本文提出了一种名为 VisionCreator 的原生视觉生成代理模型,在一个端到端的可学习框架中统一了理解(Understanding)、思考(Thinking)、规划(Planning)和创造(Creation)能力,以自主完成复杂的多步视觉内容生成任务 。
Intro
Motivation
新的需求 要求AI 系统不仅要有生成能力,还要能够理解创作意图、规划多步操作,并自主执行复杂的工作流程 。
目前的问题与局限性
目前的自主视觉创建方法主要分为三种范式,均存在明显局限:
-
通用统一多模态模型 (UMM):依赖大规模预训练,视觉理解能力强,但缺乏领域特定知识,无法在没有大量 prompt engineering 的情况下自主进行复杂的创意目标分解和规划 。
-
特定工作流代理 (Workflow-specific Agent):采用为特定领域(如电影或故事生成)预先定义好的固定流水线,架构僵化,无法适应多样化的创作任务或处理执行中的意外情况 。
-
工作流引导代理 (Workflow-guided Agent):使用通用大语言模型作为大脑,通过精心设计的 prompt 来编排外部工具 。这种方法的局限在于:依赖提示工程而非模型内化的领域知识;显式编程的协调逻辑限制了适应性;无法针对整体的创作任务性能进行端到端的联合优化 。
原生代理模型面临三大挑战:数据瓶颈(缺乏具有 UTPC 结构的高质量轨迹数据)、任务复杂性(任务类型多样、难度大、执行步骤超20步)、训练难度大(SFT容易导致灾难性遗忘,而在线 RL 调用真实工具成本高昂且极不稳定)
解决方案
为了解决上述问题,本文提出了 VisionCreator 及其配套体系 :
-
数据集构建:利用基于元认知的 VisionAgent 框架,结合算法过滤与严格的人工审查,构建了 VisGenData-4k 数据集,提供了富含 UTPC 结构的复杂生成轨迹 。
-
两阶段训练范式:
-
渐进式专业化训练 (PST):分阶段将模型从通用推理能力平滑过渡到视觉生成专业能力,避免了灾难性遗忘,并为 RL 提供了极佳的初始化策略 。
-
虚拟强化学习 (VRL):构建了高保真的虚拟环境 VisGenEnv(模拟了 36 种工具的行为),并在其中使用基于长期轨迹推理的长程奖励(LtrReward,包含计划奖励 和细粒度奖励 )进行端到端的 RL 训练,彻底绕过了昂贵的 API 调用成本 。
-
-
全新的 Benchmark:提出了 VisGenBench,包含 1.2k 测试样本,跨越 10 个评估维度,填补了多步视觉生成工作流评估的空白
Method
1. 包含 UTPC 结构的 VisGenData-4k 数据集构建 没有高质量轨迹,模型就无法学习如何规划。作者设计了一个基于元认知的双智能体 VisionAgent 框架来合成数据 :
-
TaskAgent(分类与路由):分析用户输入,将其分类到 21 种具体任务类型中,并分配对应的模板和工具池 。
-
MetaAgent(元认知推理核心):它不只是生成代码,而是严格遵循四步元认知过程:
-
<think>:评估当前状态并维护待办事项列表(Todo List)。 -
<plan>:将目标分解,构建可执行的任务依赖序列 。 -
<tool_call>:根据蓝图调用具体的生成工具 。 -
<answer>:验证目标是否完成,形成闭环 。 最终,经过大规模生成、基于 LLM 的严格奖励过滤以及人工二次审查,保留了 4k 条包含丰富上下文和极长轨迹(平均 15 步,最高超 20 步)的高质量训练数据 。
-
2. 渐进式专业化训练 (Progressive Specialization Training, PST)
如何将一个通用 VLM 转化为专用的视觉生成智能体?
-
如果仅用
VisGenData-4k进行 SFT,会导致模型产生“灾难性遗忘”,丧失通用推理能力(实验证明其成功率几乎掉到 0)。 -
如果将通用数据 和视觉数据 一起混合训练,由于通用数据占比太大,模型无法有效收敛出专业的视觉规划能力 。
-
PST 的具体步骤:
-
Stage 1(基础构建):使用大量通用推理数据配以极少量视觉数据(公式 2),让模型在保留基础通用能力的同时,初步锚定视觉领域的思维模式 。
-
Stage 2(定向专门化):减少通用数据比例,增加视觉数据的影响权重(公式 3),驱动模型向视觉创造领域深耕 。PST 不仅提升了 SFT 的上限,还为后续的强化学习提供了一个得分更高、收敛更快(快 50%)的初始策略点 。
-
3. 在 VisGenEnv 中的虚拟强化学习 (VRL) RL 的难点在于在线反馈。如果让模型在训练时反复调用真实的文本到视频模型,成百上千次并发 rollout 会消耗极度恐怖的算力(数千张 GPU)。
-
虚拟环境模拟:作者构建了 VisGenEnv,模拟了 36 种真实的 API 工具 。当智能体请求生成图片或视频时,环境并不去跑耗时的生成模型,而是通过程序逻辑验证参数,并从数据库中随机抽取具有正确物理属性(如特定分辨率、时长)的媒体文件返回 。这使得模型可以几乎零成本地在虚拟沙盒中试错,专门训练其“规划和工具调用逻辑” 。
-
LtrReward 设计:RL 使用 GRPO 算法。奖励函数由两部分相乘构成:
-
(计划奖励):由 vPlanJudger(基于 LLM)评估,考核需求是否满足、逻辑是否连贯、任务分解的原子性等 。
-
(细粒度执行奖励):规则基评估(如格式规范、API调用成功率)与效果基评估(如最终数量是否达标)。
-
乘法耦合():这意味着只有在一个合理的规划下,成功执行 API 才有意义。如果瞎调 API 虽然成功了但计划是错的,奖励依然很低 。
-
-
理论保证:论文通过 Theorem 4.1 和 4.2 证明了只要虚拟环境的工具模拟保真度足够高( 接近1),在虚拟环境中依靠结构代理奖励训练出的逻辑提升,能够有效抵消 Sim-to-Real 的迁移误差,并最终转化为真实世界中视觉质量的实际提升 。
实验/评估/结果
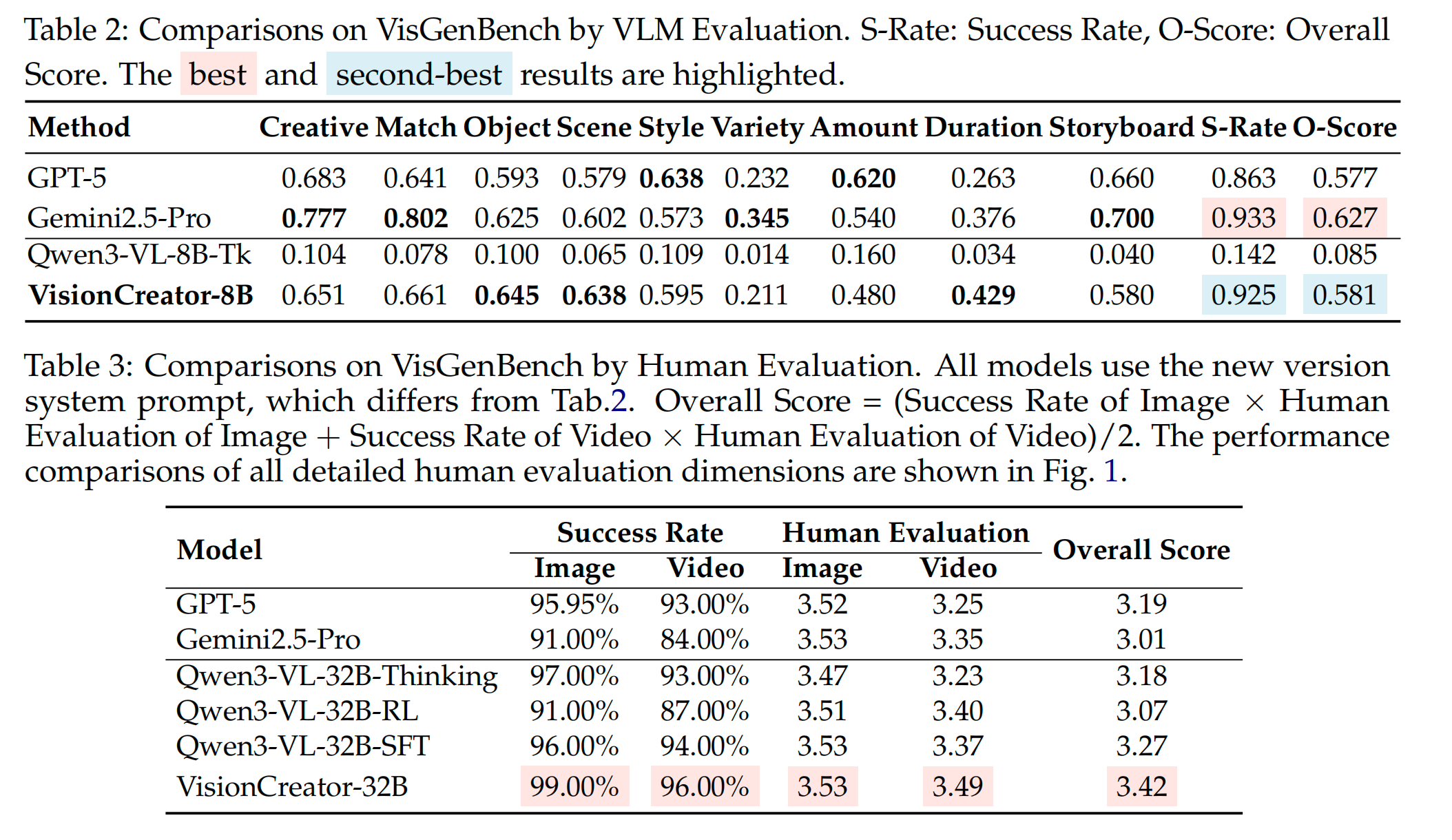
1. 基准测试 VisGenBench 为了标准化多步视觉智能体的评估,作者构建了 VisGenBench,包含 400 个图像任务和 800 个视频任务,涵盖广告、短剧等 35 个真实场景,涉及一致性、多模态融合等 10 个评估维度 。
2. 评估方式 结合了客观计算(API 成功率、生成数量、视频时长)和基于定制化 rubric 的 VLM 裁判(通过 Gemini 2.5 Pro 进行细粒度评分,并与人类偏好对齐)。
结论
本文成功将理解、思考、规划和创造融合到一个原生视觉生成智能体 VisionCreator 中 。通过元认知引导的高质量数据集构建(VisGenData-4k)、避免灾难性遗忘的渐进式专业化训练(PST),以及大幅降低算力成本的高保真虚拟强化学习(VRL),该模型在 VisGenBench 评测中展现了优于主流巨型闭源大模型的复杂多步生成能力。这项工作为未来多模态自主创意内容的生成打下了坚实的范式基础 。
思考
解决对齐成本:多步生成任务的 RL 惩罚极其难以设计。文章最大的亮点在于解耦了“生成质量评价”与“规划逻辑评价”。通过构建 VisGenEnv 虚拟沙盒环境,用结构化的成功(生成了几个文件、时长多少)代替视觉审美上的成功。这种 Sim-to-Real 的思路极大地释放了计算资源。这对于需要 fine-tune 大规模模型(比如基于 Qwen-Image-Edit 底座进行长链路强化学习)但受限于 GPU 算力的研究来说,提供了一条极具启发性的“伪环境 RL”路线。