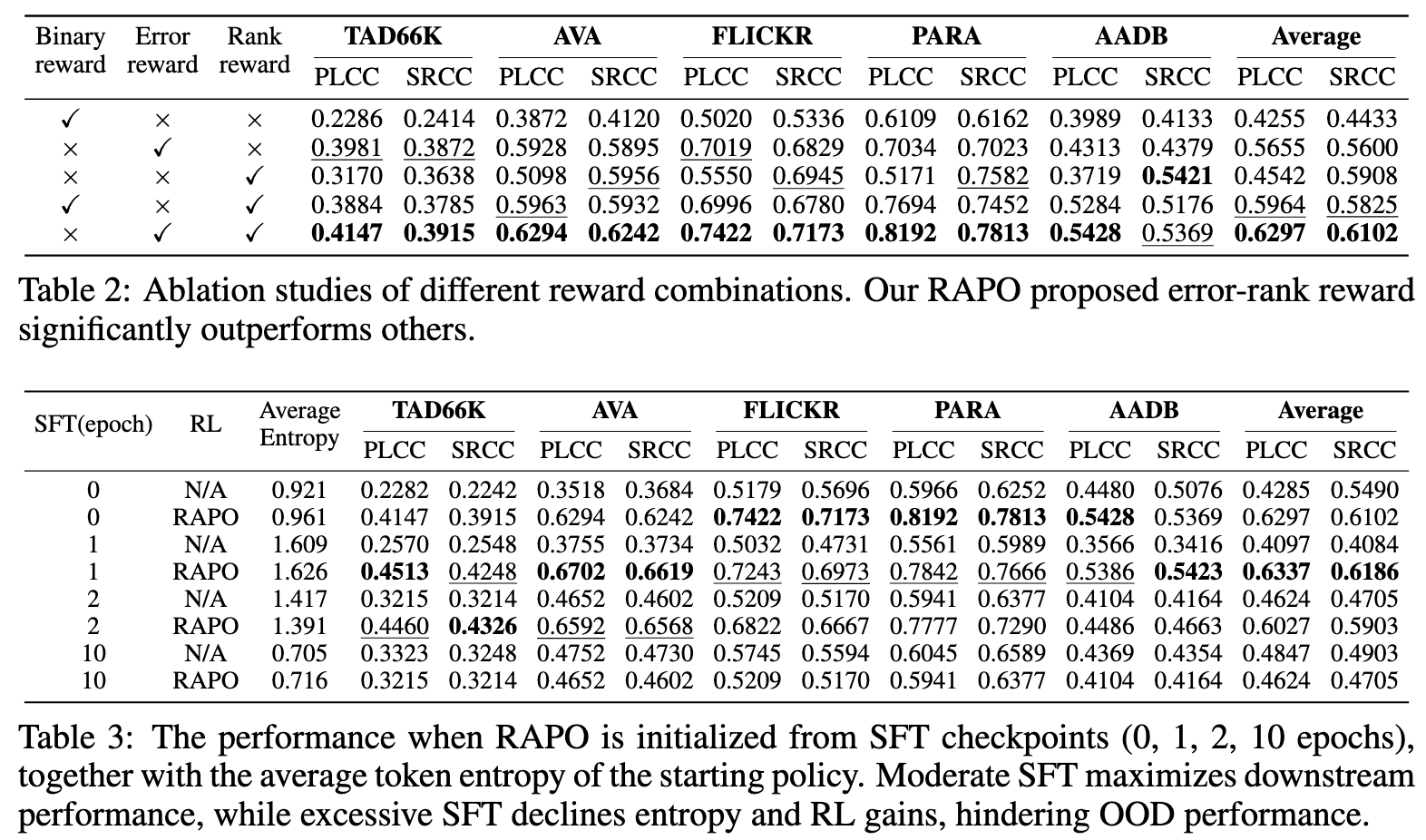
- 消融实验:
- 奖励函数分析: 实验证明,单独使用排序奖励或误差奖励都无法达到最佳效果。排序奖励能带来高SRCC但低PLCC,误差奖励则相反。只有将两者结合(即RAPO),才能同时在两个指标上取得最优性能。
- SFT 和 RL 的作用分析:
- 从零开始进行RL训练(0 SFT epoch),效果不佳,且评语质量差。
- 进行过度的SFT(如10个epoch)会导致模型“熵塌陷”(即过拟合),思维僵化,后续RL训练的收益很小。
- 最佳策略: 进行适度的SFT(1个epoch)为模型注入必要的美学先验知识,同时保持较高的策略熵(探索空间),此时再进行RAPO优化,能够取得最佳的性能。
4. 总结
适用于我们的 benchmark,但模型暂未开源