本文构建并推出了一个名为 OpenGPT-4o-Image 的大规模、结构化数据集,通过精细的层次化任务分类和基于 GPT-4o 的自动化生成流程,旨在系统性地提升多模态模型在科学图像、复杂指令遵循等多类高级图像生成与编辑任务上的能力。
1. 总体介绍
- 背景:由大型语言模型驱动的统一多模态模型正在改变AI内容创作领域,它们能够根据自然语言指令生成和编辑图像。然而,这些模型的真正潜力被训练数据的质量所限制。
- 当前问题:现有的图像生成和编辑数据集存在明显短板。无法处理复杂的编辑任务
- 现有方法:现有数据集要不使用指令较差,或者依赖人工无法规模化。即使是使用GPT-4o生成的 ShareGPT-4o-Image,其任务分类也相对粗糙,限制了模型在特定能力上的针对性训练和评估。
- 本文的解决方案与贡献:
- 构建 OpenGPT-4o-Image 数据集:一个包含80k高质量“指令-图像”对的大规模数据集,旨在系统性地解决上述问题。
- 主要贡献:
- 提出一个分层的任务分类体系:将复杂的图像生成和编辑任务分解为11个主领域和51个细粒度的子任务。生成任务包括科学图像等新领域;编辑任务包括复杂指令编辑和多轮编辑等高级形式。
- 开发一个自动化的数据生成管线:利用 GPT-4o 的强大能力,结合结构化模板和资源池,可扩展地生成多样化、高质量的训练数据,并能控制难度。
- 全面的实验验证:在四个主流模型和四个权威基准上进行实验,证明了使用该数据集进行微调可以普遍且显著地提升模型的图像生成和编辑能力。
2. Method
本文的方法核心是其系统化的数据构建流程,分为任务定义和自动化生成两个阶段。
1. 图像生成任务定义 (Generation Type Definition)

共包含5个大类,旨在全面覆盖模型的生成能力:
- 风格控制 (Style Control, 13k):包含艺术传统(印象派、浮世绘)、媒体插画(吉卜力、像素风)、摄影风格和幻想风格(赛博朋克)等。
- 复杂指令遵循 (Complex Instruction Following, 6k):测试模型对多约束、复杂逻辑的理解。包括多属性组合、多主体互动、复杂空间布局、时序连贯性以及因果关系推理。
- 图像内文本渲染 (In-Image Text Rendering, 3k):包括文本准确性、排版(字体控制)、结构化文本布局(菜单)、图文融合以及多语言支持。
- 空间推理 (Spatial Reasoning, 8k):关注几何和逻辑关系。包括相对位置、物体计数、尺寸推理、对称性分析等。
- 科学图像 (Scientific Imagery, 10k):填补了专业领域数据的空白。涵盖数学、物理、机械工程、天文学、生物学、生态学等,用于知识可视化和科学交流。
2. 图像编辑任务定义 (Edit Type Definition)

共包含6个大类和21个子任务,覆盖了广泛的编辑场景:
- 主体操作 (Subject Manipulation, 19k):经典的局部编辑,包括添加、移除、替换、修改(Alter,仅改变属性)和物体提取。
- 文本编辑 (Text Editing, 3k):对图像内嵌入的文本进行增、删、改、替换。
- 复杂指令编辑 (Complex Instruction Editing, 4k):单条指令包含2到4个子编辑操作,极大考验模型的指令遵循能力。
- 多轮编辑 (Multi-turn Editing, 1.5k):模拟用户与模型的连续交互,通过2-4轮对话逐步修改图像。
- 全局编辑 (Global Editing, 5k):包括背景替换和11种不同的风格迁移(如赛博朋克风、手绘风)。
- 其他挑战性编辑 (Other Challenging Editing, 8k):包括参考图编辑(将参考图中的物体无缝融入)、动作修改、材质变换和物体移动。
3. 自动化数据集构建流程 (Automatic Dataset Pipeline)
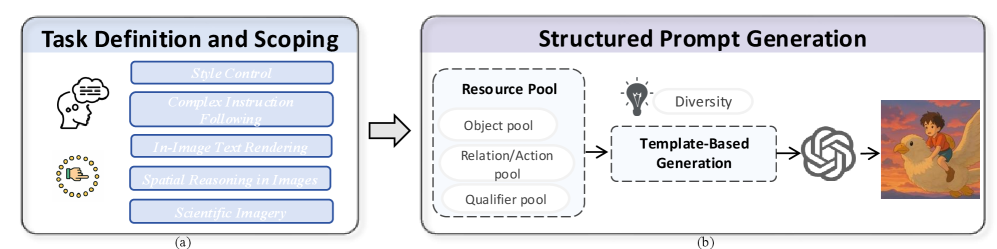
- 对于图像生成:
- 任务定义与范围界定:首先精确定义每个子模块的目标能力,并设立严格边界(如“相对位置”模块只关注平面关系,不涉及3D透视)。然后进行层次化分类和难度分级。
- 结构化提示词生成:构建包含物体、关系/动作、修饰词的资源池。然后使用多样化的句法模板,从资源池中随机采样填充,大规模生成结构一致且语言丰富的指令。
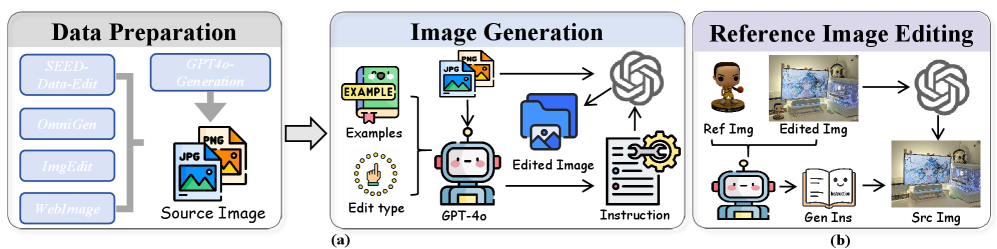
- 对于图像编辑:
- 数据准备:整合多个高质量数据集(如 SEED-Data-Edit, ImgEdit, OmniEdit)以及 GPT-4o 生成的图像作为初始源图像,确保源图质量高、种类广。
- 指令生成:向 GPT-4o 提供源图像、编辑类型和少量上下文示例(in-context examples),引导其生成多样化且高质量的编辑指令。
- 图像生成:使用 gpt-image-1 API 执行编辑指令,生成最终的编辑后图像。对于多轮编辑,逐步生成每一轮的结果。
实验/评估/结果
-
实验设置:
- 基线模型:选取了四种有代表性的模型进行微调:UniWorld-V1, Harmon, OmniGen2, MagicBrush。
- 评测基准:使用了四个公认的基准。生成任务使用 GenEval(评估组合性)和 DPG-Bench(评估语义对齐)。编辑任务使用 GEdit-Bench 和 ImgEdit-Bench(评估复杂指令编辑)。
-
主要结果:
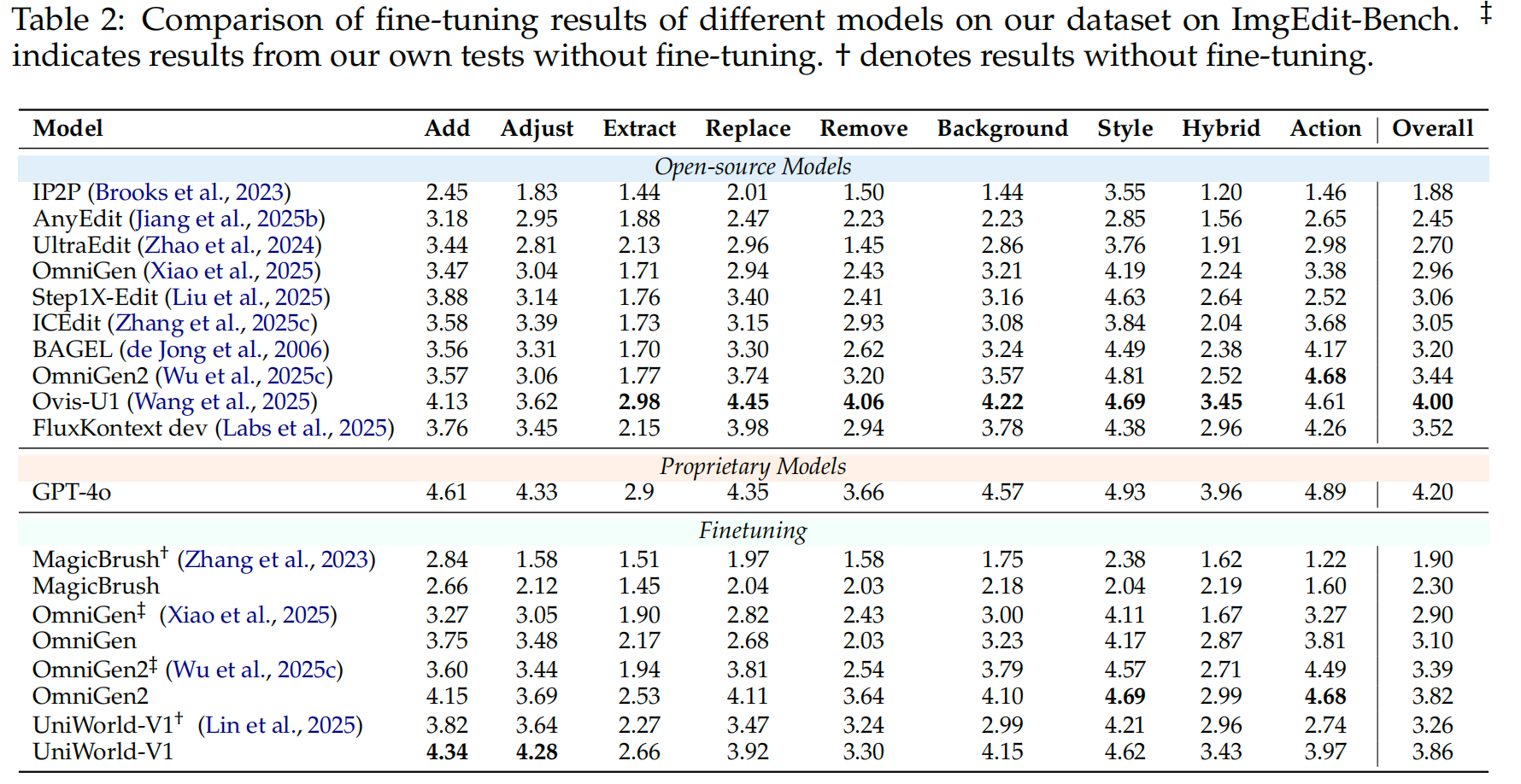
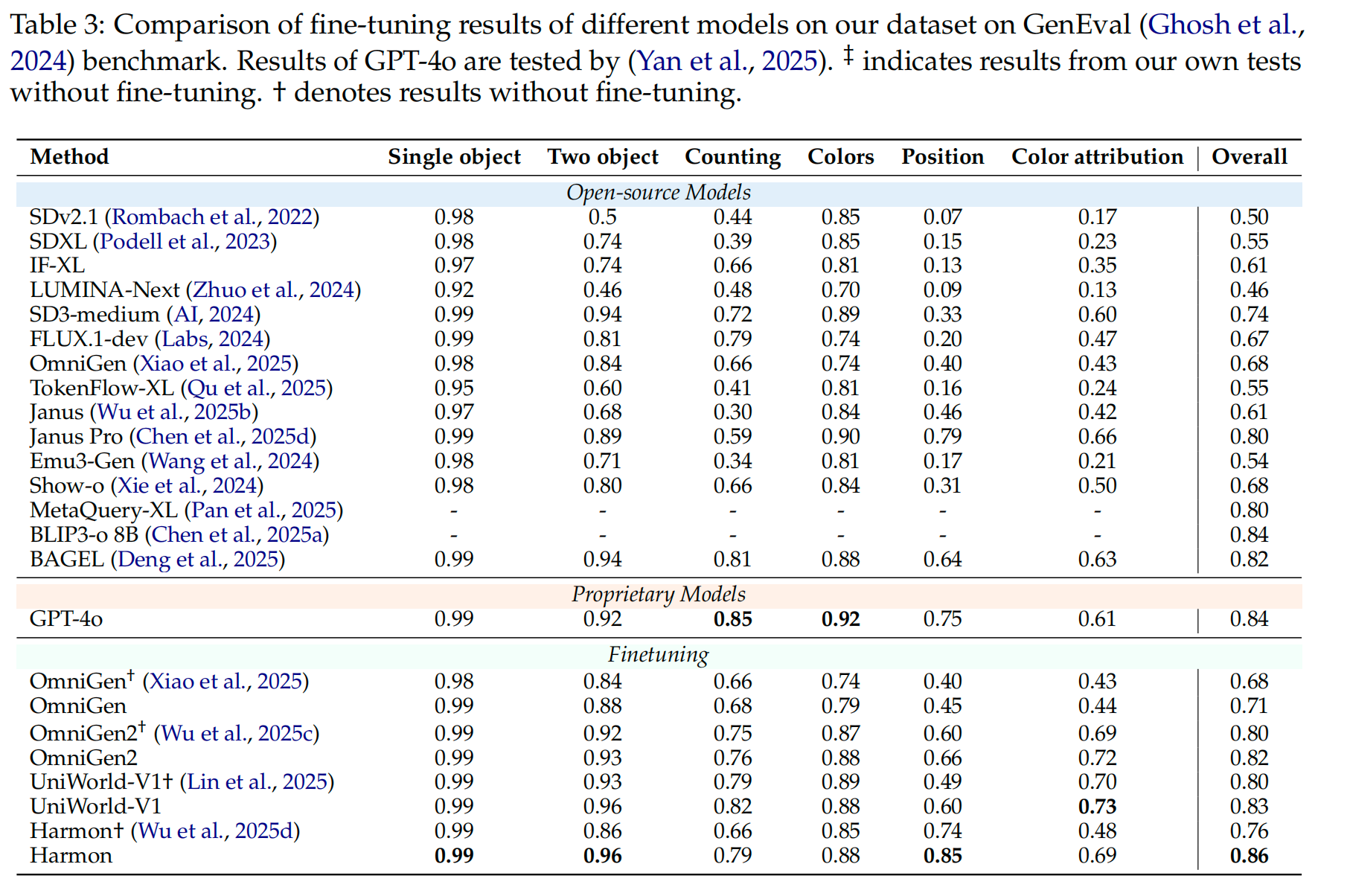
- 数据规模实验:在20k、30k、40k三个规模的数据集子集上进行实验,结果显示随着数据量增加,模型性能持续稳定提升,验证了数据集的有效性。最终选取40k作为主要实验规模。
- 编辑模型性能提升:在 OpenGPT-4o-Image 上微调后,所有模型的编辑能力都得到巨大提升。例如,UniWorld-V1 在 ImgEdit-Bench 上相对提升了18.4%;MagicBrush 在 GEdit-Bench 上提升了21.7%。
- 生成模型性能提升:所有生成模型也表现出显著的性能增长。Harmon 在 GenEval 上性能激增13.2%,在 DPG-Bench 上提升了5.3%。这证明了数据集对于提升模型精确遵循复杂指令的能力至关重要。
- 与同期工作的对比:在相同的设置下,使用 OpenGPT-4o-Image 微调的 UniWorld-V1 在所有四个基准上都优于使用 ShareGPT-4o-Image 微调的模型,证明了其更精细的分类和更高质量的指令带来了更好的效果。