一句话总结:本文提出了 BAGEL,一个基于 MoT(Mixture-of-Transformers)架构的开源统一多模态基础模型(7B 激活/14B 总参数),通过在万亿 token 级的多模态交错数据上大规模预训练,涌现出了复杂多模态推理、自由形式图像编辑、3D 操控和世界导航等超出传统 benchmark 范围的 emergent 能力。

Figure 1: BAGEL 的多样化能力展示——从 T2I 生成、图像编辑到 3D 操控和世界导航。
1 Intro
1.1 Motivation
当前统一多模态理解与生成的学术模型与闭源系统(GPT-4o、Gemini 2.0)之间存在巨大差距。作者认为,差距的核心原因在于:现有学术模型主要在图文对(image-text pair)数据上训练,缺乏大规模多模态交错数据(interleaved data)——即将文本、图像、视频和网页内容以自然交织的方式组织在一起的训练数据。
现有统一模型的三种架构路线各有缺陷:
- 量化自回归(Quantized AR):将视觉 token 离散化后用自回归生成,实现简单但生成质量不如扩散模型,且推理延迟高(逐 token 串行解码)。
- 外挂扩散器(External Diffuser):LLM 生成语义条件 token → 外挂扩散模型生成图像。收敛快但引入了信息瓶颈——LLM 的上下文被压缩成少量潜变量 token,在长上下文多模态推理中信息损失严重,违背”规模化基础模型”的哲学。
- 集成 Transformer(Integrated Transformer):将 LLM 和扩散模型统一在一个 Transformer 中,无信息瓶颈,但训练成本高。
1.2 核心主张
关键在于用精心构建的多模态交错数据规模化训练。随着交错预训练规模的增加,模型涌现出复杂组合能力——从基本的理解和生成,到自由形式视觉编辑,再到长上下文多模态推理。这些能力无法被传统 benchmark 捕获。
1.3 贡献
- BAGEL 模型:开源 7B 激活参数的 MoT 统一多模态模型,在理解 benchmark 上超越现有开源 VLM,在 T2I 生成上与 FLUX.1-dev / SD3 持平或超越
- MoT 架构验证:通过受控实验证明 MoT > MoE > Dense,理解与生成需要分离的参数空间
- 多模态交错数据协议:建立从视频和网页中可扩展构建高质量交错数据的完整流程
- 涌现现象的实证记录:首次在统一多模态预训练中观察到清晰的能力涌现阶段——理解先收敛→生成次之→编辑缓慢提升→复杂推理最后涌现
- IntelligentBench:专门评估需要复杂多模态推理的自由形式图像编辑的新 benchmark
2 Method
2.1 架构设计:MoT(Mixture-of-Transformers)
BAGEL 是一个 decoder-only 的统一多模态模型,7B 激活参数,14B 总参数。核心思想:用一个 Transformer 同时处理理解和生成两种任务,但不是用同一套参数——而是复制了两套完整 Transformer(MoT),通过共享自注意力层实现信息流通。
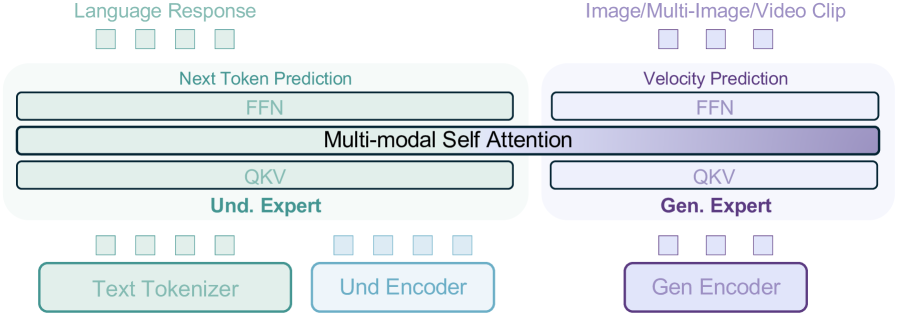
Figure 2: BAGEL 的 MoT 架构。两个 Transformer 专家分别处理理解和生成信息,所有 token 在每层共享自注意力。两个独立的视觉编码器分别捕获语义内容(SigLIP2)和低级像素信息(FLUX VAE)。
2.1.1 双视觉编码器
BAGEL 用两套独立的视觉编码器,分别服务理解和生成:
理解编码器:SigLIP2-so400m/14
- ViT 模型,400M 参数,原始固定输入 384×384
- 位置 embedding 插值后支持最大 980×980
- 配合 NaViT(Native Resolution ViT),图片以原始宽高比输入,不做强制 resize。NaViT 采用 Patch n’ Pack 技术:把不同分辨率图片的 patch 序列打包到同一个 batch 里,类似 NLP 里把不同长度句子 pack 到一起
- 输出 ViT token,编码图像的语义信息(“这是什么”)
- 通过两层 MLP connector 对齐到 LLM 的隐藏维度
生成编码器/解码器:FLUX VAE( FLUX.1-schnell)
- 预训练 VAE,来自 FLUX 模型,训练期间冻结不动
- 8 倍下采样,16 个 latent channel
- 输出 VAE token,编码图像的像素级信息(“怎么画”)
- 再过 2×2 patch embedding 层压缩空间尺寸,对齐到 LLM 隐藏维度
为什么需要两个编码器:理解需要高层语义(SigLIP2 擅长),生成需要低层像素细节(VAE 擅长),一个编码器很难两全。
2.1.2 LLM 骨干:Qwen2.5
基础网络直接复用 Qwen2.5 LLM 的 decoder-only Transformer,内部组件:
- RMSNorm:比 LayerNorm 省掉”减均值”步骤,只用均方根归一化 + 可学习 scale,计算更轻
- SwiGLU:FFN 的激活函数,门控机制(
SwiGLU(x) = (xW₁ ⊙ Swish(xW₃)) W₂),比 ReLU/GELU 表达能力更强 - RoPE:旋转位置编码,把位置信息编码成旋转矩阵作用在 Q/K 上,注意力分数只取决于相对位置差,天然支持长度外推
- GQA:Grouped Query Attention,多个 Q head 共享同一组 K/V head,KV cache 从 32 份降到 8 份,推理显存大幅减少
- QK-Norm:每个注意力层对 Q 和 K 做 L2 归一化,防止扩散训练中 attention logits 爆炸导致 NaN。这在 DiT/FLUX/SD3 等生成模型里是标配,传统 LLM 通常不需要
2.1.3 MoT 核心设计
把 Qwen2.5 参数完整复制一份,得到两个专家:
| 理解专家 | 生成专家 | |
|---|---|---|
| 处理的 token | Text + ViT | VAE |
| 参数来源 | 原始 Qwen2.5 | 复制的 Qwen2.5 |
| 参数量 | ~7B | ~7B |
硬路由:VAE token 只过生成专家的 FFN 和 LayerNorm;Text/ViT token 只过理解专家的 FFN 和 LayerNorm。
共享自注意力(MoT 与普通 MoE 最大区别):
- 每一层,所有 token(不论哪个专家)都参与同一组 Q/K/V 计算
- Text token 可以 attend 到 VAE token,ViT token 也可以 attend 到 VAE token
- 信息通过注意力机制在理解和生成之间流通
- 但 FFN 和归一化是各自独立的
直觉理解:自注意力 = 全局信息交流(大家共享),FFN = 局部知识提取(各干各的)。这样理解和生成可以互相”看到”对方的信息,但不会互相干扰参数优化方向。
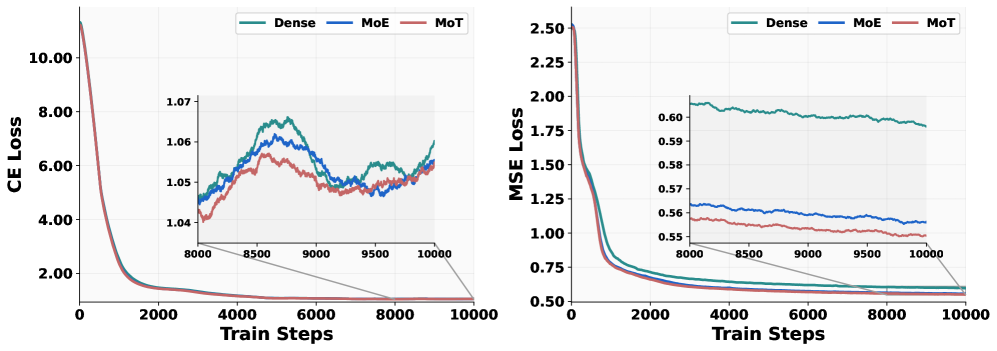
消融:MoT > MoE > Dense
架构 做法 效果 Dense 单 Transformer MSE loss 收敛慢,CE loss 波动大 MoE 只复制 FFN 作为专家 居中 MoT 复制完整 Transformer 作为专家 MSE 和 CE 均最优
Figure 3: Dense vs MoE vs MoT 在 1.5B 规模的 loss 曲线。MoT 在 MSE loss(生成)和 CE loss(理解)上均优于其他架构,且差距在生成任务上最为显著。
结论:理解和生成将模型参数拉向不同的最优区域,需要独立的完整参数空间。只复制 FFN 不够,因为 LayerNorm 和注意力投影也会被两个任务拉向不同方向。
2.1.4 训练目标
每个位置的 token 有不同的 loss:
- Text token:Next Token Prediction(交叉熵 CE loss),权重 0.25
- ViT token:无 loss(纯条件输入,不预测)
- Clean VAE token:无 loss(纯条件输入)
- Noised VAE token:Rectified Flow(MSE loss,预测去噪方向),权重 1.0
时间步 embedding 直接加到 VAE token 的初始 hidden state(而非 AdaLN),架构更简洁。
2.1.5 一次前向传播的数据流
假设输入是一个交错序列:“描述这张图 [Image₁] 再画一个类似的 [Image₂]“
Step 1: 编码
Text → Tokenizer → Text embeddings
Image₁ → SigLIP2 → ViT₁ tokens
Image₁ → FLUX VAE → Clean VAE₁ tokens → +noise → Noised VAE₁ tokens
Image₂ → 同上
Step 2: 拼接成序列
[Text "描述"] [ViT₁] [Clean VAE₁] [Noised VAE₁]
[Text "再画一个类似的"] [ViT₂] [Clean VAE₂] [Noised VAE₂]
Step 3: MoT 前向
- Text + ViT token → 理解专家 FFN
- VAE token → 生成专家 FFN
- 所有 token 共享自注意力
Step 4: Loss
- Text 位置 → CE loss(预测下一个 token)
- Noised VAE 位置 → MSE loss(预测去噪残差)
2.2 广义因果注意力(Generalized Causal Attention)
这是 BAGEL 最精巧的工程设计之一。每个图像在训练中有三组 token:
- 加噪 VAE token:用于 Rectified Flow 训练(MSE loss 计算)
- 干净 VAE token:作为条件供后续 token 参考(t=0 噪声)
- ViT token:统一交错理解与生成的输入格式,提升交错生成质量
注意力规则:
- 同一样本内按模态分组(text / ViT / VAE),组内 causal(文本)或 bidirectional(视觉)
- 后续图像可以 attend 到前面图像的干净 VAE token 和 ViT token,但不能 attend 到加噪 VAE
- 多图像生成采用 Diffusion Forcing:每张图独立加噪级别,条件化于前一张图的噪声表示
- 用 PyTorch FlexAttention 实现,比原生 attention 快 2 倍

Figure 15: BAGEL 的广义因果注意力掩码示意。(a) 交错图文生成:每张图只能 attend 到前面图像的干净 VAE 和 ViT token。(b) 交错多图/视频生成:采用 Diffusion Forcing 策略,每张图条件化于前一张图的噪声表示。
推理时:
- 缓存干净 VAE 和 ViT 的 KV cache
- 图像生成完成后将加噪 VAE 替换为干净版本
- CFG:text dropout 0.1 / ViT dropout 0.5 / clean VAE dropout 0.1
2.3 推理时的图像生成机制
BAGEL 的生成不是纯自回归(逐 token),也不是纯扩散(独立模型),而是自回归框架里的扩散——文本逐 token 自回归,图片在需要时启动 Rectified Flow 并行去噪,两种范式通过共享自注意力统一在同一个 Transformer 里。
2.3.1 扩散侧:Rectified Flow
BAGEL 用 Rectified Flow(和 FLUX、SD3 同一路线),而非传统 DDPM。
训练时:
- 干净图片 → FLUX VAE 编码 → 干净 latent
- 采样时间步 ,加噪:,
- 模型预测速度场 ,目标指向从噪声到干净 latent 的方向
- Loss = MSE:
与 DDPM 的区别:DDPM 预测噪声 ,需要多步 ODE/SDE 求解;Rectified Flow 预测速度场,轨迹更直,推理步数更少,更适合和自回归 Transformer 结合。
推理时:
- 从纯噪声 出发
- 按 逐步去噪:
- 典型 20-50 步得到干净 latent → FLUX VAE 解码器 → 像素图
2.3.2 序列侧:生成怎么被触发
BAGEL 是 decoder-only 自回归模型,所有信息编码在一个 token 序列里。当序列走到需要生成图片的位置时,模型输出 VAE token 而非文本 token。
关键:图片是一次性并行生成的(所有 VAE token 同时去噪),不是逐 token 生成的(那是 Quantized AR 路线,质量差)。
完整推理流程:
[Text "画一只猫"] → 自回归逐 token 生成文本
↓
[Noised VAE tokens] ← 采样纯噪声(对应图片 latent 尺寸)
↓
过 Transformer(共享注意力拿到 text 条件)
↓
预测速度场 vθ
↓
Rectified Flow 迭代去噪(20-50 步,每步重过 Transformer)
↓
[Clean VAE tokens]
↓
FLUX VAE 解码器 → 图片
↓
[Text 继续生成] → 自回归继续(如果需要)
2.3.3 条件注入方式
生成时,图片的条件信息通过共享自注意力注入,不需要额外的 cross-attention 层:
| 条件来源 | 注入方式 | 作用 |
|---|---|---|
| Text token | 注意力 attend | 语义指导(“画什么”) |
| ViT token(前面图片) | 注意力 attend | 视觉参考(“参考这张图”) |
| Clean VAE token(前面图片) | 注意力 attend | 像素级参考(编辑场景) |
| 时间步 | 加到 VAE token 的 hidden state | 告诉模型当前去噪阶段 |
2.3.4 CFG(Classifier-Free Guidance)
- 训练时随机 dropout 条件 token:text 0.1 / ViT 0.5 / clean VAE 0.1
- 推理时做两次前向:一次有条件、一次无条件
- 输出 = 无条件 + guidance_scale × (有条件 − 无条件),scale > 1 增强条件遵循
2.3.5 多图交错生成:Diffusion Forcing
图文交错场景下,生成顺序为:
[Text₁] → 自回归生成
[Image₁] → Rectified Flow(条件:Text₁)
[Text₂] → 自回归(条件:Text₁ + Image₁ 的 clean VAE/ViT)
[Image₂] → Rectified Flow(条件:Text₁ + Text₂ + Image₁)
...依此类推
- 每张图独立加噪级别(不同的 )
- 后面的图通过注意力看到前面图的 clean VAE 和 ViT
- 不能看到前面图的 noised VAE(防止信息泄漏)
- 推理时 KV cache 只存 clean token,生成完一张图后把 noised VAE 替换为 clean 版本
2.4 数据工程:四类交错数据
BAGEL 的数据配方是最核心的贡献之一。
视频交错数据(45M 条):
- 来源:公开在线视频 + Koala36M(教学类)+ MVImgNet2.0(多视角)
- 构建:视频分镜 → 质量过滤(分辨率、清晰度、运动稳定性)→ 帧间变化描述(用蒸馏的轻量 Qwen2.5-VL-7B 生成,限制 30 token 防幻觉)→ 采样平均 4 帧/片段
- 核心价值:提供像素级、概念级、时序和物理连续性的监督信号——“视频是最大、最自然的模拟器”
网页交错数据(20M 条):
- 来源:OmniCorpus(来自 Common Crawl 的图文交错网页)
- 两步过滤:① 轻量 topic 选择(fastText 分类器,蒸馏自 LLM)② 精细规则过滤(去 UI、去模糊、去高文本密度、保留 3-8 图的文档)
- Caption-first 策略:先为每张图生成简短描述插入到图前(概念脚手架),减少图文弱对齐带来的生成难度
- 核心价值:百科文章、教程、设计文档等自然交织的多模态推理监督
推理增强数据(500K 条):
- 受 DeepSeek-R1 启发,在生成前引入语言推理步骤
- 三个来源:① T2I 推理(简短模糊 prompt → CoT 推理 → 详细 prompt → FLUX 生成图)② 自由形式图像编辑(源图+目标图+用户查询+R1 推理链示例)③ 概念编辑(网页交错图中采样图对→VLM 生成推理→质量过滤)
- 核心价值:教会模型”先想再画”
传统图文对数据:VLM 预训练 + T2I 生成对(含 FLUX/SD3 合成数据)
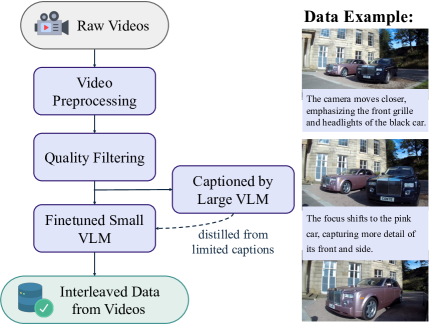
Figure 4: BAGEL 的数据构建流程。(a) 视频交错数据:视频分镜→质量过滤→帧间变化描述→交错序列。(b) 网页交错数据:原始网页→去噪清洗→Caption-first 策略插入描述→结构化交错文档。
2.5 训练策略
四阶段训练(总计约 5.2T tokens):
表:四阶段训练配置
阶段 Tokens 分辨率 关键 Alignment 4.9B 378×378 只训练 MLP connector,对齐 ViT 和 LLM Pre-training (PT) 2.5T 256-512 (gen) / 224-980 (und) 全参数训练,Gen:Und ≈ 4:1 Continued Training (CT) 2.6T 512-1024 (gen) / 378-980 (und) 提升分辨率 + 提高交错数据比例(15-20%) SFT 72.7B 512-1024 / 378-980 高质量子集微调
关键调参发现:
数据采样比:生成数据应远多于理解数据(4:1 ~ 8:1),MSE loss 显著下降而 CE loss 几乎不变。
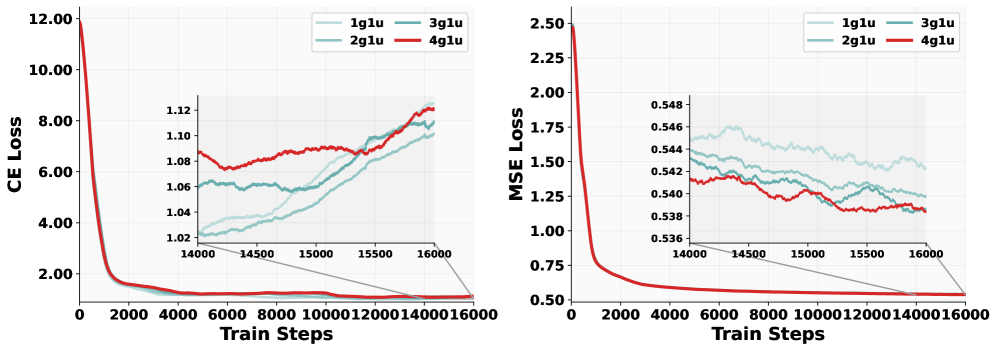
Figure 5: 不同数据采样比的 loss 曲线。“4g1u”(生成:理解=4:1)在 MSE 上有 0.4% 的绝对改善,而 CE loss 几乎不受影响。
学习率 trade-off:大学习率有利于生成(MSE),小学习率有利于理解(CE)→ 分别加权。
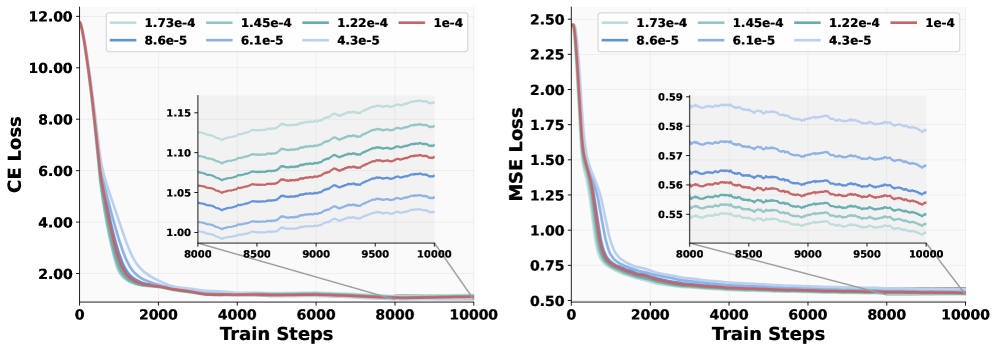
Figure 6: 不同学习率的 loss 曲线。MSE 和 CE 对学习率的需求相反——大学习率加速生成收敛,小学习率保护理解能力。
其他:Constant LR 全程恒定,便于动态扩展训练数据;扩散时间步 shift:分辨率提升时从 1.0 调到 4.0,匹配噪声分布。
3 实验结果
3.1 多模态理解
在 MME、MMBench、MMMU、MM-Vet、MathVista、MMVP 六个 benchmark 上评估。7B 激活参数的 BAGEL 全面超越同等规模的所有统一模型,在多数 benchmark 上超越专用理解模型。
表:多模态理解 benchmark 对比
Type Model # Params MME-P ↑ MME-S ↑ MMBench ↑ MMMU ↑ MM-Vet ↑ MathVista ↑ MMVP ↑ Und. Only InternVL2.5 1.8B - 2138 74.7 43.6 60.8 51.3 - Und. Only Qwen2.5-VL 3B - 2157 79.1 53.1 61.8 62.3 - Und. Only InternVL2.5 8B 1648 2300 82.2 50.1 69.6 65.1 57.3 Und. Only Qwen2.5-VL 7B 1623 2289 82.6 58.6 73.0 68.2 52.7 Unified Janus-Pro 7B 1534 1948 75.6 37.2 50.1 49.0 50.0 Unified Emu3 8B 1556 1972 58.5 31.6 37.2 38.2 50.7 Unified MetaQuery-XL 7B - - 80.9 50.2 64.4 67.5 - Unified BAGEL 7B 1774 2367 85.1 51.5 67.2 73.1 62.0 Janus-Pro-7B 对比:MMMU +14.3,MM-Vet +17.1。BAGEL 在多数指标上超越专用理解模型 Qwen2.5-VL-7B 和 InternVL2.5-7B。
3.2 文本到图像生成
在 GenEval 和 WISE 两个 benchmark 上评估。
表:GenEval(T2I 组合生成能力)
Type Model Single Obj. Two Obj. Counting Colors Position Color Attri. Overall ↑ Gen. Only SD3-Medium 0.99 0.94 0.72 0.89 0.33 0.60 0.74 Gen. Only FLUX.1-dev † 0.98 0.93 0.75 0.93 0.52 0.68 0.82 Unified Janus-Pro-7B 0.99 0.95 0.79 0.93 0.44 0.70 0.80 Unified MetaQuery-XL † 0.98 0.94 0.81 0.94 0.55 0.60 0.80 Unified BAGEL 0.99 0.98 0.89 0.95 0.63 0.76 0.82 Unified BAGEL † 0.99 0.98 0.93 0.97 0.71 0.78 0.88 † 表示使用 LLM rewriter。BAGEL 无 rewriter 即达 82%(平 FLUX),有 rewriter 达 88%。
表:WISE(世界知识推理生成)
Type Model Cultural Time Space Biology Physics Chemistry Overall ↑ Gen. Only FLUX.1-dev 0.48 0.58 0.62 0.42 0.51 0.35 0.50 Unified Janus-Pro-7B 0.30 0.37 0.49 0.36 0.42 0.26 0.35 Unified MetaQuery-XL 0.44 0.47 0.58 0.44 0.52 0.44 0.48 Unified BAGEL 0.49 0.53 0.55 0.45 0.55 0.38 0.49 Unified BAGEL w/ CoT 0.72 0.68 0.74 0.60 0.73 0.54 0.67 Private GPT-4o 0.73 0.75 0.82 0.72 0.81 0.55 0.73 CoT 推理让 WISE 从 0.49 → 0.67,提升 0.18,超越所有开源模型。原生支持中英文 prompt、任意宽高比。

Figure 10: T2I 生成质量定性对比。BAGEL 显著优于 Janus-Pro 7B 和 SD3-medium。
3.3 图像编辑
在 GEdit-Bench、IntelligentBench、RISEBench、KRIS-Bench 四个 benchmark 上评估。
表:GEdit-Bench(经典图像编辑)
Type Model G_SC ↑ G_PQ ↑ G_O ↑ Private Gemini 2.0 6.73 6.61 6.32 Private GPT-4o 7.85 7.62 7.53 Open-source Instruct-Pix2Pix 3.58 5.49 3.68 Open-source OmniGen 5.96 5.89 5.06 Open-source Step1X-Edit 7.09 6.76 6.70 Open-source BAGEL 7.36 6.83 6.52 G_SC=语义一致性,G_PQ=感知质量,G_O=整体得分。BAGEL 在 SC 和 PQ 上超越 Gemini 2.0,与 Step1X-Edit 竞争。
表:IntelligentBench(推理编辑,本文新提出)
Type Model Score ↑ Private GPT-4o 78.9 Private Gemini 2.0 57.6 Open-source Step1X-Edit 14.9 Open-source BAGEL 44.9 Open-source BAGEL w/ Self-CoT 55.3 BAGEL 是 Step1X-Edit 的 3 倍;加 CoT 后 55.3,接近 Gemini 2.0。
表:RISEBench(推理编辑)
Type Model Temporal Causal Spatial Logical Overall ↑ Private GPT-4o 34.1 32.2 37.0 10.6 28.9 Private Gemini 2.0 8.2 15.5 23.0 4.7 13.3 Open-source Step1X-Edit 0.0 2.2 2.0 3.5 1.9 Open-source BAGEL 2.4 5.6 14.0 1.2 6.1 Open-source BAGEL w/ Self-CoT 5.9 17.8 21.0 1.2 11.9
表:KRIS-Bench(知识推理编辑)
Type Model Factual (AP/SP/TP) Conceptual (SS/NS) Procedural (LP/ID) Overall ↑ Private GPT-4o 83.2/79.1/68.3 85.5/80.1 71.6/85.1 80.1 Private Gemini 2.0 66.3/63.3/63.9 68.2/56.9 54.1/71.7 62.4 Open-source Step1X-Edit 55.5/51.8/0.0 44.7/49.1 40.9/22.8 43.3 Open-source BAGEL 64.3/62.4/42.5 55.4/56.0 52.5/50.6 56.2 Open-source BAGEL w/ Self-CoT 67.4/68.3/58.7 57.6/60.4 55.2/55.5 60.2 AP=属性感知,SP=空间感知,TP=时间预测,SS=社会科学,NS=自然科学,LP=逻辑推理,ID=指令分解。
CoT 推理的系统性提升:在所有编辑 benchmark 上,加入显式 CoT 思考后性能均大幅提升。说明模型内部化了推理能力,不是简单的 prompt engineering;推理增强在需要世界知识的复杂任务上收益最大。
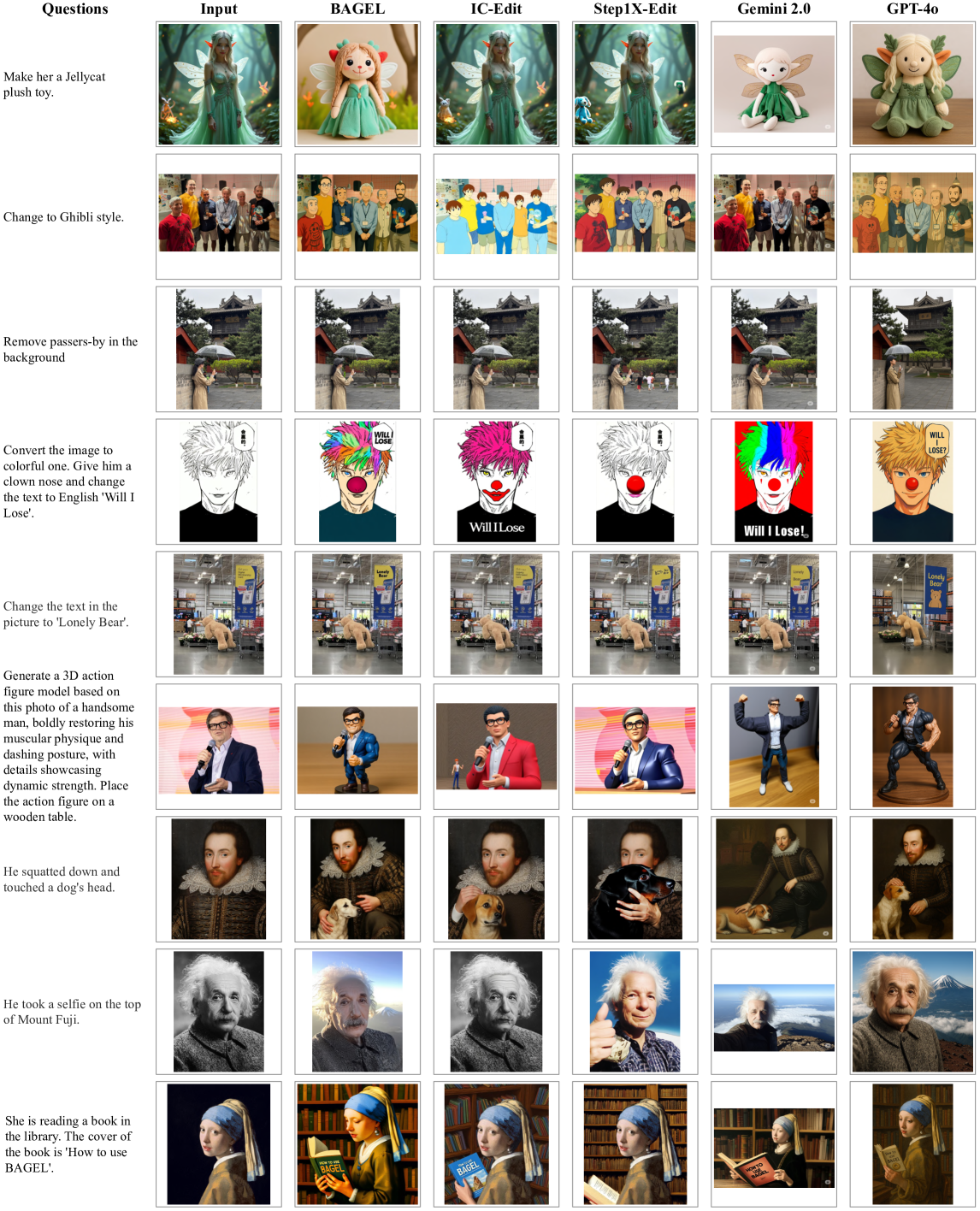
Figure 11: 图像编辑与操控定性对比。BAGEL 在多种编辑场景下展现了优于 Step1X-Edit、IC-Edit 和 Gemini 2.0 的一致性和指令遵循能力。

Figure 12: IntelligentBench 上的定性对比。BAGEL 能处理需要多步推理和世界知识的复杂编辑任务(如”将苹果logo变成毕加索风格”),而 Step1X-Edit 往往直接复制输入图像。

Figure 13: “先思考再生成”的有效性。(a) T2I 生成:仅给简短 prompt 时失败,加入 CoT 推理后成功生成正确图像。(b) 智能编辑:CoT 推理显著提升了需要世界知识和多步推理的编辑质量。
3.4 涌现现象
通过回溯历史 checkpoint,发现不同能力的收敛阶段截然不同(以达峰值 85% 所需 token 衡量):
表:不同能力的收敛速度
能力 达 85% 所需 token 性质 图像理解 0.18T 最早收敛 T2I 生成 0.68T 较早收敛 经典图像编辑 2.64T 缓慢提升 智能编辑(推理) 3.61T 涌现式增长
智能编辑在 3T token 后才出现突变式提升(15→45),而传统编辑任务在分辨率提升后变化不大——这说明复杂多模态推理是一种真正的涌现能力,不是 loss 曲线能预测的。
定性观察也佐证了这点:3.5T 前,模型在复杂编辑任务上倾向”回退”到复制输入图;3.5T 后开始展现清晰的多步推理和语义编辑。
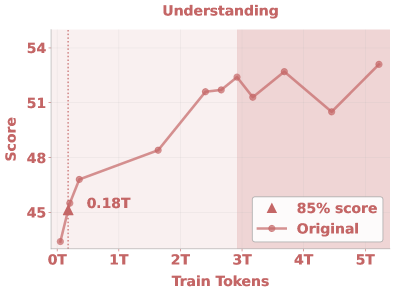
Figure 7: 不同能力的收敛速度对比。理解和生成 benchmark 在早期(0.18T/0.68T)即达峰值 85%,经典编辑需要 2.64T,而智能编辑在 3.61T 后才出现涌现式突变。
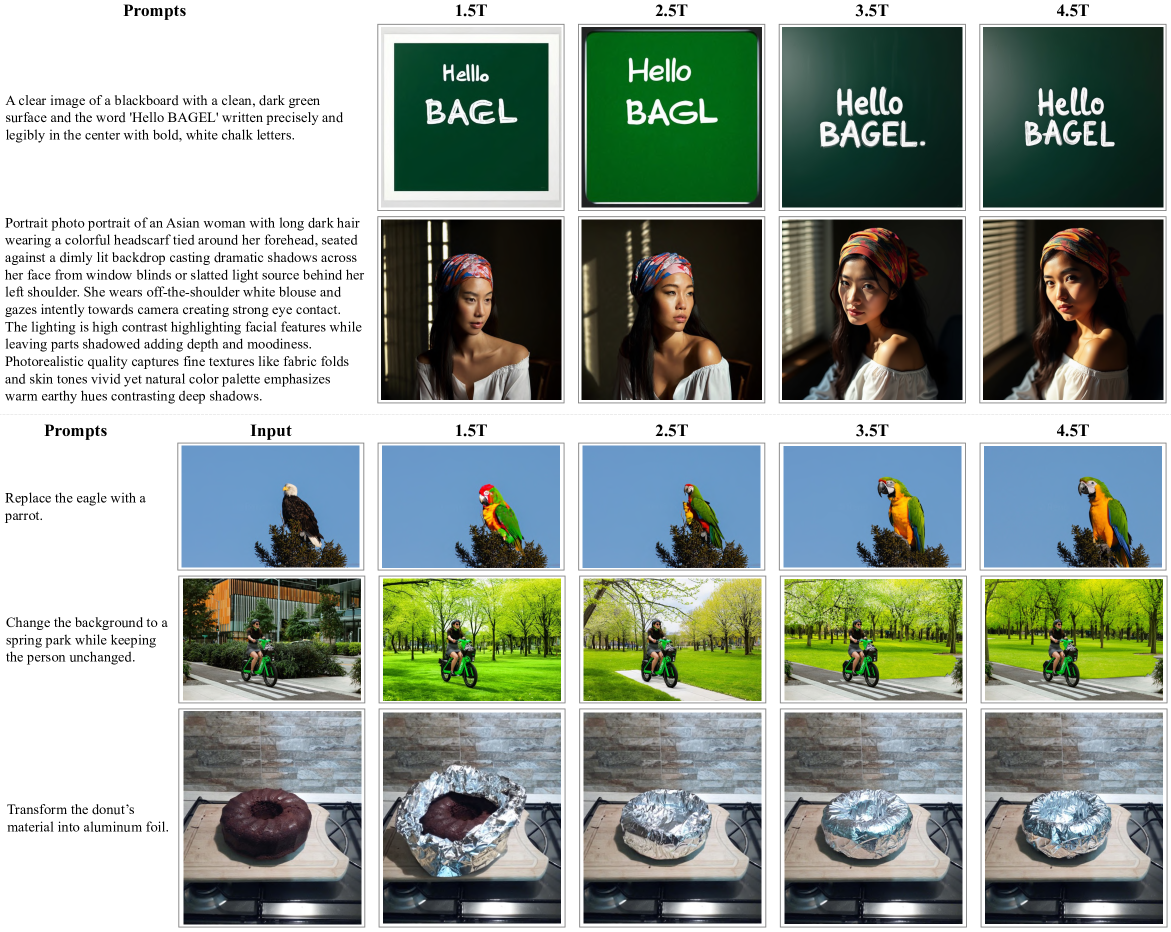
Figure 8: 不同训练 token 量的 T2I 和编辑效果对比。生成质量在 1.5T 前已较强,之后分辨率提升带来小幅改善。文字渲染能力(如正确拼写”hello”和”BAGEL”)在 1.5T~4.5T 之间涌现。
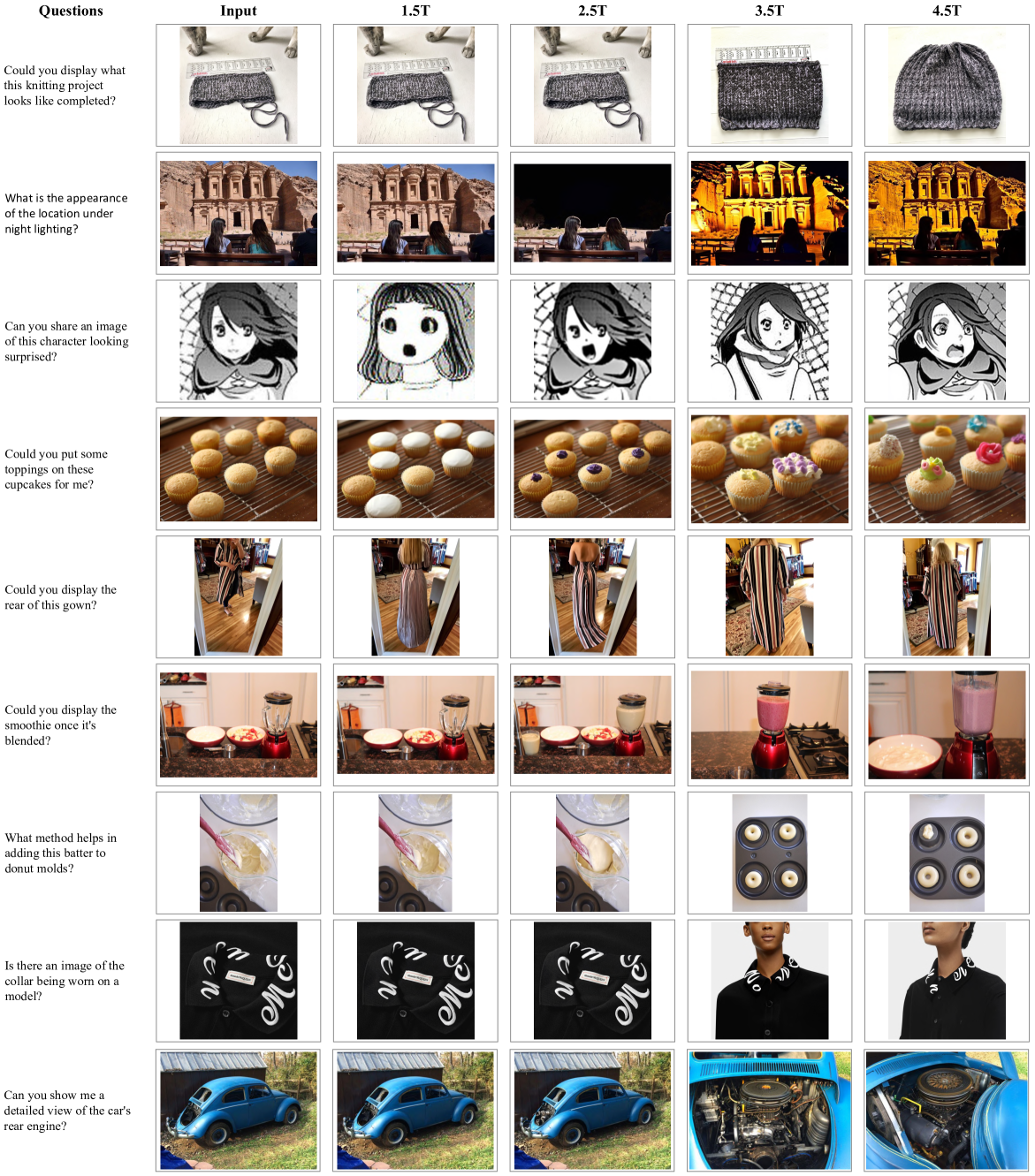
Figure 9: 智能编辑任务的涌现行为。3.5T 前模型倾向”回退”到复制输入图(不理解任务时的 fallback 策略);3.5T 后开始展现清晰推理和语义编辑——这是一种无法从 loss 曲线预测的质变。
3.5 世界建模
通过在 video + navigation 数据上微调,BAGEL 展示了:
- 世界导航:沿着相机轨迹生成后续视角
- 旋转:旋转输入图生成新视角
- 多帧生成:给定 prompt 生成多张连续图像
- 跨域泛化:仅在真实街景导航数据上训练,能泛化到水墨画、卡通、游戏等完全不同的域

Figure 14: BAGEL 的世界建模能力展示。包括世界导航(沿相机轨迹前进)、旋转(改变视角)、多帧生成(给定 prompt 生成连续图像序列),以及跨域泛化(从真实街景泛化到水墨画、卡通等)。
4 结论
BAGEL 证明了:在统一多模态预训练中规模化交错数据可以涌现出复杂多模态推理能力。其 MoT 架构有效分离了理解和生成的参数空间,广义因果注意力方案优雅地处理了多模态交错序列的训练和推理。通过开源的模型、数据和训练协议,BAGEL 为多模态研究社区提供了一个强大的基础。
5 思考
5.1 优点
-
数据哲学的正确性:论文的核心论点是”多模态交错数据是关键”,并用系统的消融证据(涌现现象、不同阶段的收敛速度)支撑了这个论点。这比架构创新更深层——它回答了”真正的统一多模态能力从何而来”。
-
MoT 的消融实验严谨:在 1.5B 规模上做了 Dense vs MoE vs MoT 的公平对比,证明 MoT 的优势。结论”理解和生成将参数拉向不同方向”有实验支撑而非空谈。
-
广义因果注意力的精巧设计:三组 token(加噪 VAE / 干净 VAE / ViT)的分工和注意力规则设计精巧而实用。在保持扩散训练范式的同时支持了多模态交错的训练和推理,是一个前后一致的方案。
-
推理增强数据的方法论贡献:用 DeepSeek-R1 的推理链 + FLUX 的生成能力,构建了让模型”先思考再生成”的训练数据。这种”用已有模型的能力合成下一阶段训练数据”的方法,是 scaling 时代的核心方法论。
-
开源度:模型权重、训练协议、数据创建流程全部开源。在 GPT-4o 的技术细节完全保密的情况下,BAGEL 提供了研究多模态涌现的宝贵实证数据。
5.2 缺点与待解决问题
-
推理增强数据的”蒸馏天花板”:推理增强数据由 DeepSeek-R1 生成推理链 + FLUX 生成目标图。那么 BAGEL 的推理能力本质上受限于这两个 teacher 模型。它学会的是”模仿推理”,还是获得了真正的推理能力?论文没有给出在这方面的分析。
-
涌现的因果关系未严格证明:论文声称交错数据是涌现的原因,但涌现可能也来自模型规模、训练时长等的交互。缺少”控制数据量、改变交错比例”的严格因果实验。
-
与 GPT-4o 的差距仍然显著:在 WISE(世界知识推理生成)上,BAGEL+CoT 的 70% vs GPT-4o 的 80% 仍有 10 个点的差距。在 IntelligentBench 上差距更大(55.3 vs 78.9)。数据规模和模型容量的进一步扩展能缩小多大差距,是未知数。
-
世界建模能力的边界不清晰:导航/旋转/多帧生成的展示令人印象深刻,但只展示了”works”的案例。对视角切换的精确度、长序列的一致性、复杂场景下的失败模式等,论文没有系统评估。
-
训练成本的完整披露不足:论文给出了训练 token 数和架构参数,但没有报告总 GPU 小时或能耗。考虑到 Integrated Transformer 路线的训练成本远高于 External Diffuser 路线,这对社区评估技术路线的可行性很重要。
5.3 与已有 Wiki 的连接
- 关联概念:原生多模态模型、MoE 混合专家模型(MoT 是 MoE 的衍生)、DiT 扩散 Transformer、Flow Matching、知识蒸馏(推理增强数据本质上是蒸馏 DeepSeek-R1)
- 关联实体:BAGEL、GPT-4o、FLUX
- 关联比较:统一多模态模型架构比较、扩散模型架构比较 UNet vs DiT
- 关联问题:多模态模型的最终形态是原生统一还是模块化组装
5.4 与同期统一多模态模型的对比
| 维度 | BAGEL | OmniGen2 | Tuna-2 | Lumina-DiMOO | UniWorld-V1 |
|---|---|---|---|---|---|
| 架构 | MoT(双专家共享注意力) | VLM+DiT(解耦) | 单 Transformer,无编码器 | 单 Transformer(离散扩散) | VLM+SigLIP+FLUX |
| 统一程度 | 高(共享注意力) | 中(两个独立模型) | 高(单一 Transformer) | 最高(同一机制) | 低(三个独立模型) |
| 训练数据 | ~1.6B(最多) | 140M+10M | 中等 | 80M+15M | 2.7M(最少) |
| 核心策略 | 数据 scaling | RL alignment | 架构简化 | 范式统一 | 架构洞察 |
| 涌现能力 | 世界建模、3D 操控、导航 | — | — | — | — |
| GenEval | 0.88 | 0.95 | competitive | 0.88 (0.91) | — |
关键洞察:
- 数据 scaling 的独特价值:BAGEL 是五篇中唯一强调”数据 scaling 涌现”的论文。其他四篇聚焦于架构或训练技巧,BAGEL 证明了在万亿 token 级交错数据上训练会涌现出传统 benchmark 无法捕获的能力(世界建模、3D 操控)。这是其他模型未复制的。
- MoT 的工程代价:MoT 需要 14B 总参数(7B×2),训练成本高于其他方案。但共享注意力的信息流通是其他方案无法替代的——OmniGen2 的 VLM 冻结、UniWorld-V1 的模块化设计都限制了跨模态信息的深度交互。
- BAGEL 的短板:GenEval(0.88)低于 OmniGen2(0.95),说明纯靠数据 scaling 不如 scaling + RL alignment。BAGEL 没有做 RL 对齐,是其与 OmniGen2 的最大差距。