推荐算法阅读笔记
📚 本笔记整理推荐算法领域的关键技术与研究进展,重点关注生成式推荐范式。
1. 推荐系统概述
1.1 核心要素
- 三元组:用户 - 物品 - 场景
1.2 推荐范式对比
| 范式 | 核心思想 | 流程 |
|---|---|---|
| 判别式推荐 | 对候选物品进行打分,排序选 Top | 召回 → 排序 → 后处理 |
| 生成式推荐 | 自回归解码直接生成推荐序列 | 端到端单一过程 |
判别式推荐流程
- 召回阶段:从海量物品中筛选出一小部分候选物品
- 排序阶段:对候选物品进行精细打分
- 后处理阶段:多样性调整、冷启动处理等
生成式推荐特点
- 输入:用户历史交互序列 + 当前场景
- 输出:推荐物品序列
- 优势:将多阶段级联压缩为端到端的单一过程
2. 生成式推荐基础
2.1 模型架构
| 架构类型 | 特点 | 适用场景 |
|---|---|---|
| Decoder-only | 架构简单,训练推理效率高 | 大规模推荐,与 LLMs 高度契合 |
| Encoder-decoder | 编码器理解用户历史,解码器生成结果 | 输入输出异构场景 |
Decoder-only 架构
- 输入:用户历史交互序列 + 当前场景信息
- 输出:推荐物品序列
- 优点:架构简单,训练和推理效率较高
Encoder-decoder 架构
- 编码器:生成上下文表示
- 解码器:基于上下文表示生成推荐物品序列
- 优点:适合输入输出异构场景
- 缺点:复杂度更高
2.2 Tokenizer 技术
物品如何被转化为模型可处理的 token 是关键问题。
ID 范式对比
| 范式 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 稀疏 ID | 每个物品分配唯一 ID | 简单直接 | 词表过大,泛化差 |
| 文本 ID | 物品属性文本分词 + 文本 tokenizer | 利用预训练语言模型能力 | 难以映射回具体物品 |
| 语义 ID | 物品属性编码为连续语义向量 | 捕捉语义关系 | 需设计编码器和距离度量 |
端到端离散化技术
将连续表示映射为离散 token 的方法:
-
VQ-VAE
- 在编码器输出和解码器输入之间引入离散代码表
- 通过向量量化映射连续表示为离散代码
-
RQ-VAE (残差量化 VAE)
- 引入残差量化机制,使用多个代码表逐步量化残差
- 将语义空间扩展到 L^N 级别
-
RQ-Kmeans
- 步骤1:使用表示学习模型获得物品连续向量
- 步骤2:执行 K-means 聚类构建码本
-
RQ-OPQ
- 步骤1:获得物品连续向量
- 步骤2:使用 OPQ (Optimized Product Quantization) 优化旋转和量化
3. Scaling Laws in Recommender Systems
3.1 Scaling Law 的首次探索
统一序列建模
将推荐过程视为两个交织的随机过程:
- 推荐系统展示内容
- 用户产生行为反馈
通过对用户行为序列进行建模,捕捉用户兴趣的动态变化。
HSTU 模型
基于 Transformer 架构的改进:
| 改进点 | 方法 | 效果 |
|---|---|---|
| Pointwise Aggregation | 代替 softmax | 降低计算复杂度,处理更长序列;避免竞争问题,捕捉多样性 |
| 位置编码重设计 | 根据位置、时间、类型等因素生成 | 更好地捕捉时序和类型信息 |
GenRank
- 将用户行为与物品结合建模
- 物品 embedding + 用户行为 embedding 相加
- 将序列长度减半
3.2 MTGR:混合范式建模
Motivation
完整的行为序列建模不能使用交叉特征(如用户对某物品的历史点击率)
方法论
将同一用户的多个候选聚合到一个样本中:
| 部分 | 内容 | 说明 |
|---|---|---|
| 历史部分 | User, Seq, RealTime | 与 HSTU/GenRank 一致,完整行为序列 |
| 候选部分 | Cross, Item | 待预测目标,直接包含交叉特征 |
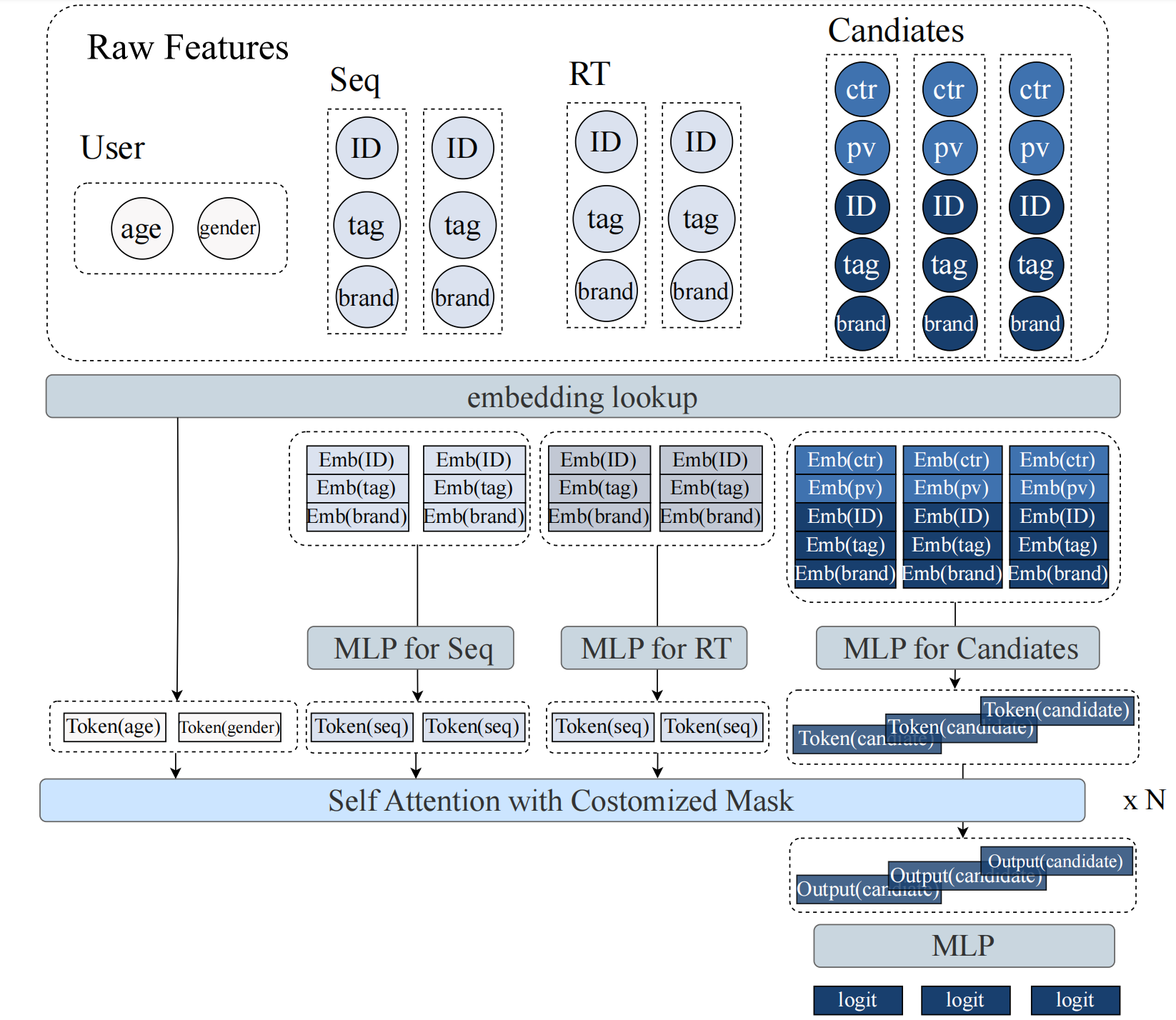
技术细节
- Group LN:代替 LayerNorm,处理不同类型的序列
- Dynamic Masking:确保模型只能访问历史信息,避免信息泄露
- 规则1:静态序列对所有 token 可见
- 规则2:动态序列遵循因果性
- 规则3:候选之间相互独立
3.3 OneTrans
核心思想:将”行为序列”和”非序列特征”统一 token 化,用同一套因果 Transformer 主干,同时完成:
- 序列建模
- 特征交互
4. 端到端生成式推荐
OneRec
⏳ 待补充…
📋 研究脉络总结
判别式推荐 (传统)
│
▼
生成式推荐 (新范式)
│
├── 架构选择:Decoder-only vs Encoder-decoder
│
├── Tokenizer 设计
│ ├── ID 范式:稀疏 / 文本 / 语义
│ └── 离散化:VQ-VAE / RQ-VAE / RQ-Kmeans / RQ-OPQ
│
└── Scaling Laws 探索
├── HSTU (序列建模改进)
├── GenRank (序列压缩)
├── MTGR (混合范式 + 交叉特征)
└── OneTrans (统一 token 化)