一句话总结:本文提出了一种创新的方法,通过结合大型语言模型(GPT-3)和文本到图像模型(Stable Diffusion)来自动生成一个大规模成对的图像-编辑指令-编辑后图像数据集,并用该数据集训练了一个能够直接根据用户文字指令来编辑真实图像的条件扩散模型(InstructPix2Pix)。
总体介绍
1.1 问题背景
-
背景与问题:对于文本编辑图像,现有方法要求提供完整描述。原因是缺少原图-编辑指令-编辑后图像这样的大规模成对训练数据
-
现有方案与问题:
- T2I模型: 它们可以根据文本生成或修改图像,但难以进行精确和局部的编辑。
- SDEdit等方法: 需要提供完整的“编辑后”描述,而不是编辑指令。
- 其他编辑方法: 可能需要用户提供掩码(mask)或者局限于特定的编辑类型(如风格迁移)。
1.2 论文贡献
- 提出了一种自动生成配对训练数据的方法:通过巧妙地组合两个预训练好的大模型(GPT-3和Stable Diffusion),自动化地创建了一个包含超过45万个样本的图像编辑数据集。
- 提出了InstructPix2Pix模型: 基于生成的数据集,训练了一个条件扩散模型。该模型能够接收一张任意的真实图像和一句人类指令,并直接在前向传播中完成编辑。
2. Method
2.1 生成多模态训练数据集
 这个阶段的目标是自动创建一个大规模的输入图像、编辑指令、输出图像三元组数据集。
生成文本三元组:
这个阶段的目标是自动创建一个大规模的输入图像、编辑指令、输出图像三元组数据集。
生成文本三元组:
- 首先,人工构建了一个包含700个样本的小型数据集。每个样本包含一个从LAION数据集中抽取的真实图像标题(作为输入描述)、一句手写的编辑指令,以及一个手写的编辑后标题(输出描述)。
- 然后,使用这个小型数据集对GPT-3 Davinci模型进行微调(fine-tuning)。
- 使用这个微调后的模型,以LAION数据集中的真实标题作为输入,生成了超过45万组这样的文本三元组,构建了一个庞大的文本编辑指令库。
生成配对图像:
采用了Prompt-to-Prompt技术,该技术通过在生成两张图片时共享注意力权重,来确保由相似文本生成的图像在结构和内容上保持高度一致。将上一步生成的文本标题对输入描述、输出描述转化为对应的图像对输入图像、输出图像。
使用CLIPdir来筛选
2.2 训练InstructPix2Pix模型
基础模型:InstructPix2Pix基于预训练的Stable Diffusion模型。
接受图像输入:将输入图像通过VAE编码器得到其潜在表示,然后将其与带噪声的潜在表示在通道维度上拼接,作为新的输入。
双重条件的无分类器引导
- 核心思想: 模型在推理时需要同时考虑两个条件:输入图像和文本指令。为了能灵活地控制这两个条件的影响力,作者扩展了标准的无分类器引导(CFG)机制。
- 训练策略: 在训练过程中,以一定概率随机地将某个条件或两个条件都置为空(Ø)。例如,有5%的样本只使用图像条件,5%只使用文本条件,5%两个都不使用。这使得模型学会了在有或没有某个条件的情况下去噪。
- 推理控制: 在推理时,引入两个独立的引导尺度(guidance scales):s_I控制生成图像与输入图像的相似度,s_T控制与文本指令的一致性。修改后的分数估计公式如下:
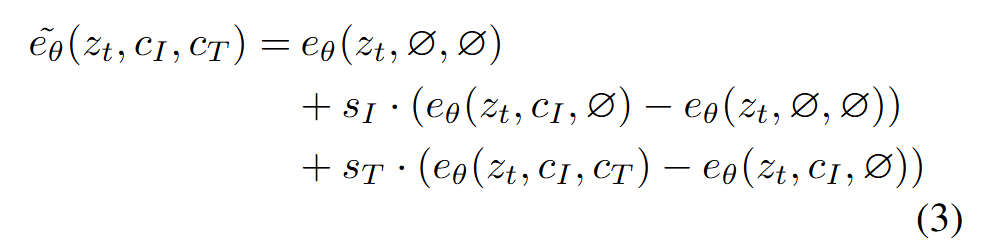
2.3.3 Classifier-Free Guidance (CFG) 策略
3. 实验/评估/结果
3.1 实验设置
评估数据集:各种真实的摄影作品和艺术品
基线模型: SDEdit和Text2Live。
评估指标:CLIP Text,CLIP Image
3.2 实验结果
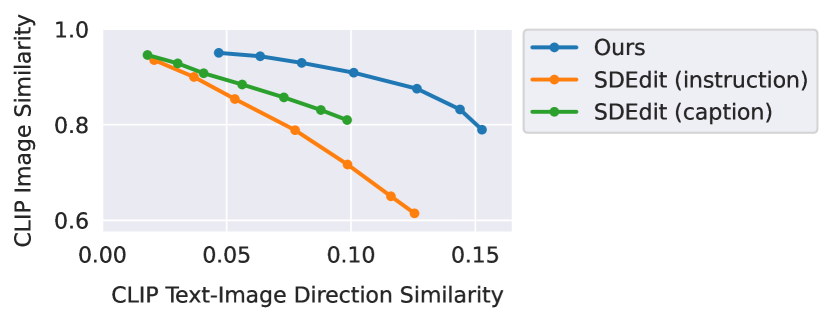
实验结果表明,在达到相同的“编辑一致性”水平时,InstructPix2Pix生成的图像能更好地保持与原图的“内容一致性”,即它的编辑更加精准,不会对无关区域造成不必要的改动。
3.3 消融实验
-
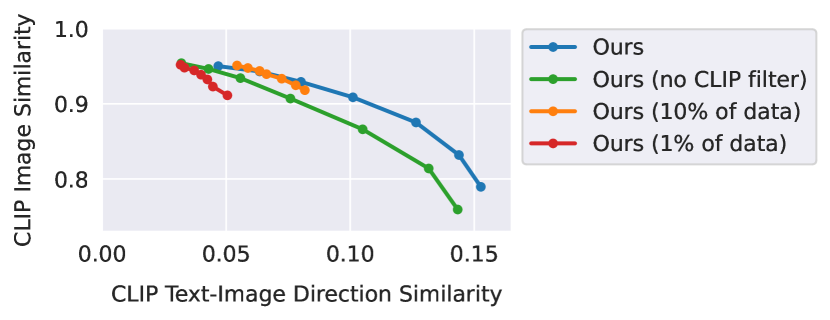
减少训练数据量(例如只用10%或1%)会削弱模型进行大幅度编辑的能力,使其倾向于只做微小的风格调整(方向相似度得分较低)。
-
移除数据集生成过程中的CLIP过滤步骤,会导致模型在保持与原图一致性方面的表现下降(“Ours (no CLIP filter)”曲线整体偏下)
4. 结论
- 总结: 作者成功地展示了一种结合大型语言模型和文本到图像模型来生成训练数据的方法,并基于此训练了一个强大的指令驱动图像编辑模型。该模型在各种编辑任务上都取得了引人注目的结果。
- 局限性:
- 模型的质量受限于其所依赖的GPT-3和Stable Diffusion的质量。
- 模型在处理需要精细空间推理的指令时表现不佳,例如“把物体移动到左边”或精确计数。
- 模型会继承并可能放大预训练模型中存在的社会偏见(如职业和性别的刻板印象)。