推出 AnyEdit——一个包含 250 万高质量编辑对的多模态指令编辑数据集,涵盖 20 余种编辑类型和五大领域,提出了 AnySD 模型,引入了moe架构
1. 总体介绍
1.1 问题背景
尽管现有方法在某些特定编辑任务上取得了进展,但它们普遍面临以下挑战:
- 数据集质量和多样性不足: 现有数据集(如InstructPix2Pix, MagicBrush)编辑类型有限,难以覆盖现实世界中复杂的编辑需求,比如需要空间感知(如改变视角)、常识理解(如隐式编辑)或参考外部图像(如风格迁移)的指令。
- 数据偏差问题: 现有数据集在构建时忽略了数据内在的偏差。例如,数据集中“骆驼”和“沙子”经常一起出现,导致模型在编辑“公园里的树变成骆驼”时,可能会错误地加入“沙子”这个无关元素。。
1.2 论文贡献
- 我们从全新视角系统化分类各类编辑指令,创新性地提出统一编辑框架,通过自适应编辑流程可扩展地自动收集多场景下的多样化高质量编辑数据。
- 我们构建了多类型、多场景的指令编辑数据集 AnyEdit 及其对应基准测试集 AnyEdit-Test,涵盖 25 种差异化复杂编辑类型,以满足现实编辑场景更广泛的需求。
- 通过提出的 AnySD 方法,我们充分释放 AnyEdit 数据集潜力,在多样化编辑类型中实现指令遵循度与图像保真度的最先进性能提升。
2. 背景知识

3. Method
3.1 AnyEdit 数据集的构建
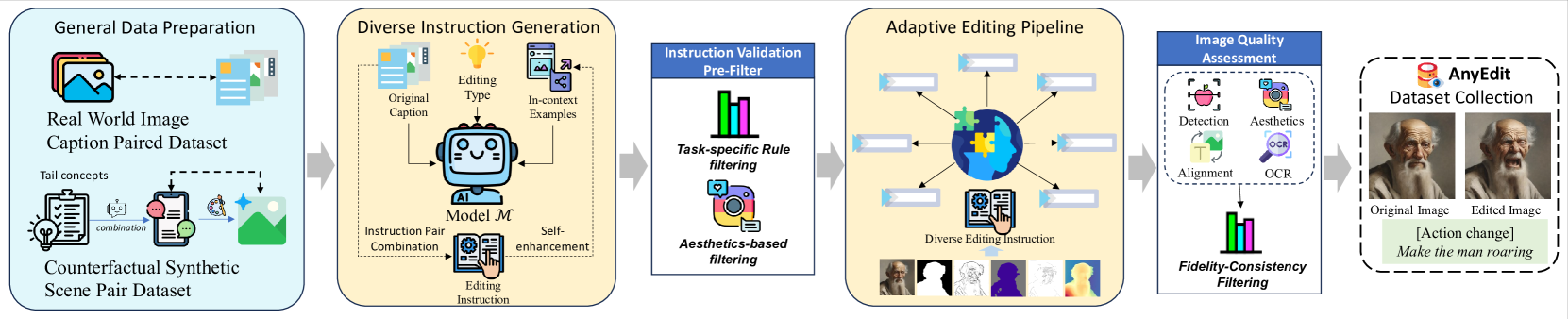
- 步骤一:通用数据准备 (General Data Preparation)
- 真实世界数据: 从 MSCOCO, LLaVA-CC3M 等数据集中收集了约68万张真实的图文对,使用 MLLM 对描述进行扩充
- 反事实合成数据 (Counterfactual Synthetic Scene): 这是为了解决数据偏差问题。首先,从网络数据中收集低频长尾概念,通过 LLaMA-3B[15]模型组合多个概念与上下文生成描述,随后调用现成的文生图模型生成初始图像。
- 步骤二:多样化指令生成 (Diverse Instruction Generation)
- 利用大语言模型(Llama3-8b),将原始图像的描述文字转换为各种编辑指令和编辑后的目标描述。
- 为了提升指令的多样性和质量,作者为每种编辑类型设计了任务特定的代理(task-specific agent),通过提供上下文示例(in-context examples)和类型约束来引导LLM生成高质量指令。
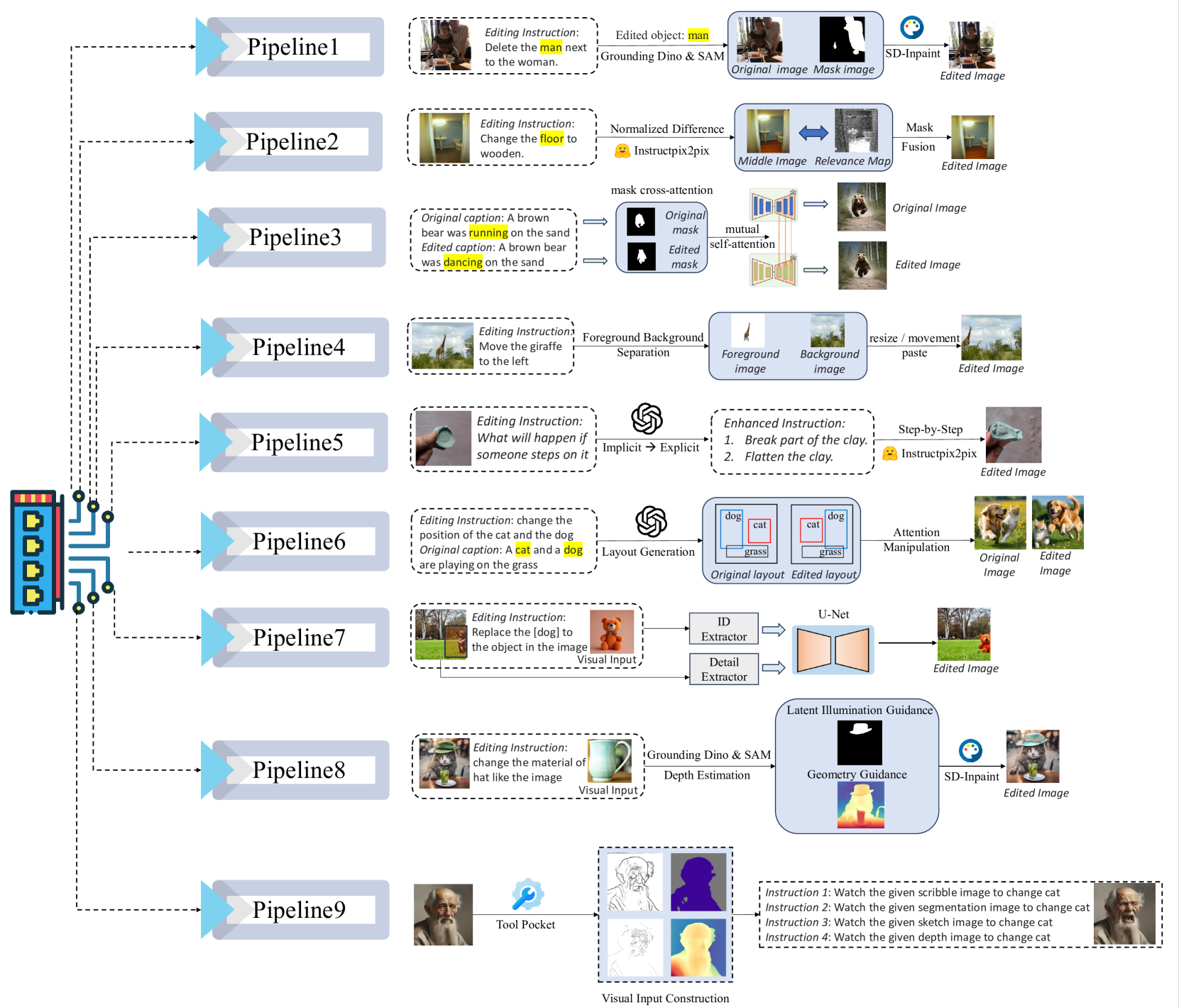
- 步骤三:自适应编辑管线 (Adaptive Editing Pipeline)
- 这是本文的技术核心,作者为不同编辑类型设计了定制化的解决方案
- 步骤四 & 五:数据质量增强 (Data Quality Enhancement)
- 预过滤: 在生成编辑图像前,通过启发式规则和美学评估,过滤掉有歧义的指令和低质量的原始图。
- 后过滤: 在生成编辑图像后,使用多种自动化评估指标(如 CLIP 相似度、L1 距离、目标检测器等)来筛掉不符合要求的图像,确保最终数据集中的图文对高度对齐、编辑效果好、且保留了未编辑区域的真实性。
 所有指标生上效果优于^0013a5
所有指标生上效果优于^0013a5
3.2 AnySD
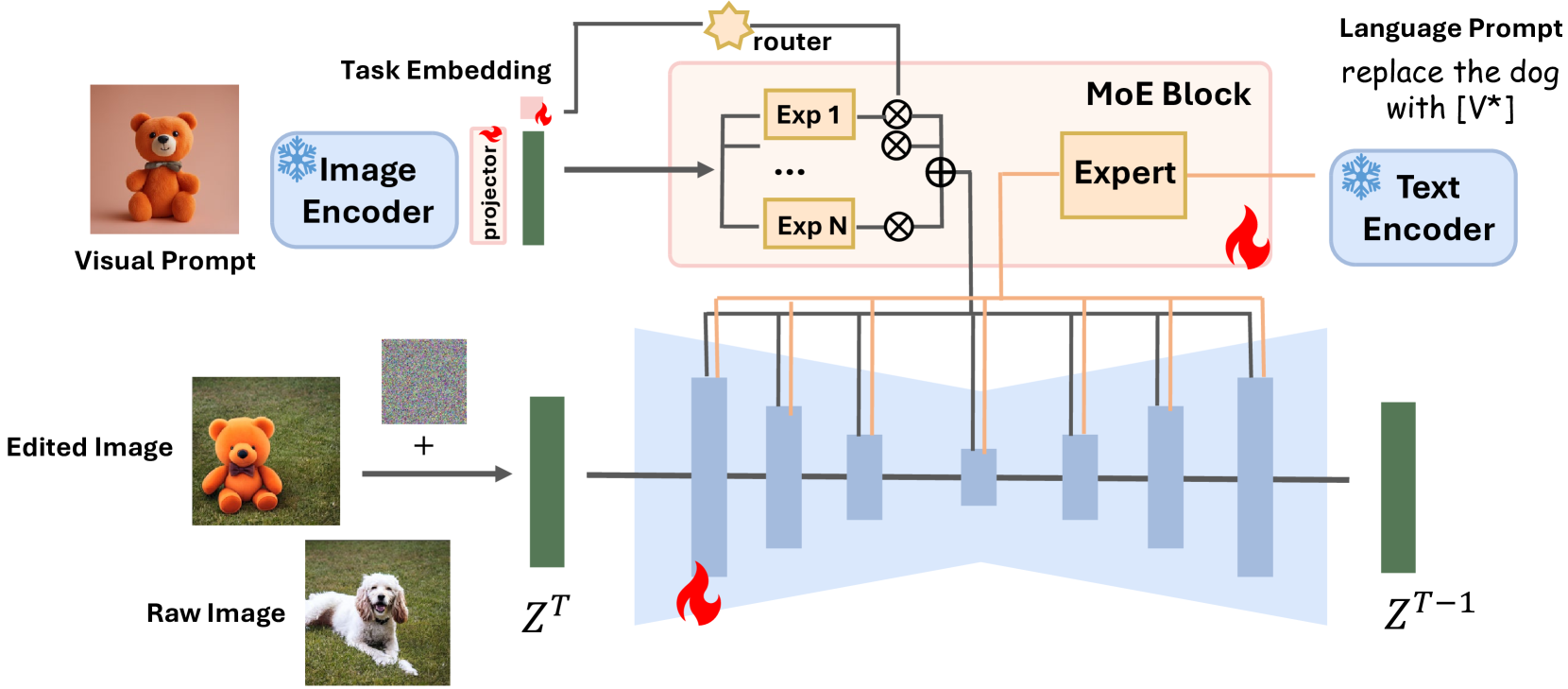
为了充分利用 AnyEdit 数据集的多样性,作者提出了 AnySD 模型,基于 SD1.5 的模型(U-Net版本)
- 视觉提示投影器 (Visual Prompt Projector): 当存在视觉输入时(如视觉编辑任务),该模块负责将视觉特征对齐到文本特征空间,使其能作为条件注入到U-Net中。使用冻结的CLIP Image Encoder
- 任务感知路由 (Task-aware Routing): 这是模型的“大脑”。它采用了 MoE 架构。。“路由”会根据当前任务的类型,智能地决定将计算任务分配给哪些专家,以及分配多少权重。这使得模型能为不同粒度的任务调用不同的处理模块。
- 可学习任务嵌入 (Learnable Task Embeddings): 我们在训练过程中学习了一个任务嵌入 ,主要承担两个功能:(1)与 (当未提供视觉提示时设为零)拼接形成 输入 MoE 模块;(2)作为路由网络的输入,在 MoE 专家间分配权重。
class IPAdapterAttnProAnySD(IPAdapterAttnProcessor2_0):
r"""
Attention processor for IP-Adapter for PyTorch 2.0.
Args:
hidden_size (`int`):
The hidden size of the attention layer.
cross_attention_dim (`int`):
The number of channels in the `encoder_hidden_states`.
num_tokens (`int`, `Tuple[int]` or `List[int]`, defaults to `(4,)`):
The context length of the image features.
scale (`float` or `List[float]`, defaults to 1.0):
the weight scale of image prompt.
"""
def __init__(self, hidden_size, cross_attention_dim=None, num_tokens=(4,), scale=1.0):
super().__init__(hidden_size, cross_attention_dim, num_tokens, scale)
self.to_k_ip = torch.nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
self.to_v_ip = torch.nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
def __call__(
self,
attn: Attention,
hidden_states: torch.Tensor,
encoder_hidden_states: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
temb: Optional[torch.Tensor] = None,
scale: float = 1.0,
ip_adapter_masks: Optional[torch.Tensor] = None,
):
residual = hidden_states
# separate ip_hidden_states from encoder_hidden_states
if encoder_hidden_states is not None:
if isinstance(encoder_hidden_states, tuple):
encoder_hidden_states, ip_hidden_states = encoder_hidden_states
else:
deprecation_message = (
"You have passed a tensor as `encoder_hidden_states`. This is deprecated and will be removed in a future release."
" Please make sure to update your script to pass `encoder_hidden_states` as a tuple to suppress this warning."
)
deprecate("encoder_hidden_states not a tuple", "1.0.0", deprecation_message, standard_warn=False)
end_pos = encoder_hidden_states.shape[1] - self.num_tokens[0]
encoder_hidden_states, ip_hidden_states = (
encoder_hidden_states[:, :end_pos, :],
[encoder_hidden_states[:, end_pos:, :]],
)
if attn.spatial_norm is not None:
hidden_states = attn.spatial_norm(hidden_states, temb)
input_ndim = hidden_states.ndim
if input_ndim == 4:
batch_size, channel, height, width = hidden_states.shape
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
batch_size, sequence_length, _ = (
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
)
if attention_mask is not None:
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
# scaled_dot_product_attention expects attention_mask shape to be
# (batch, heads, source_length, target_length)
attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
if attn.group_norm is not None:
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
query = attn.to_q(hidden_states)
if encoder_hidden_states is None:
encoder_hidden_states = hidden_states
elif attn.norm_cross:
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
key = attn.to_k(encoder_hidden_states)
value = attn.to_v(encoder_hidden_states)
inner_dim = key.shape[-1]
head_dim = inner_dim // attn.heads
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
# the output of sdp = (batch, num_heads, seq_len, head_dim)
hidden_states = F.scaled_dot_product_attention(
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
)
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
hidden_states = hidden_states.to(query.dtype)
if ip_adapter_masks is not None:
if not isinstance(ip_adapter_masks, List):
# for backward compatibility, we accept `ip_adapter_mask` as a tensor of shape [num_ip_adapter, 1, height, width]
ip_adapter_masks = list(ip_adapter_masks.unsqueeze(1))
if not (len(ip_adapter_masks) == len(self.scale) == len(ip_hidden_states)):
raise ValueError(
f"Length of ip_adapter_masks array ({len(ip_adapter_masks)}) must match "
f"length of self.scale array ({len(self.scale)}) and number of ip_hidden_states "
f"({len(ip_hidden_states)})"
)
else:
for index, (mask, scale, ip_state) in enumerate(zip(ip_adapter_masks, self.scale, ip_hidden_states)):
if not isinstance(mask, torch.Tensor) or mask.ndim != 4:
raise ValueError(
"Each element of the ip_adapter_masks array should be a tensor with shape "
"[1, num_images_for_ip_adapter, height, width]."
" Please use `IPAdapterMaskProcessor` to preprocess your mask"
)
if mask.shape[1] != ip_state.shape[1]:
raise ValueError(
f"Number of masks ({mask.shape[1]}) does not match "
f"number of ip images ({ip_state.shape[1]}) at index {index}"
)
if isinstance(scale, list) and not len(scale) == mask.shape[1]:
raise ValueError(
f"Number of masks ({mask.shape[1]}) does not match "
f"number of scales ({len(scale)}) at index {index}"
)
else:
ip_adapter_masks = [None] * len(self.scale)
# ----------- main change
current_ip_hidden_states = ip_hidden_states[0]
scale = self.scale[0]
mask = ip_adapter_masks[0]
# -----------
# for ip-adapter
skip = False
if isinstance(scale, list):
if all(s == 0 for s in scale):
skip = True
elif scale == 0:
skip = True
if not skip:
if mask is not None:
if not isinstance(scale, list):
scale = [scale] * mask.shape[1]
current_num_images = mask.shape[1]
for i in range(current_num_images):
ip_key = self.to_k_ip(current_ip_hidden_states[:, i, :, :])
ip_value = self.to_v_ip(current_ip_hidden_states[:, i, :, :])
ip_key = ip_key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
ip_value = ip_value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
# the output of sdp = (batch, num_heads, seq_len, head_dim)
_current_ip_hidden_states = F.scaled_dot_product_attention(
query, ip_key, ip_value, attn_mask=None, dropout_p=0.0, is_causal=False
)
_current_ip_hidden_states = _current_ip_hidden_states.transpose(1, 2).reshape(
batch_size, -1, attn.heads * head_dim
)
_current_ip_hidden_states = _current_ip_hidden_states.to(query.dtype)
mask_downsample = IPAdapterMaskProcessor.downsample(
mask[:, i, :, :],
batch_size,
_current_ip_hidden_states.shape[1],
_current_ip_hidden_states.shape[2],
)
mask_downsample = mask_downsample.to(dtype=query.dtype, device=query.device)
hidden_states = hidden_states + scale[i] * (_current_ip_hidden_states * mask_downsample)
else:
ip_key = self.to_k_ip(current_ip_hidden_states)
ip_value = self.to_v_ip(current_ip_hidden_states)
ip_key = ip_key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
ip_value = ip_value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
# the output of sdp = (batch, num_heads, seq_len, head_dim)
current_ip_hidden_states = F.scaled_dot_product_attention(
query, ip_key, ip_value, attn_mask=None, dropout_p=0.0, is_causal=False
)
current_ip_hidden_states = current_ip_hidden_states.transpose(1, 2).reshape(
batch_size, -1, attn.heads * head_dim
)
current_ip_hidden_states = current_ip_hidden_states.to(query.dtype)
hidden_states = hidden_states + scale * current_ip_hidden_states
# linear proj
hidden_states = attn.to_out[0](hidden_states)
# dropout
hidden_states = attn.to_out[1](hidden_states)
if input_ndim == 4:
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
if attn.residual_connection:
hidden_states = hidden_states + residual
hidden_states = hidden_states / attn.rescale_output_factor
return hidden_states
Unet部分是参考 IP-adapter 的实现,主要增加了遮罩,多参考图,创建了专用的 to_k_ip 和 to_v_ip 线性层来处理图像特征。
- 接收输入:接收 UNet 特征、拼接的(文本+图像)特征。
- 特征分离:将拼接的特征拆分为独立的文本特征和图像特征。
- 计算文本注意力:执行一次标准的交叉注意力,让 UNet 特征与文本提示对齐。
- 计算图像注意力:使用专用的 K/V 投影层,执行第二次交叉注意力,让 UNet 特征与图像提示对齐。
- 融合结果:
- 如果有遮罩,则将加权的、被遮罩的图像注意力结果,加到文本注意力结果上。
- 如果没有遮罩,则将加权的、全局的图像注意力结果,加到文本注意力结果上。
- 返回最终特征:将融合后的特征传递给 UNet 的下一层。
3.3 AnyEdit-Test
从 AnyEdit 的每类编辑数据中人工筛选 50 组高质量样本,构建更具挑战性的 AnyEdit-Test 评估集。
4. 实验/评估/结果
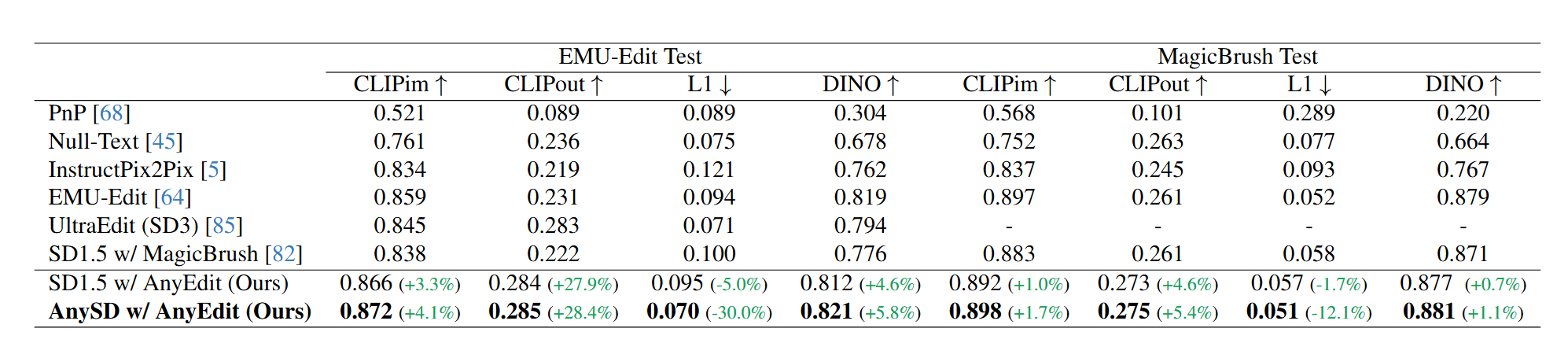
4.1 实验设置
- 基础模型: 采用 Stable-Diffusion 1.5 作为骨干网络,保证了与其他工作的公平比较。
- 数据集: 训练时只使用本文构建的 AnyEdit 数据集。
- 基准 (Benchmarks): 在两个公开标准基准 EMU-Edit Test 和MagicBrush 上进行评测,同时也在本文提出的、更具挑战性的AnyEdit-Test 上进行评估。
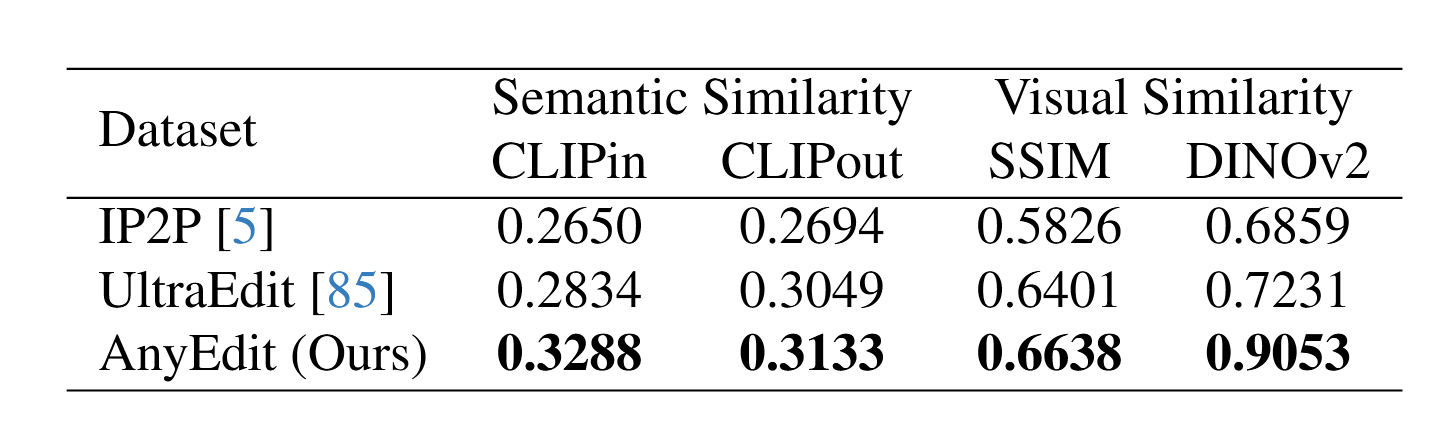
- 指标 (Metrics): 使用 CLIPim/CLIPout (衡量语义相似度,即编辑是否准确) 和 DINO/L1 (衡量视觉相似度,即非编辑区域是否保持不变)。
4.2 实验结果
实验表明,即使是标准的SD1.5模型,只要用 AnyEdit 数据集进行训练,其性能就能超越之前所有SOTA模型。而完整的 AnySD 模型则进一步刷新了记录。
4.3 消融实验
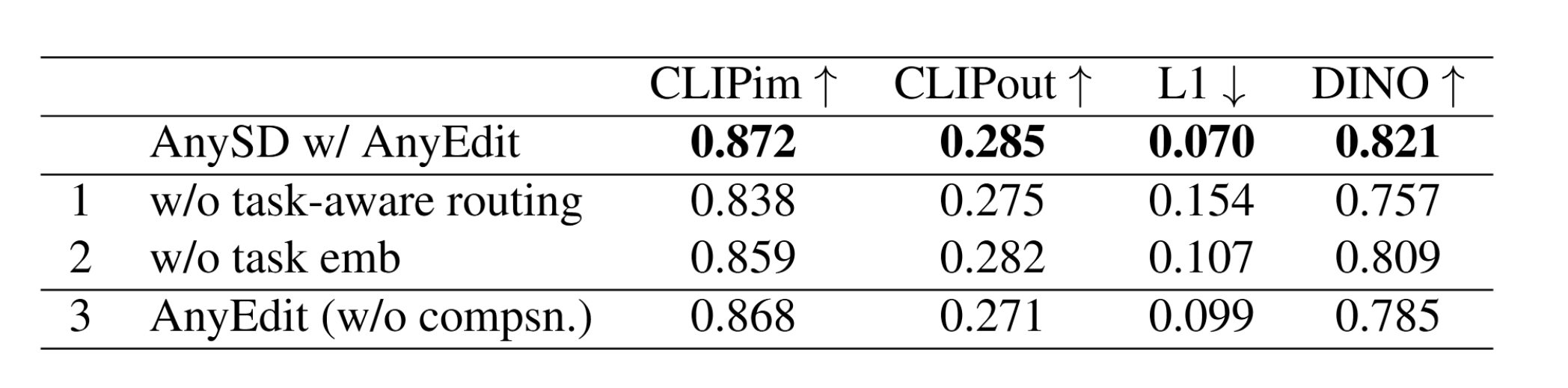
消融实验 (Ablation Study, Table 6):
- 移除“任务感知路由”(MoE),模型性能大幅下降,证明了为不同任务匹配不同专家的重要性。
- 移除“任务嵌入”,模型在视觉一致性上变差,说明任务嵌入对于控制编辑粒度至关重要。
- 移除用于平衡数据分布的“反事实合成数据”,模型泛化能力下降,证明了该数据对提升模型语义理解的有效性。
5. 论文结论
作者系统性地定义了图像编辑任务,并提出了一套创新的、可扩展的自动化数据构建框架。基于此框架,构建了目前规模最大、类型最全的指令编辑数据集 AnyEdit 及其测试基准 AnyEdit-Test。此外,还设计了强大的 AnySD 模型,它通过任务感知的 MoE 架构,成功解锁了 AnyEdit 数据的潜力。
6. 个人总结
亮点
自适应编辑管线:为每个具体的子任务选择最合适的工具与 2.1 数据流水线是同一思路 反事实合成场景 :仅解决了当前模型因数据偏见导致的“刻板印象”问题,为如何系统性地提升模型泛化能力和创造力提供了一个可行的范例。 Moe架构:提升了对不同子任务的处理能力,总体优化了整体性能