本文通过构建一个大规模、高质量的图像编辑数据集 ImgEdit 和一个全面的评测基准 ImgEdit-Bench,旨在缩小开源和闭源图像编辑模型之间的差距,并推动该领域的发展。
1. 总体介绍
1.1 问题背景
- 背景: 更实用、更具挑战性的图像编辑任务是一个难点,用户希望能够对现有图像进行精确的局部或全局修改。
- 当前问题:
- 数据质量和提示设计欠佳:现有数据集通常分辨率低、编辑指令简单、编辑区域过小或编辑效果不真实。
- 对复杂编辑任务的支持不足:很少有数据集包含需要保持身份一致性、同时操作多个对象或进行多轮连续交互的复杂任务。
- 评测基准有限:现有的评测基准要么过于简单,要么评估维度单一,无法准确衡量模型的真实能力。
1.2 论文贡献
- 本文贡献:
- 全新的数据集 (ImgEdit):一个包含 120 万个图文对的大规模、高分辨率、高质量数据集,覆盖 10 种单轮编辑任务和 3 种新颖的多轮交互任务。
- 可靠的基准 (ImgEdit-Bench):一个全面的评测基准,从基础、挑战和多轮三个维度评估模型在指令遵循、编辑质量和细节保留等方面的能力。
- 先进的模型 (ImgEdit-E1 & ImgEdit-Judge):训练并发布了一个在多项任务上超越现有开源模型的编辑模型 ImgEdit-E1,验证了其数据集的有效性。同时,他们还发布了一个与人类偏好对齐的评估模型 ImgEdit-Judge。
2. Method
2.1 ImgEdit
2.1.1 编辑类型定义
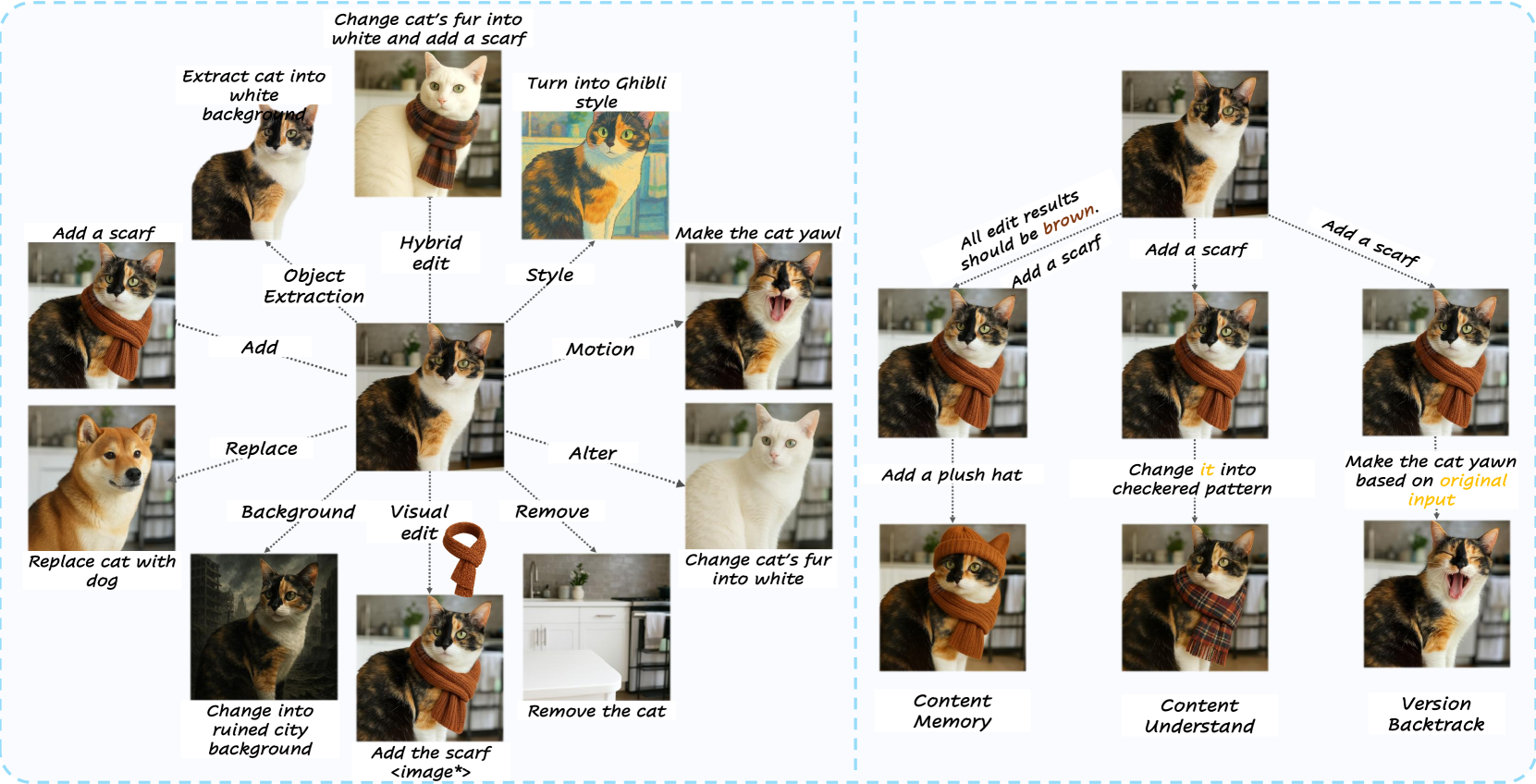
编辑任务划分为两类:
- 单轮任务包括添加、移除、替换、修改、背景变更、动态调整、风格化、对象提取、视觉编辑及混合编辑。
- 多轮任务涵盖内容记忆、内容理解与版本回溯。
2.1.2 自动化数据流水线
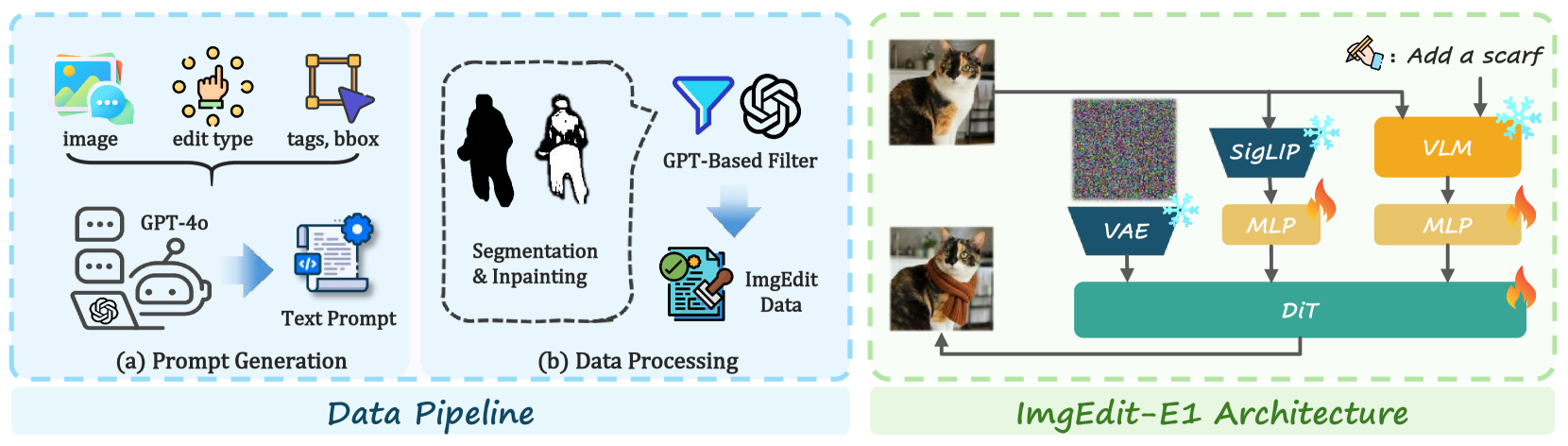
- 数据准备: 从LAION-Aesthetics数据集中筛选出短边超过1280像素且美学评分高于4.75的60万张高质量图像。
- 目标定位与分割: 使用GPT-4o生成图像标题和可编辑对象,再通过开放词汇检测器(YOLO-World)和分割模型(SAM2)获得物体的精确边界框和掩码。
- 指令生成: 将图像、编辑类型、目标位置等信息输入GPT-4o,生成高质量、多样化且具有空间意识的编辑指令。
- 图像修复工作流: 针对每种编辑任务,使用最先进的生成模型(FLUX、SDXL)及插件(IP-Adapter、ControlNet)构建专用的修复流程以生成高质量的编辑后图像。
- 后处理与过滤: 再次使用GPT-4o,根据为每种任务设计的评分标准(Rubric)对生成的编辑对进行打分,剔除质量不高的样本,确保最终数据集的可靠性。
2.2 ImgEdit-E1
- 模型架构: 如它集成了三个关键部分:一个视觉语言模型(Qwen2.5-VL-7B)作为文本和图像编码器,一个纯视觉编码器(SigLIP)提供底层视觉特征,以及一个DiT模型(FLUX)作为生成骨干。
- 工作流程: 编辑指令和原始图像共同输入VLM,同时原始图像也输入SigLIP。VLM的隐藏状态和SigLIP的视觉特征经过MLP投影后拼接在一起,作为文本分支的输入送入DiT,指导扩散模型进行精确编辑。
- 训练策略: 采用两阶段训练:第一阶段,冻结VLM和FLUX,只训练连接它们的MLP;第二阶段,联合微调FLUX和MLPs,以实现模型各部分的深度融合。
2.3 ImgEdit-Bench
-
基准构建: 包含三个部分:
- 基础编辑套件: 覆盖9个常见的编辑任务,共734个由人工筛选的测试用例。
- 理解-定位-编辑(UGE)套件: 包含47个精心挑选的复杂场景图像,其编辑指令要求模型具备空间推理、多目标协同等高级能力。
- 多轮编辑套件: 针对内容记忆、理解和回溯三个维度,每个维度设计了10个贴近真实世界用例的测试样本。
-
评估指标: 采用GPT-4o从三个维度进行1-5分打分:指令遵循度、图像编辑质量和细节保留度。此外,引入了伪造分数(Fake Score),使用最新的伪造图像检测器来量化生成图像的真实感。
-
评估模型(ImgEdit-Judge): 作者 fine-tune 了一个Qwen2.5-VL模型作为开源评估器,该模型在20万条评分数据上训练,与人类偏好的一致性达到了近70%,优于通用的VLM。
3.实验/评估/结果
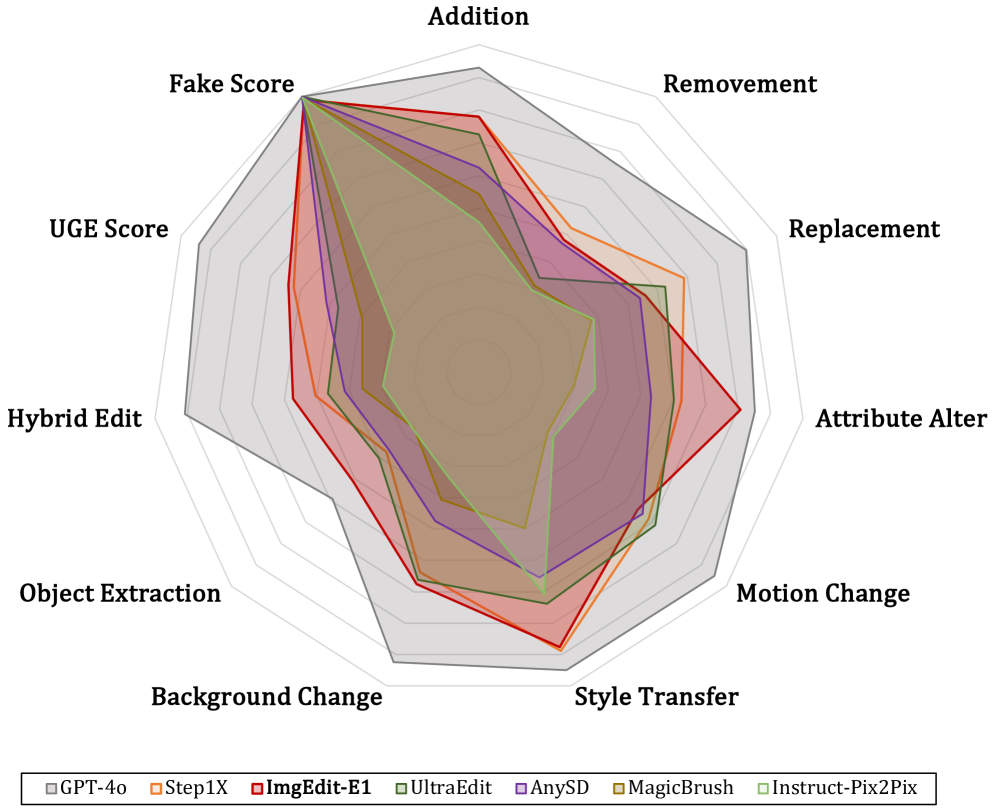
3.1 定量结果
- 从雷达图可以看出,GPT-4o在所有任务上都大幅领先于开源模型,特别是在需要深度理解和定位的UGE任务上。
- 在所有开源模型中,ImgEdit-E1和Step1X-Edit表现最佳。得益于高质量的训练数据,ImgEdit-E1在物体提取和混合编辑等新颖任务上尤为突出。
- 其他模型由于训练数据或模型设计的局限性,在特定任务上表现不佳(如UltraEdit不擅长移除任务)。
- 对于多轮编辑,即便是GPT-4o和Gemini也仅表现出有限的能力,说明这仍然是一个开放性难题。
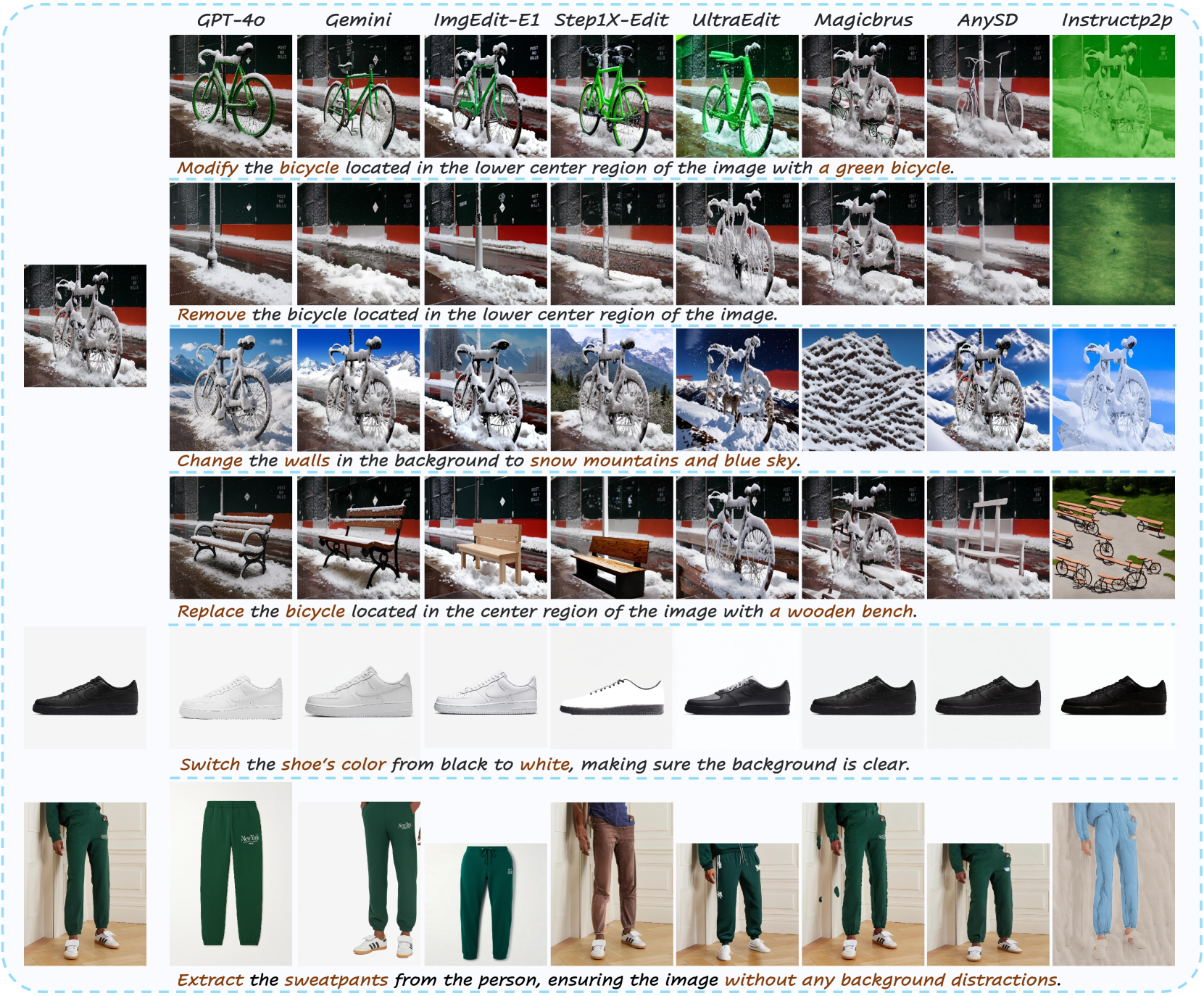
3.2 定性结果
4. 结论
本文通过引入 ImgEdit 推动了图像编辑领域的发展,该数据集克服了现有数据集在数据质量方面的局限性,提出了实用的编辑分类体系,并为未来数据集构建提供了稳健的流程框架。ImgEdit-E1 的优异表现验证了该数据集的可靠性。此外,ImgEdit-Bench 从创新维度对模型进行评估,为图像编辑模型的数据筛选和架构设计提供了重要洞见。通过提供高质量数据集、强大编辑方法和全面评估基准,我们相信本研究有助于缩小开源方案与闭源前沿模型之间的差距,并将推动整个图像编辑领域的进步。
5. 个人总结
作者提供了一个完整的解决方案:数据生成流程、数据集、模型和评测基准,工作量很扎实 但感觉过度依赖GPT4o,从数据生成到评估都依靠GPT4o,会不会导致最终衡量的仍是“一个模型在多大程度上能模仿GPT-4o的编辑偏好”存疑