Lumina-DiMOO: An Omni Diffusion Large Language Model for Multi-Modal Generation and Understanding

Figure 1: Lumina-DiMOO 能力展示。
1 Intro
1.1 Motivation
当前多模态大模型在统一生成与理解任务上存在架构上的根本分歧:主流方法要么采用 AR (autoregressive) 文本 + continuous diffusion 图像的混合架构(如 BAGEL 的 MoT 设计),要么在速度与质量之间做取舍。AR 模式虽然在文本理解上成熟,但图像生成的逐 token 解码严重制约推理效率。与此同时,continuous diffusion 模型难以直接处理离散文本 token,导致多模态统一建模需要引入异构模块。
discrete diffusion 近年来在语言建模(如 LLaDA)和图像生成(如 aMUSEd)中分别展现出潜力,但尚未有人将其统一到同一框架中同时处理文本和图像的生成与理解。本文正是要回答一个核心问题:能否用纯 discrete diffusion 一种范式,不需要任何 AR 组件,同时实现高质量的图像生成和多模态理解?
1.2 核心主张
Lumina-DiMOO 的核心主张是:fully discrete diffusion modeling 可以作为文本和图像的统一生成范式,在单一 Transformer 架构上同时支持 T2I generation、image editing、image understanding 等多种任务,且推理速度相比 AR 基线提升 32 倍。
具体而言,模型将文本和图像都离散化为 token,统一在一个 discrete diffusion 框架中通过 parallel masked token prediction 进行训练和推理——不需要 AR 解码,不需要 continuous flow matching,不需要异构的 MoT 架构。
1.3 贡献
- 统一的 fully discrete diffusion 框架:首个在单一 Transformer 上用纯 discrete diffusion 同时处理文本和图像的生成与理解的模型
- 基于 LLaDA-Base 的零结构修改扩展:在预训练 discrete diffusion LLM 上直接扩展视觉词表,无需改动模型架构
- ML-Cache (Max Logit-based Cache):training-free 的推理加速方法,额外提供 2 倍加速
- Self-GRPO:一种 novel self-improving RL 框架,通过 trajectory-consistent training 联合优化 T2I 和 multimodal understanding
- Zero-shot inpainting 和 Interactive Retouching:由 discrete diffusion paradigm 天然支持的交互式图像编辑能力
- SOTA 性能:在 GenEval、DPG、UniGenBench 等基准上取得最优或接近最优结果
2 Method
2.1 架构
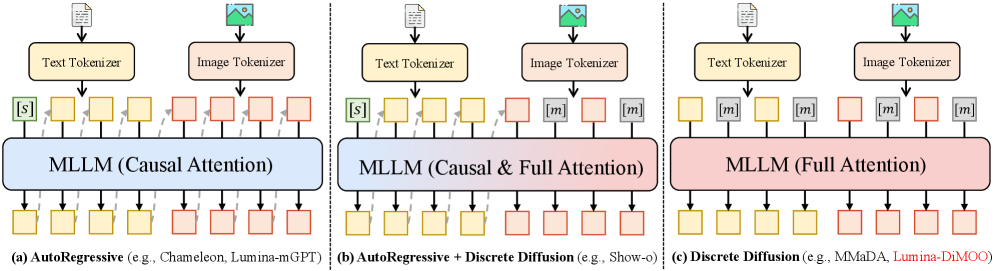
Figure 2: 统一模型架构演进对比。从纯 AR → AR+Diffusion Head → AR+离散扩散 → 纯离散扩散(Lumina-DiMOO)。
2.1.1 Foundation Model
Lumina-DiMOO 基于预训练的 LLaDA-Base 模型构建。LLaDA 是一个 discrete diffusion language model,其训练目标是在 masked token prediction 框架下学习语言建模。Lumina-DiMOO 直接复用 LLaDA-Base 的 Transformer 结构,不进行任何架构修改,仅扩展词表以容纳视觉 token。
这一设计选择的关键优势是:可以直接继承 LLaDA 在文本理解和生成上的能力,避免从头训练的巨大开销。
2.1.2 Visual Tokenizer
图像 tokenization 采用 aMUSEd-VQ tokenizer,实现 16×16 的空间下采样。每张图像被编码为离散的 visual token 序列,codebook 大小为 8,192(即 8,192 个 visual tokens)。
词表扩展策略:
- 保留 LLaDA 原有的 text tokens
- 新增 8,192 个 visual tokens
- 新增特殊 token:
<IMAGE>(标记图像区域起始)、<end-of-line>(标记每行图像 token 结束)
2.1.3 Arbitrary Resolution 处理
为支持任意分辨率的图像,模型在每行 visual token 末尾插入 <end-of-line> token。这使得 1D 序列中隐式保留了 2D 图像的空间结构信息,从而无需固定图像分辨率即可处理不同尺寸的输入。
2.1.4 Unified Discrete Diffusion
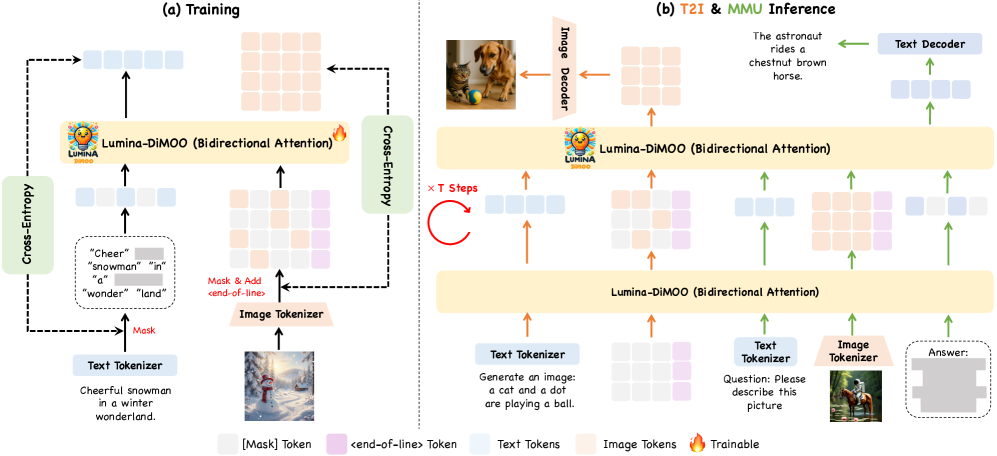
Figure 3: Lumina-DiMOO 的离散扩散建模概览。(a) 训练:对 text 和 image token 加 mask 后预测。(b) 推理:从全 mask 状态逐步预测 masked tokens。
核心训练目标是 masked cross-entropy loss:
其中 是被 mask 的 token 集合, 是未被 mask 的 token 集合, 是条件信息。在推理时,模型从全 mask 状态出发,通过 iterative parallel decoding 逐步预测所有 masked tokens,直至生成完整序列。
这一机制的核心特点是:text 和 image tokens 共享完全相同的 diffusion 过程,无需区分对待。
2.1.5 ML-Cache (Max Logit-based Cache)
ML-Cache 是一种 training-free 的推理加速方法。其核心思想是:在 iterative decoding 的相邻步骤之间,部分 token 的预测已经高度确定(即 max logit 显著领先),这些 token 可以跳过后续 diffusion step 的重新计算。
ML-Cache 为模型提供了额外的约 2 倍推理加速,且不需要任何额外训练。
2.1.6 独特能力:Zero-shot Inpainting 与 Interactive Retouching
由于 discrete diffusion 天然支持 partial masking,Lumina-DiMOO 可以:
- Zero-shot inpainting:对图像的特定区域进行 mask 后重新生成,无需专门训练
- Interactive Retouching:用户可以交互式地选择图像区域进行精细修改,同时保持周围内容不变
这是 AR 模型难以直接实现的能力,也是 discrete diffusion paradigm 的一个结构性优势。
2.2 Training Mechanism
训练采用 masked token prediction 机制。对于每个训练样本,随机 mask 一定比例的 token(包括文本和图像),然后训练模型预测被 mask 的 token。这与 LLaDA 的训练方式一致,但扩展到了多模态场景。
推理时采用 iterative decoding:从全 mask 序列出发,每步并行预测所有 masked tokens 的分布,根据置信度逐步 unmask,直到所有 token 被解码。
2.3 Data
训练数据涵盖多模态场景,分为四个阶段逐步引入更复杂的数据类型(详见 2.4 Training Strategy)。
关键数据来源包括:
- 文本-图像对(text-image pairs):约 80M
- 图像编辑、风格迁移、可控生成等 i2i 任务数据:约 3M
- 复杂视觉数据(表格、图表、UI 截图等)
- 高质量 instruction-following 数据:生成和理解各约 15M 样本
2.4 Training Strategy
训练分为四个阶段,逐步提升模型能力:
Stage-I (Pre-Training):多模态对齐阶段。使用约 80M 文本-图像对,以渐进式分辨率(progressive resolution)从 256 像素逐步提升到 512 像素。此阶段的目标是让模型学会文本和视觉 token 之间的基本对齐关系。
Stage-II (Mid-Training):集成多样化 i2i 任务(图像编辑、风格迁移、可控生成)以及复杂视觉数据(表格、图表、UI 截图等),使用约 3M 图像。此阶段扩展模型的视觉理解和操作能力。
Stage-III (SFT):Supervised Fine-Tuning 阶段。使用高质量 instruction-following 数据,生成和理解任务各约 15M 样本。此阶段提升模型的指令遵循能力。
Stage-IV (Self-GRPO):Novel self-improving RL 框架。
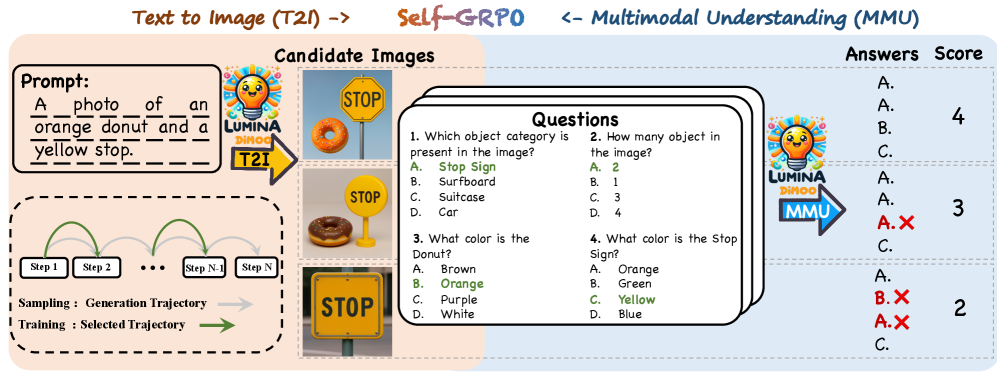
Figure 5: Self-GRPO 框架概览。统一 T2I 生成和多模态理解的 trajectory-consistent 强化学习。
通过 trajectory-consistent training 联合优化 T2I 生成和 multimodal understanding。Self-GRPO 使模型能够利用自身的生成结果作为 reward signal 进行自我改进,将 GenEval 从 0.88 提升至 0.91。
3 实验结果
3.1 T2I Generation
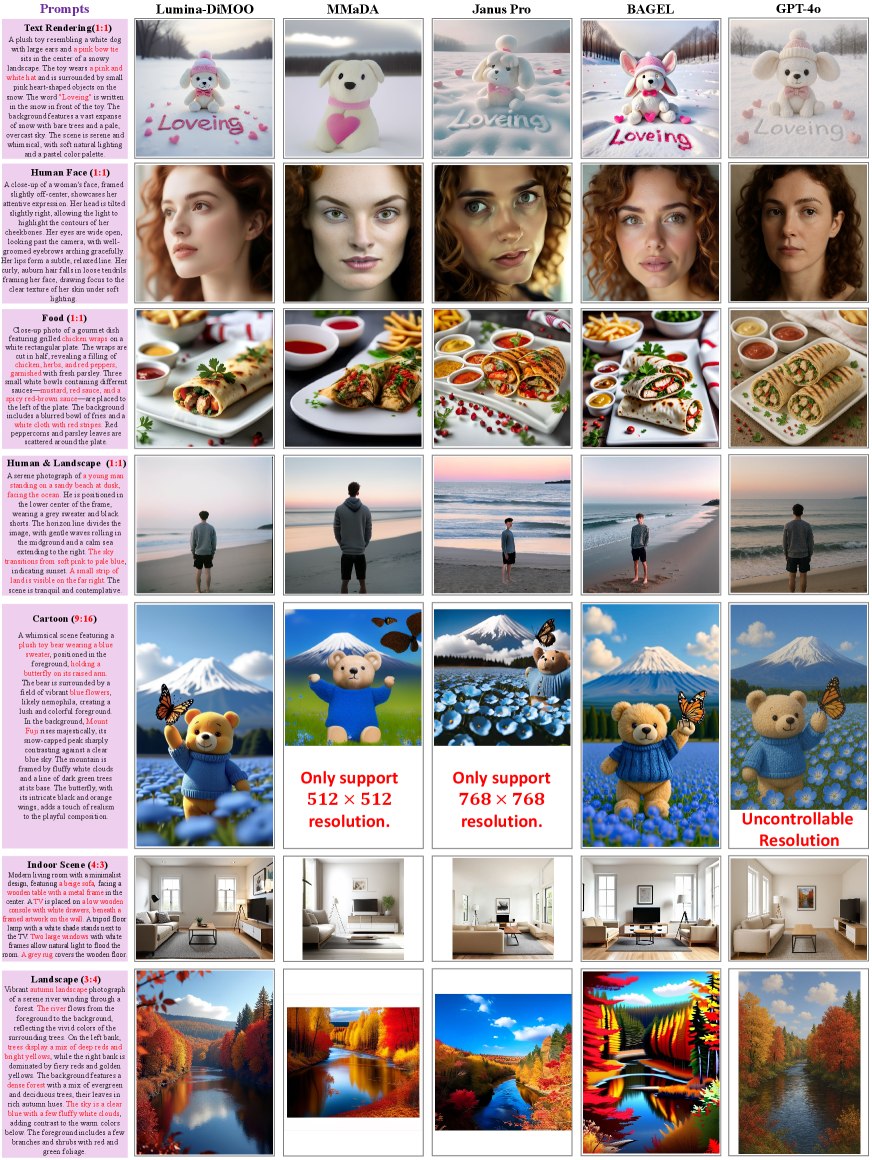
Figure 6: T2I 生成质量定性对比。Lumina-DiMOO vs MMaDA、Janus Pro、BAGEL、GPT-4o。
表:GenEval Benchmark 原始结果
Method Architecture Params Single Obj. Two Obj. Counting Colors Position Attr. Overall ↑ Gen. Only LlamaGen AR 0.8B 0.71 0.34 0.21 0.58 0.07 0.04 0.32 PixArt-α Diffusion 0.6B 0.98 0.50 0.44 0.80 0.08 0.07 0.48 SDv2.1 Diffusion 0.9B 0.98 0.51 0.44 0.85 0.07 0.17 0.50 Emu3-Gen AR 8B 0.98 0.71 0.34 0.81 0.17 0.21 0.54 SDXL Diffusion 2.6B 0.98 0.74 0.39 0.85 0.15 0.23 0.55 DALL-E 3 - - 0.96 0.87 0.47 0.83 0.43 0.45 0.67 SD3-Medium Diffusion 2B 0.99 0.94 0.72 0.89 0.33 0.60 0.74 FLUX.1-dev Diffusion 12B 0.98 0.81 0.74 0.79 0.22 0.45 0.66 OmniGen Diffusion 3.8B 0.98 0.84 0.66 0.74 0.40 0.43 0.68 SANA-1.5 Diffusion 4.8B 0.99 0.85 0.77 0.87 0.34 0.54 0.72 Lumina-mGPT 2.0 AR 7B 0.99 0.87 0.44 0.85 0.44 0.54 0.69 Und. and Gen. SEED-X AR 17B 0.97 0.58 0.26 0.80 0.19 0.14 0.49 Show-o AR+Discrete Diff. 1.3B 0.95 0.52 0.49 0.82 0.11 0.28 0.53 Janus AR 1.3B 0.97 0.68 0.30 0.84 0.46 0.42 0.61 D-DiT Discrete Diff.+Diff. 2B 0.97 0.80 0.54 0.76 0.32 0.50 0.65 Transfusion AR+Diff. 7B - - - - - - 0.63 TokenFlow-XL AR 14B 0.95 0.60 0.41 0.81 0.16 0.24 0.55 Chameleon AR 7B - - - - - - 0.39 Janus-Pro AR 7B 0.99 0.89 0.59 0.90 0.79 0.66 0.80 GPT-4o - - 0.99 0.92 0.85 0.92 0.75 0.61 0.84 BLIP3-o AR+Diff. 8B - - - - - - 0.80 BAGEL AR+Diff. 14B 0.99 0.94 0.81 0.88 0.64 0.63 0.82 UniWorld-V1 AR+Diff. 20B 0.99 0.93 0.79 0.89 0.49 0.70 0.80 OmniGen2 AR+Diff. 7B 1.0 0.95 0.64 0.88 0.55 0.76 0.80 MMaDA Discrete Diff. 8B 0.99 0.76 0.61 0.84 0.20 0.37 0.63 Lumina-DiMOO Discrete Diff. 8B 1.0 0.94 0.85 0.89 0.85 0.76 0.88 Lumina-DiMOO + Self-GRPO Discrete Diff. 8B 1.0 0.96 (+2%) 0.87 (+2%) 0.95 (+6%) 0.85 0.82 (+6%) 0.91 (+3%) Lumina-DiMOO 基础模型 0.88,Self-GRPO 后 0.91,超越 GPT-4o (0.84)、BAGEL (0.82)。Position 和 Attribute 子项优势最显著(0.85 vs BAGEL 0.64/0.63)。
表:DPG-Bench 原始结果
Method Architecture Params Global Entity Attribute Relation Other Overall ↑ PixArt-α Diffusion 0.6B 74.97 79.32 78.60 82.57 76.96 71.11 SDXL Diffusion 2.6B 83.27 82.43 80.91 86.76 80.41 74.65 DALL-E 3 - - 90.97 89.61 88.39 90.58 89.83 83.50 SD3-Medium Diffusion 2B 87.90 91.01 88.83 80.70 88.68 84.08 FLUX.1-dev Diffusion 12B 74.35 90.00 88.96 90.87 88.33 83.84 Janus-Pro AR 7B 86.90 88.90 89.40 89.32 89.48 84.19 GPT-4o - - 88.89 88.94 89.84 92.63 90.96 85.15 BAGEL AR+Diff. 14B 88.94 90.37 91.29 90.82 88.67 85.07 OmniGen2 AR+Diff. 7B 88.81 88.83 90.18 89.37 90.27 83.57 MMaDA Discrete Diff. 8B 77.81 78.48 81.74 84.79 63.20 69.97 Lumina-DiMOO Discrete Diff. 8B 81.46 92.08 88.98 94.31 82.00 86.04
表:OneIG-EN 原始结果
Model Style World Know. Attr. Action Relation Logic. Grammar Compound Layout Text Overall DALL-E 3 95.06 93.51 75.97 69.83 78.06 48.18 68.07 70.60 66.67 25.86 69.18 SD-3.5-Large 88.60 88.92 68.59 62.17 69.80 32.27 58.96 58.76 69.03 32.76 62.99 FLUX.1-dev 83.90 88.92 67.84 62.17 67.26 30.91 60.96 47.04 71.83 32.18 61.30 Janus-Pro 90.80 86.71 67.74 64.26 68.40 37.05 64.44 62.11 72.01 2.59 61.61 BAGEL 90.20 85.60 67.74 61.98 70.69 30.23 66.44 58.12 76.49 7.76 61.53 OmniGen2 91.90 86.39 72.12 62.83 68.27 32.50 59.89 56.31 71.64 29.02 63.09 MMaDA 82.40 56.65 48.39 37.83 50.25 17.95 55.75 32.35 30.22 1.15 41.35 Lumina-DiMOO 89.70 90.03 81.62 71.12 78.43 45.45 70.45 73.32 82.84 25.57 71.12
Lumina-DiMOO 在 GenEval 上取得 0.88 的基础分数,经 Self-GRPO 提升至 0.91,超越 GPT-4o (0.84) 和 BAGEL (0.82)。在 DPG (86.04)、OneIG-EN (71.12) 上均取得最优结果。
3.2 Image Understanding
表:Image Understanding 原始结果
Model Architecture Params POPE ↑ MME-P ↑ MMB ↑ SEED ↑ MMMU ↑ Und. Only LLaVA-v1.5 AR 7B 85.9 1510.7 64.3 58.6 35.4 InstructBLIP AR 7B - - 36.0 53.4 - Qwen-VL-Chat AR 7B - 1487.5 60.6 58.2 - Emu3-Chat AR 8B 85.2 1244 58.5 68.2 31.6 Und. and Gen. Show-o AR+Discrete Diff. 1.3B 80.0 1097.2 - - 26.7 D-Dit Discrete Diff.+Diff. 2B 84.0 1124.7 - - - TokenFlow-XL AR 13B 86.8 1545.9 68.9 68.7 38.7 VILA-U AR 7B 85.8 1401.8 - 59.0 - Janus-Pro AR 7B 87.4 1567.1 79.2 72.1 41.0 BLIP3-o AR+Diff. 8B - 1682.6 83.5 77.5 50.6 BAGEL AR+Diff. 14B - 1687.0 85.0 - 55.3 UniWorld-V1 AR+Diff. 20B - - 83.5 - 58.6 OmniGen2 AR+Diff. 7B - - 79.1 - 53.1 MMaDA Discrete Diff. 8B 86.1 1410.7 68.5 64.2 30.2 Lumina-DiMOO Discrete Diff. 8B 87.4 1534.2 84.5 83.1 58.6 Lumina-DiMOO 在 POPE (87.4) 上与 Janus-Pro 持平,在 SEED (83.1) 上大幅超越所有模型(第二名 BLIP3-o 77.5),在 MMMU (58.6) 上与 UniWorld-V1 持平并超越 BAGEL (55.3)。
在多模态理解任务上,Lumina-DiMOO 在 POPE (87.4) 上与 Janus-Pro 持平,在 SEED (83.1) 上大幅超越 MMaDA (64.2),在 MMMU (58.6) 上超越 BAGEL (55.3)。这表明 fully discrete diffusion 框架在理解任务上同样具有竞争力。
3.3 Ablation Study

Figure 9: 图像编辑定性对比。Lumina-DiMOO vs BAGEL vs GPT-4o,在物体添加/移除/替换、背景和风格修改上对比。

Figure 13: Interactive Retouching 展示。用户可以反复修改特定区域,同时保持周围内容不变——这是 discrete diffusion paradigm 的结构性优势。
表:关键消融实验结果
设置 GenEval 推理加速 Baseline (无 ML-Cache) 0.88 1× + ML-Cache 0.88 ~2× + Self-GRPO 0.91 — 从头训练 (w/o LLaDA init) 失败 —
关键发现:
- ML-Cache 提供一致的约 2 倍推理加速,且不影响生成质量
- LLaDA 初始化至关重要:从头训练 discrete diffusion 多模态模型会失败,说明继承预训练 discrete diffusion LLM 的能力是成功的前提
- Self-GRPO 将 GenEval 从 0.88 提升至 0.91,验证了 self-improving RL 的有效性
3.4 与 BAGEL 的对比分析
表:Lumina-DiMOO vs BAGEL 架构对比
维度 Lumina-DiMOO BAGEL 架构 Single Transformer MoT (Mixture of Transformers) 文本生成范式 Discrete diffusion AR 图像生成范式 Discrete diffusion Continuous flow matching 推理速度 32× AR baselines — GenEval 0.88–0.91 0.82 Token 类型 离散 (VQ) 连续 (图像) + 离散 (文本) 量化损失 存在 无 (图像部分)
BAGEL 采用 MoT 架构,文本用 AR、图像用 continuous flow matching,是异构混合方案。Lumina-DiMOO 则是纯 discrete diffusion,单一架构处理所有模态。Lumina-DiMOO 的主要优势是速度(32 倍于 AR 基线)和架构简洁性;劣势是 discrete tokenization 带来的量化损失。
4 结论
Lumina-DiMOO 首次证明了 fully discrete diffusion 可以作为多模态生成和理解的统一范式。通过在 LLaDA-Base 上零架构修改地扩展视觉词表,配合四阶段训练策略(包括 novel Self-GRPO),模型在 T2I generation(GenEval 0.91)、multimodal understanding(POPE 87.4)等任务上取得了有竞争力的结果,同时推理速度相比 AR 基线提升 32 倍。
ML-Cache 和 Interactive Retouching 进一步展示了 discrete diffusion paradigm 的实用价值——前者提供 training-free 加速,后者实现了 AR 模型难以做到的交互式图像编辑。
5 思考
5.1 优点
- 范式简洁性:fully discrete diffusion 用一种机制统一处理文本和图像,避免了 BAGEL 等方法中 AR + diffusion 的异构复杂度,架构设计极其干净
- 推理效率:parallel decoding 天然比 AR 的逐 token 解码快得多,32 倍加速在实际部署中意义重大
- 零架构修改:直接复用 LLaDA-Base 而不改动 Transformer 结构,说明 discrete diffusion LLM 的扩展性非常好,降低了工程复杂度
- Self-GRPO 的 self-improving 思路:利用模型自身的生成轨迹作为 RL signal,是一种可扩展的后训练方法
- 天然支持 inpainting/retouching:discrete diffusion 的 partial masking 机制使得交互式编辑成为模型的内建能力,而非额外加装的功能模块
- 全面的任务覆盖:T2I、i2i editing、style transfer、understanding 在同一模型中统一处理
5.2 缺点
- 量化损失(quantization loss):使用 VQ tokenizer 将图像离散化为 8,192 个 visual tokens,不可避免地损失细粒度视觉信息。continuous diffusion 模型在这一点上更有优势
- 严重依赖 LLaDA 初始化:消融实验表明从头训练会失败,说明该框架的可移植性有限——如果没有合适的预训练 discrete diffusion LLM,整个方法可能无法工作
- VQ codebook 仅 8,192:相比一些高分辨率需求的场景,codebook 大小可能成为瓶颈,尤其是复杂细节的图像生成
- Self-GRPO 的泛化性存疑:从 0.88 提升到 0.91 的 GenEval 提升有限,且不清楚该 RL 框架在其他基准上是否一致有效
- Interactive Retouching 的评估缺乏定量指标:论文将此作为独特卖点,但缺乏系统性的用户研究或定量评估
- 与 continuous diffusion 的差距:在需要极高保真度的场景中,discrete tokenization 的信息损失可能使得输出质量不及 continuous 方法
5.3 Wiki Connections
- Discrete Diffusion Language Models — LLaDA 等 discrete diffusion 在 NLP 中的发展脉络
- VQ-VAE — Visual tokenization 的基础方法,aMUSEd-VQ 的理论背景
- BAGEL — 本文的主要对比基线,MoT + AR + continuous flow matching 的方案
- Masked Language Modeling — BERT 的 MLM 可视为 discrete diffusion 的特例
- Flow Matching — 连续扩散模型的训练范式,与本文的 discrete approach 形成对比
- GRPO (Group Relative Policy Optimization) — Self-GRPO 的基础 RL 框架
- Multi-Modal Foundation Models — 统一生成与理解的大模型研究方向
- LLaDA — Lumina-DiMOO 的基础 discrete diffusion LLM
- Inference Acceleration for Generative Models — ML-Cache 所属的研究方向
5.4 与同期统一多模态模型的对比
| 维度 | Lumina-DiMOO | BAGEL | Tuna-2 | OmniGen2 | UniWorld-V1 |
|---|---|---|---|---|---|
| 架构 | 单 Transformer(离散扩散) | MoT(双专家共享注意力) | 单 Transformer,无编码器 | VLM+DiT(解耦) | VLM+SigLIP+FLUX |
| 文本范式 | 离散扩散(masked prediction) | 自回归(AR) | 自回归(AR) | 自回归(AR) | 自回归(AR) |
| 图像范式 | 离散扩散(masked prediction) | Rectified Flow | Flow Matching(像素空间) | Flow Matching | Flow Matching |
| 统一程度 | 最高(同一机制处理所有模态) | 高(共享注意力) | 高(单一 Transformer) | 中(两个独立模型) | 低(三个独立模型) |
| 推理速度 | 32x AR 基线 | 中等 | 中等 | 中等 | 中等 |
| GenEval | 0.88 (0.91 w/ GRPO) | 0.88 | competitive | 0.95 | — |
关键洞察:
- 范式纯度 vs 性能:Lumina-DiMOO 是唯一用纯离散扩散统一所有模态的模型,架构最干净,但 VQ 量化带来信息损失。BAGEL 用连续表示避免了量化损失,但引入了 AR+FM 的异构复杂度。
- 速度优势的来源:Lumina-DiMOO 的 32x 加速来自 parallel decoding(一次预测所有 masked tokens),而非 AR 的逐 token 解码。ML-Cache 再翻倍。
- Self-GRPO 的通用性:Lumina-DiMOO 的 Self-GRPO 和 OmniGen2 的 GRPO 都用 RL 提升生成质量,但 Lumina-DiMOO 是 self-improving(不需要外部 reward model),更可扩展。