一句话总结:本文通过构建一个覆盖11类任务的大规模高质量数据集,训练了一个结合多模态大语言模型(MLLM)理解能力和扩散模型(DiT)生成能力的SOTA通用图像编辑模型Step1X-Edit。
1. 总体介绍
1.1 论文背景
- 背景: 基于自然语言指令的图像编辑是一个重要且有挑战性的研究方向。尽管扩散模型极大地提升了图像生成质量,但现有的模型(通常是CLIP文本编码器+扩散网络)在精确理解和执行复杂、细微或组合式的编辑指令方面仍存在困难,难以很好地保持原图的一致性。
- 当前问题
- 性能鸿沟: 顶级多模态模型展示了惊人的编辑能力,但都为闭源
- 数据质量瓶颈: 缺乏足够高质量、大规模和多样化的训练数据
1.2 论文贡献
- 本文的解决方案与贡献:
- 构建高质量数据集: 首先,他们识别并定义了11个主流的图像编辑任务类别。然后,设计了一个复杂且可扩展的数据生成流水线,用以产生超过百万对的高质量“原图-指令-目标图”三元组数据。
- 提出Step1X-Edit模型: 基于海量的高质量数据,他们提出了一个新的统一编辑模型 Step1X-Edit,结合了 MLLM 与 DiT
- 开发新的评估基准: 收集了大量真实世界的用户编辑请求,构建了一个名为 GEdit-Bench 的新基准。
2. Method
2.1 数据流水线
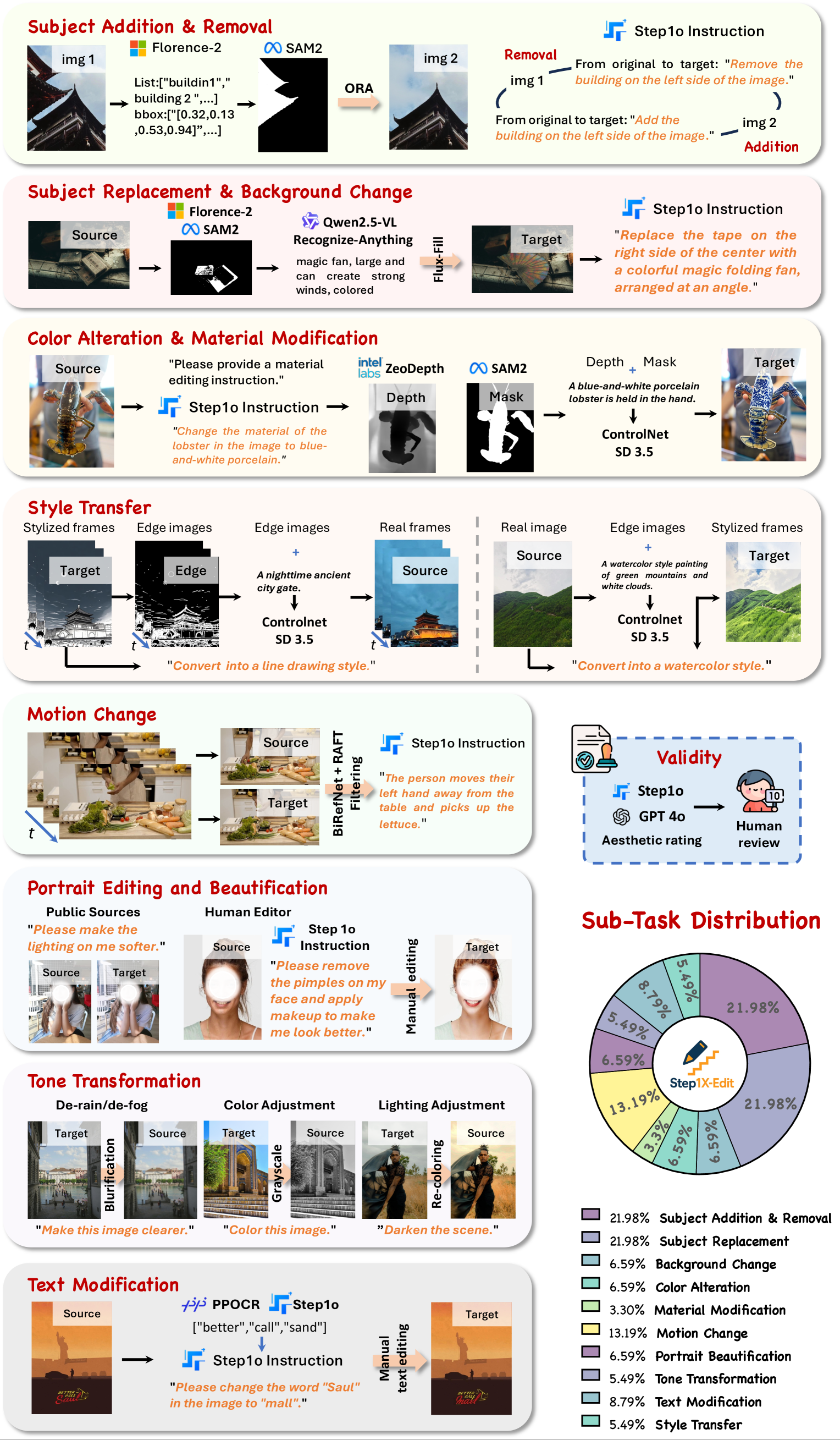
- 为11个不同的任务类别设计了专门的数据生成流程,并大量使用了现有的SOTA工具模型,最后辅以人工审核。
- 主体添加/移除: 使用 Florence-2 进行目标检测,SAM-2 进行分割,再用 ObjectRemovalAlpha 进行内容修复(擦除)。
- 主体替换/背景更改: 使用 Florence-2 进行目标检测,SAM-2 进行分割,使用 Qwen2.5-VL 与 Recognize-Anything 识别物体,再用 Flux-Fill 进行内容感知填充。
- 标注策略: 为了提高指令质量,采用了多轮标注(加强语义一致性)、风格化样例(引导标注风格)和中英双语(增强多语言能力)等策略。
2.2 Step1X-Edit 框架
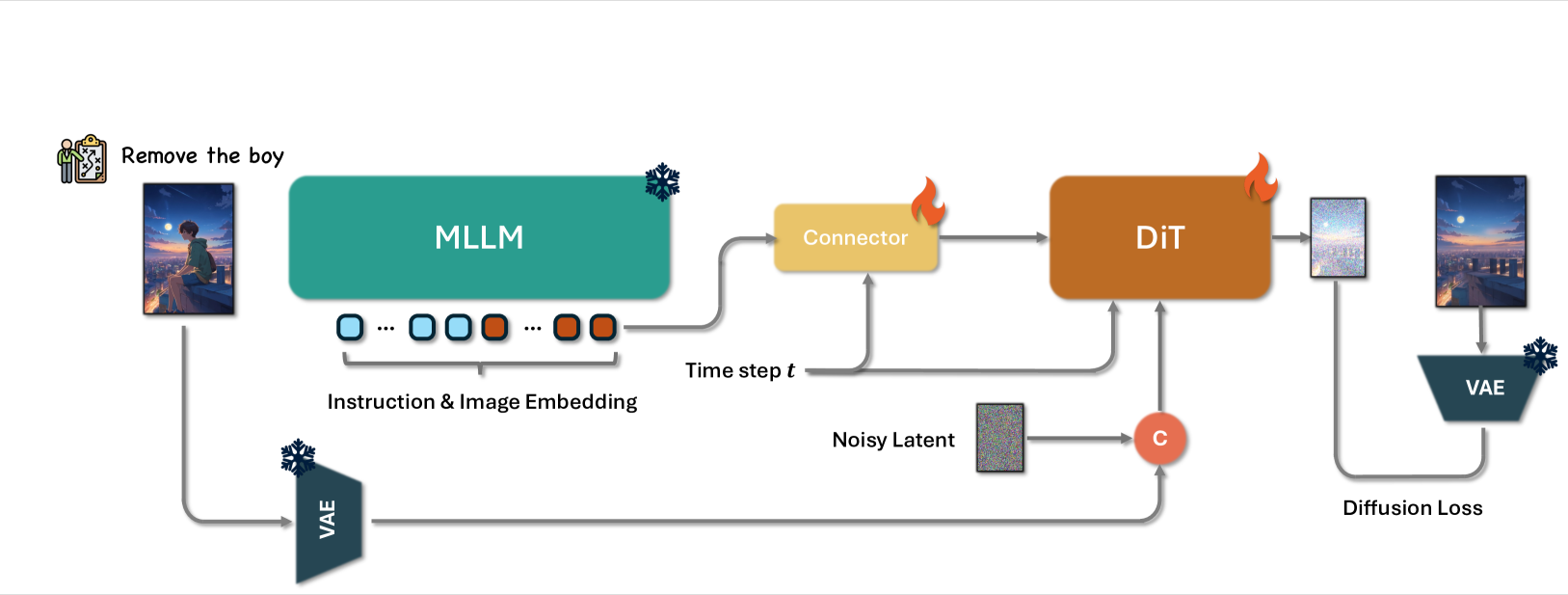
- 模型的架构是“MLLM + Connector + DiT”:
- MLLM编码器: 将参考图像和编辑指令一同输入一个强大的MLLM(如Qwen-VL)。MLLM会进行多模态融合理解,输出一系列代表了编辑意图的token嵌入。
- Connector模块: 因为MLLM与DiT的特征空间不同,这些token嵌入会经过一个轻量级的“连接器”(Token Refiner),该模块负责将 MLLM 的输出特征适配并压缩成更适合下游扩散模型的格式。
- DiT解码器: 连接器输出的特征作为条件(Condition),被注入到DiT(Diffusion in Transformer)网络的每一层中,引导图像的去噪生成过程。
- 原图信息保留: 为了防止编辑过程中原图的结构和细节丢失,他们将原图通过一个VAE编码器得到其latent表示,然后将这个latent表示的token与每一步的噪声Latent在序列维度上进行拼接,再一起送入DiT。这是遵循的3.1.2 Omni-capable token interaction的方法
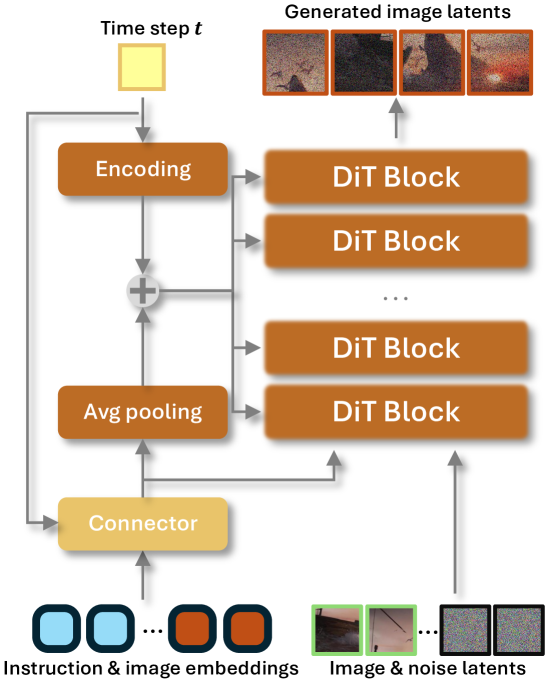
Question
为什么t要连接到Connector
3. 实验/评估/结果
-
实验设置:
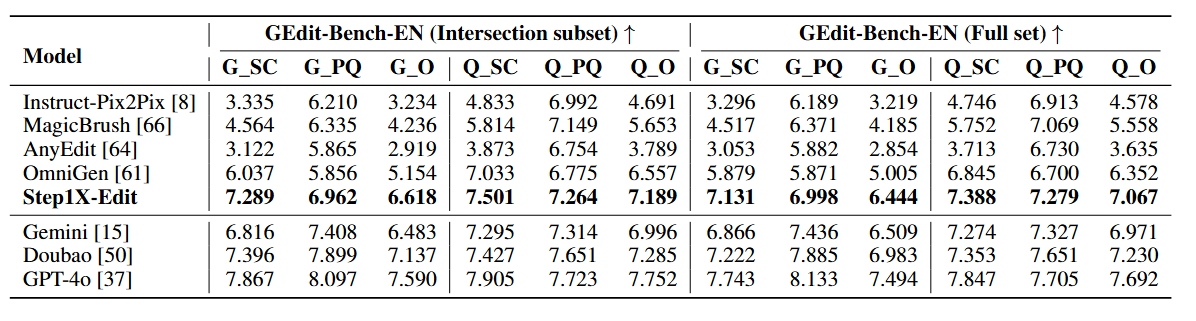
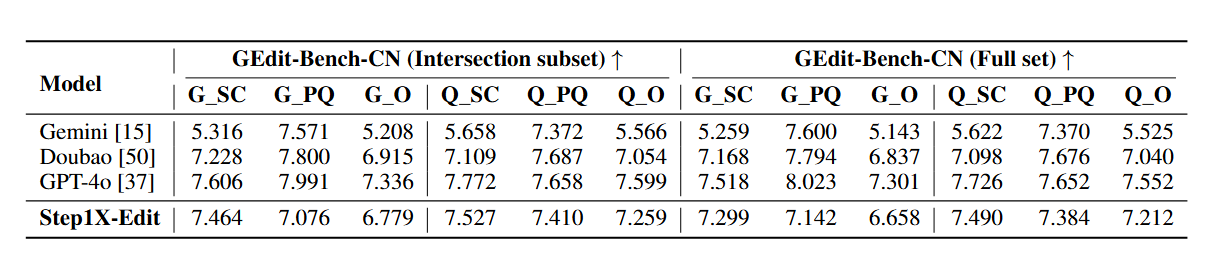
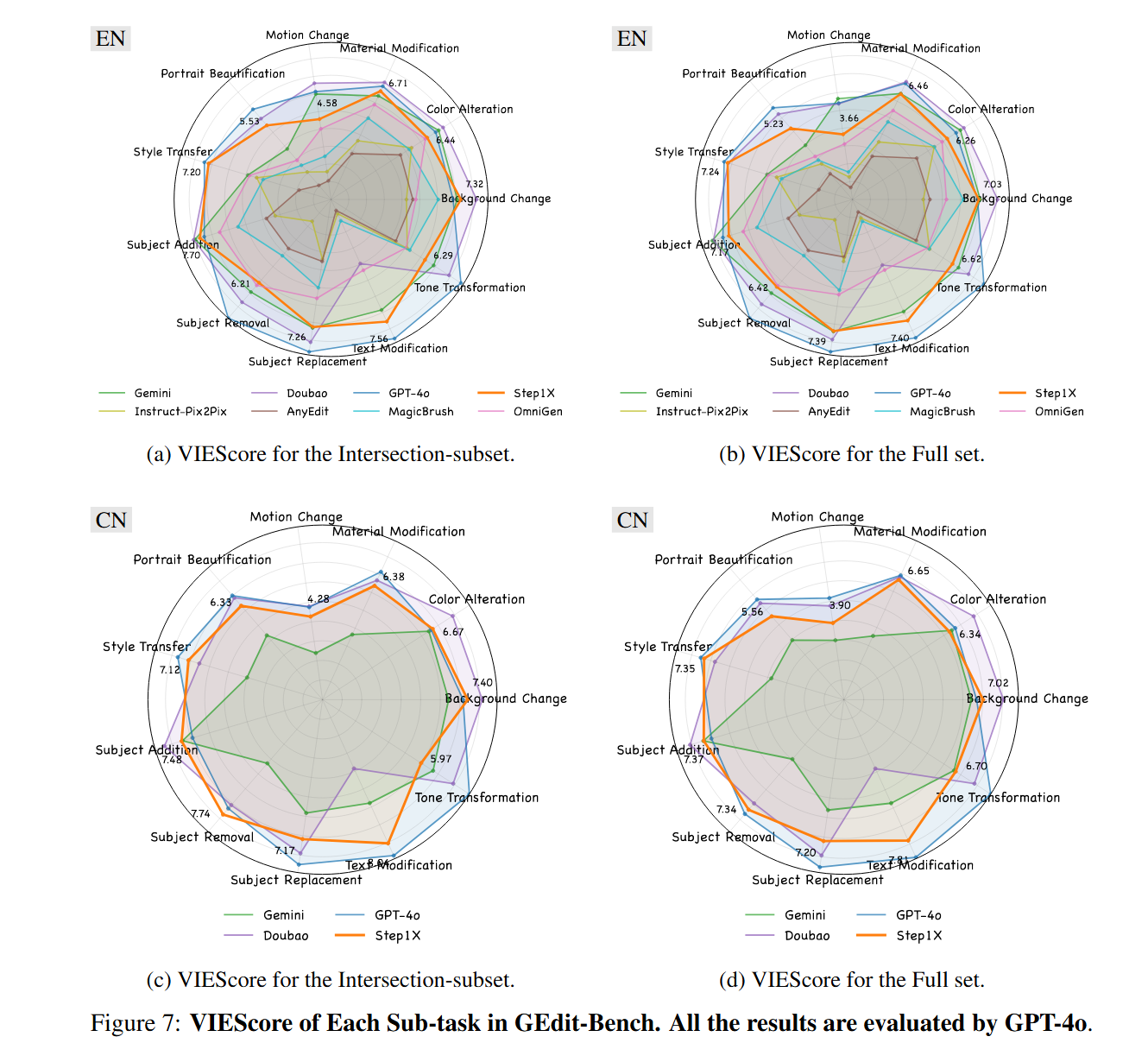
- 基准 (Benchmark): 在自建的 GEdit-Bench 上进行评估。该基准包含606个从真实世界收集并经过隐私处理的测试用例,覆盖11个任务类别,并提供中英双语指令。
- 评估模型: 对比了多种开源模型(Instruct-Pix2Pix, MagicBrush, AnyEdit, OmniGen)和顶级闭源模型(Gemini2 Flash, Doubao, GPT-4o)。
- 评估指标:
-
自动评估: 采用 VIEScore,它包含三个子指标:SQ (Semantic Consistency, 语义一致性,即多大程度上遵循了指令)、PQ (Perceptual Quality, 感知质量,即图像是否自然、有无伪影) 和 O (Overall, 综合得分)。同时使用了GPT-4.1和开源的Qwen2.5-VL来作为打分模型,以保证结果的可靠性和可复现性。
-
-
-
-
人工评估: 招募了55名参与者进行盲评,统计用户偏好度(User Preference, UP)。
-

-
-
实验结果:
- 全面领先开源模型: Step1X-Edit在所有自动评估指标上都显著优于所有被测试的开源模型。
- 媲美闭源模型: 它的性能与 Gemini2 Flash 和 Doubao 相当,在处理中文指令时甚至超越了它们。在某些特定任务上(如风格迁移、颜色变更),其表现甚至超过了GPT-4o。
4. 结论
作者总结道,他们提出了一个全新的通用图像编辑模型 Step1X-Edit,并通过构建一个系统化的数据生成流水线和海量的高质量数据对其进行有效训练。在他们自己提出的、更贴近真实应用的 GEdit-Bench 基准上的全面评估结果表明,他们的模型性能大幅度超越了现有的开源竞品,缩小了与顶级闭源模型之间的差距。
5. 个人总结
这篇文章的收集了大量的数据,使用了大量不同领域的SOTA模型,是一种数据驱动的思路,对于我们研究的细分领域可以借鉴其如何系统性地、大规模地构建高质量训练数据。