Zhanyu Liu , Shiyao Wang , Xingmei Wang, Rongzhou Zhang, Jiaxin Deng,
Honghui Bao, Jinghao Zhang, Wuchao Li, Pengfei Zheng, Xiangyu Wu,
Yifei Hu, Qigen Hu, Xinchen Luo, Lejian Ren, Zixing Zhang,
Qianqian Wang, Kuo Cai, Yunfan Wu, Hongtao Cheng, Zexuan Cheng,
Lu Ren, Huanjie Wang, Yi Su, Ruiming Tang, Kun Gai, Guorui Zhou †
Kuaishou Inc., Beijing, China
{liuzhanyu,wangshiyao08,zhouguorui}@kuaishou.com
*: Equal contributions.†: Corresponding Author.
Abstract
The powerful generative capacity of Large Language Models (LLMs) has instigated a paradigm shift in recommendation. However, existing generative models (e.g., OneRec) operate as implicit predictors, critically lacking the capacity for explicit and controllable reasoning—a key advantage of LLMs. To bridge this gap, we propose OneRec-Think, a unified framework that seamlessly integrates dialogue, reasoning, and personalized recommendation. OneRec-Think incorporates: (1) Itemic Alignment: cross-modal Item-Textual Alignment for semantic grounding; (2) Reasoning Activation: Reasoning Scaffolding to activate LLM reasoning within the recommendation context; and (3) Reasoning Enhancement, where we design a recommendation-specific reward function that accounts for the multi-validity nature of user preferences. Experiments across public benchmarks show state-of-the-art performance. Moreover, our proposed “Think-Ahead” architecture enables effective industrial deployment on Kuaishou, achieving a 0.159% gain in APP Stay Time and validating the practical efficacy of the model’s explicit reasoning capability.
OneRec-Think: In-Text Reasoning for Generative Recommendation
Zhanyu Liu , Shiyao Wang , Xingmei Wang, Rongzhou Zhang, Jiaxin Deng, Honghui Bao, Jinghao Zhang, Wuchao Li, Pengfei Zheng, Xiangyu Wu, Yifei Hu, Qigen Hu, Xinchen Luo, Lejian Ren, Zixing Zhang, Qianqian Wang, Kuo Cai, Yunfan Wu, Hongtao Cheng, Zexuan Cheng, Lu Ren, Huanjie Wang, Yi Su, Ruiming Tang, Kun Gai, Guorui Zhou † Kuaishou Inc., Beijing, China {liuzhanyu,wangshiyao08,zhouguorui}@kuaishou.com
† †
1 Introduction

Figure 1: Examples of OneRec-Think’s Unified Dialogue, Reasoning and Recommendation Framework.
The rapid advancement of Large Language Models (LLMs) has fundamentally reshaped recommender systems, ushering in the generative retrieval paradigm(GR) 1 2 3 4 5. This approach represents a profound shift from traditional query-candidate matching, utilizing Transformer-based sequence-to-sequence models to autoregressively decode the identifiers of target candidates. Capitalizing on this, a major research frontier is the development of end-to-end generative frameworks, including OneRec, OneLoc, OneSug, and OneSearch 6 7 8 9 10 11. These unified models replace the traditional multi-stage recommendation funnel (involving separate retrieval and ranking stages), enabling holistic optimization towards the final objective and concentrating computational resources for better industrial scaling and performance.
While these models successfully harness the LLMs’ capacity for output generation, they fundamentally lack the explicit, verifiable reasoning pathways that define modern LLM breakthroughs, such as text-based Chain-of-Thought (CoT) 12 13 14. To bridge this critical gap, we propose OneRec-Think, a novel framework that integrates dialogue, reasoning, and personalized generative recommendations within a single, unified model. It is capable of generating high-quality, interpretable textual reasoning paths, significantly enhancing both recommendation accuracy and user trustworthiness. The model’s inherent dialogic nature further enables dynamic tailoring of suggestions to specific user constraints (as shown in Fig. 1). Our approach is realized through a three-stage framework: (1) Itemic Alignment, which maps item semantics into the LLM’s textual embedding space, establishing a unified representational continuum that unlocks the model’s capacity for reasoning. (2) Reasoning Activation, which aims to induce the LLM’s inherent reasoning ability directly within the context of recommender systems; (3) Reasoning Enhancement, which utilizes a recommendation-specific reward function that captures the multi-validity (i.e., multiple valid choices) nature of user preferences. Furthermore, we introduce the OneRec-Think Inference Architecture to ensure efficient deployment and real-time responsiveness in industrial-scale serving scenarios. Our contributions are summarized as follows:
- We introduce a unified framework that bridges the semantic gap between discrete recommendation items and continuous reasoning spaces, enabling seamless integration of personalized recommendation within LLMs’ natural language understanding.
- We design a novel reasoning paradigm that orchestrates multi-step deliberation with recommendation optimization, achieving interpretable and accuracy-aware personalized recommendation through synergistic training.
- The proposed approach achieves state-of-the-art results on multiple public benchmarks, while our deployment-friendly “Think-Ahead” architecture enables significant industrial impact with a 0.159% gain in APP Stay Time.
2 Related Work
2.1 Reasoning in Large Language Models
Large language models achieve complex reasoning through various prompting techniques, with CoT prompting 15 being the foundational approach that decomposes problems into intermediate reasoning steps. This has inspired numerous extensions including zero-shot CoT 16, self-consistency decoding 17, and tree-of-thoughts 18. These techniques enable test-time scaling where additional computational budget during inference improves performance 19. Recent work has shifted focus from prompting to post-training enhancement of reasoning capabilities by using techniques such as Reinforcement Learning. Models including DeepSeek-R1 20 and Seed-1.5 21 optimize reasoning behaviors via techniques such as GRPO 22, DAPO 23, and VAPO 24, which demonstrates promising advancements in this direction.
2.2 Reasoning-Based Recommendation
Although generative recommendation models such as TIGER 12, HSTU 25, and OneRec 7 have demonstrated effectiveness, they inherently lack reasoning capabilities. Recently, the Reasoning-based recommendation systems aim to perform multi-step deduction for more accurate and interpretable recommendations. Existing approaches fall into two categories: explicit reasoning methods generate human-readable rationales but are confined to discriminative tasks 26 27 28 29, while implicit reasoning methods 30 31 perform latent reasoning without textual interpretability. Our work introduces explicit reasoning into generative recommendation, bridging this gap to enable both interpretable rationales and scalable item generation.
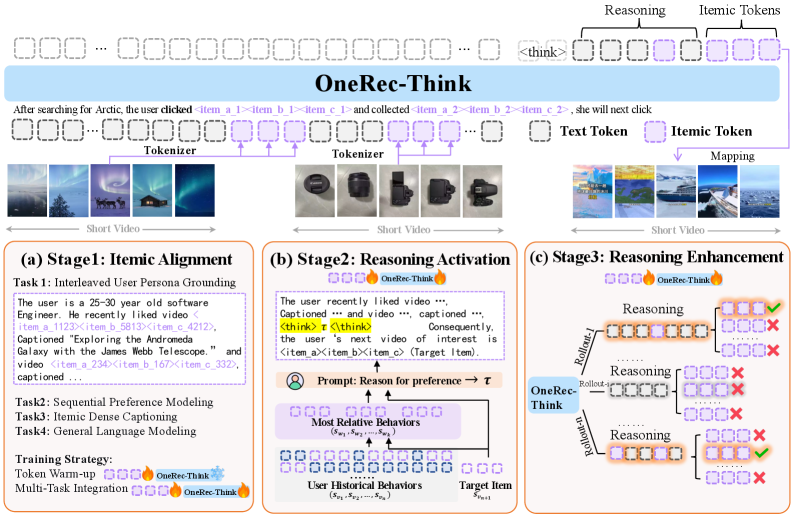
Figure 2: The framework of the OneRec-Think. In the first stage, we achieve item-level semantic alignment through multi-task pre-training. In the second stage, we activate explicit reasoning by prompting the model to generate preference rationales. In the third stage, we refine the reasoning paths through RL based on a reward tailored for recommendations.
3 Preliminary
Itemic Token
An itemic token is a discrete, semantic-rich representation unit for an item, analogous to a word token in natural language. Following OneRec 7 12, we map each item to a sequence of such tokens , which are generated from the item’s multi-modal and collaborative content.
Problem Definition
Let and denote the sets of users and items, respectively. Each user has a chronological interaction history of length . For brevity, we omit the user index . By using the itemic tokens, the user’s interaction history is thus represented by the sequence .
Conventional generative recommenders 12 7 8 13 define their task with a generation target of the next itemic tokens as:
In contrast, we reformulate this task to unify reasoning and recommendation in a single autoregressive pass. Conditioned on a prompted user history, we generate tokens sequentially, beginning with a reasoning sequence and concluding with the next itemic tokens . This end-to-end process is captured by:
where means a valid prompt constructed for the recommendation.
4 Methodolody
We now present OneRec-Think, a scalable framework for end-to-end generative reasoning recommendation. Our approach comprises three core components: an Itemic Alignment stage, a Reasoning Activation stage, and a “Think Ahead” architecture for industrial deployment. The illustration of OneRec-Think is shown in Fig. 2.
4.1 Itemic Alignment through Multi-Task Pre-training
To align recommender knowledge with the LLM’s linguistic space, we design a Multi-Task Pre-training strategy enabling seamless processing of natural language and itemic tokens via four complementary tasks under Next Token Prediction.
Interleaved User Persona Grounding
Unlike prior work that uses either pure textual data or isolated item sequences, this task interleaves the itemic tokens and text tokens of User Persona. It includes serialized static attributes, active search behaviors, interactive sequences, and summarized user interests. This composition creates rich, dual-modality training instances where itemic tokens are grounded in their semantic context.
Sequential Preference Modeling
As the core recommendation task, this task constructs data that teaches the model to predict subsequent item interactions from chronological user histories.
Itemic Dense Captioning
This task requires the model to decode an item’s descriptive content from its itemic tokens. By learning to generate detailed textual descriptions, the model establishes a fundamental understanding of the semantic characteristics represented by item combinations.
General Language Modeling
This task continues pre-training the model on general text corpora, preserving the model’s fundamental language capabilities during applying the model to recommendation scenarios.
To enable effective knowledge integration while preserving the linguistic capabilities of the model, we implement a two-substage training strategy to ensure stable alignment. The Token Warm-up substage exclusively trains itemic token embeddings on the Interleaved User Persona Grounding task while keeping the base LLM frozen. The subsequent Multi-Task Integration substage jointly optimizes all parameters on the combined task using a designed ratio (see Appendix A.3 for details).
4.2 Reasoning Activation
Despite robust itemic alignment, direct application to industrial recommendation scenarios often fails to yield effective CoT reasoning due to the noisy and lengthy nature of real-world user behavior sequences. To address this, we propose a supervised fine-tuning framework that first extracts coherent reasoning trajectories from pruned user contexts, then leverages these trajectories to guide rationale generation over raw behavioral data, enabling effective contextual distillation for noisy industrial settings (as shown in Fig. 2(b)).
Bootstrapping with Pruned Contexts: To bootstrap reasoning capabilities, we first construct easy-to-learn instances where logical relationships are preserved despite sequence pruning. For each user, we select the target item and form a context-target pair . We then retrieve the top- most relevant historical items using a similarity function :
Using these relevant items, we query our pre-aligned model to generate a rationale explaining the target interaction:
where means constructs a prompt to query the rationale why a user who interacts with item sequence would interact with item . This process yields high-quality rationales that are both logically sound and target-aligned, providing ideal training signals for reasoning induction.
Learning to Reason from Noisy Sequences: The distilled rationales serve as supervision for learning to reason from raw sequences. The training objective minimizes the negative log-likelihood of generating both the rationale and target item:
where represents the rationale tokens and denotes the target item tokens. By optimizing , the model learns to internally distill relevant context from noisy sequences and generate coherent rationales that bridge user history to target interactions, significantly enhancing its CoT capabilities in challenging recommendation scenarios.
4.3 Reasoning Enhancement
Building upon the CoT capabilities from Reasoning Activation, we address the challenge of ensuring consistently high-quality reasoning through Reinforcement Learning. This stage refines the recommendation accuracy using a novel reward mechanism tailored for generative recommendation.
Beam Candidate Reward Maximization: Standard verifiable pass rewards face significant sparsity challenges in recommendation scenarios, as most reasoning rollouts fail to hit the target item and consequently yield identical zero rewards—thereby neutralizing group advantages in algorithms such as GRPO 22. To overcome this, we introduce the Rollout-Beam reward that evaluates reasoning capability by the model’s best achievable performance within a constrained beam. Our approach employs beam search with width to explore multiple generation candidates after reasoning trajectory generation:
where the beam search result set is defined as:
which contains the items with the top- probabilty in the beam search within the distribution . is a valid prompt of history sequence. means the top- result of beam search within distribution . Subsequently, we optimize the model using GRPO 22 based on , which effectively leverages the enriched reward signals from the multi-validity nature of user preferences.
Overall, this design establishes training-inference consistency by aligning reward computation with beam search-based inference, providing denser learning signals through multi-path evaluation.
Table 1: Overall performance comparison between the baselines and OneRec-Think on three datasets. The bold results highlight the best results, while the second-best ones are underlined.
| Dataset | Method | BERT4Rec | HGN | GRU4Rec | SASRec | TIGER | HSTU | ReaRec | OneRec-Think |
|---|---|---|---|---|---|---|---|---|---|
| Beauty | R@5 | 0.0232 | 0.0319 | 0.0395 | 0.0402 | 0.0405 | 0.0424 | 0.0450 | 0.0563 |
| R@10 | 0.0396 | 0.0536 | 0.0584 | 0.0607 | 0.0623 | 0.0652 | 0.0704 | 0.0791 | |
| N@5 | 0.0146 | 0.0196 | 0.0265 | 0.0254 | 0.0267 | 0.0280 | 0.0262 | 0.0398 | |
| N@10 | 0.0199 | 0.0266 | 0.0326 | 0.0320 | 0.0337 | 0.0353 | 0.0344 | 0.0471 | |
| Sports | R@5 | 0.0102 | 0.0183 | 0.0190 | 0.0199 | 0.0215 | 0.0268 | 0.0214 | 0.0288 |
| R@10 | 0.0175 | 0.0313 | 0.0312 | 0.0301 | 0.0347 | 0.0343 | 0.0332 | 0.0412 | |
| N@5 | 0.0065 | 0.0109 | 0.0122 | 0.0106 | 0.0137 | 0.0173 | 0.0116 | 0.0199 | |
| N@10 | 0.0088 | 0.0150 | 0.0161 | 0.0141 | 0.0179 | 0.0226 | 0.0154 | 0.0239 | |
| Toys | R@5 | 0.0215 | 0.0326 | 0.0330 | 0.0448 | 0.0337 | 0.0366 | 0.0523 | 0.0579 |
| R@10 | 0.0332 | 0.0517 | 0.0490 | 0.0626 | 0.0547 | 0.0566 | 0.0764 | 0.0797 | |
| N@5 | 0.0131 | 0.0192 | 0.0228 | 0.0300 | 0.0209 | 0.0245 | 0.0298 | 0.0412 | |
| N@10 | 0.0168 | 0.0254 | 0.0279 | 0.0358 | 0.0276 | 0.0309 | 0.0376 | 0.0482 |
4.4 Industrial Deployment: A “Think-Ahead” Architecture
The deployment of OneRec-Think in industrial recommendation systems presents a fundamental challenge: reconciling the computational demands of multi-step reasoning with the stringent latency requirements of real-time user interactions.
To address this critical bottleneck, we introduce a novel Think-Ahead Inference Architecture. Our solution strategically decouples the model’s inference into two stages: In the first stage, the computationally intensive reasoning path and the initial item-tokens (e.g., the first two itemic tokens) are generated offline by the full OneRec-Think model. These initial tokens are designed to capture the user’s broad intent or general preference context. Subsequently, the second stage then employs a real-time updated OneRec model following 7 for online finalization. It utilizes the pre-generated item-tokens as a constrained prefix to rapidly produce the final itemic token. This design ensures real-time responsiveness and achieves production-grade performance by leveraging current contextual data. The details of this architecture are in Appendix A.3.4.
5 Experiments

Figure 3: Demonstration of context-aware recommendation adaptation: our model dynamically shifts recommendations to relaxing content based on the user’s command.

Figure 4: Demonstration of fine-grained interest reasoning, which shows the end-to-end process from user behavior analysis to interpretable recommendations.
5.1 Experimental Settings
Datasets and Baselines.
We use three real-world recommendation datasets from the popular Amazon review benchmark 1: Beauty, Toys, and Sports. We compare OneRec-Think against two groups of competitive baselines: (1) Classic sequential methods like BERT4Rec 32, HGN 33, GRU4Rec 34, and SASRec 35; and (2) Generative Recommender Models, such as TIGER 12, HSTU 25, and ReaRec 31. Top-K Recall (R@K) and NDCG (N@K) with K=5 and 10 are used as metrics, following 12. Implementation 2 details are in Appendix A.1.
5.2 Overall Performance
The results are shown in Table 1. We could observe that models leveraging powerful reasoning-based architectures (ReaRec and our OneRec-Think) consistently outperform both traditional sequential recommenders and generative recommenders. This robust trend confirms that effective sequential prediction necessitates robust inference and contextual reasoning capabilities. Furthermore, OneRec-Think further gets the best performance across all benchmarks. This significant superiority is directly attributed to explicit, text-based reasoning ability for item generation, in contrast to the more implicit, purely learned generation mechanisms in prior works.
5.3 Ablation Study
Table 2: Ablation Study of different variants of OneRec-Think on Beauty dataset.
| Training Method | R@5 | R@10 | N@5 | N@10 |
|---|---|---|---|---|
| Base | 0.0460 | 0.0654 | 0.0314 | 0.0377 |
| Base+IA | 0.0532 | 0.0735 | 0.0342 | 0.0402 |
| Base+IA+R | 0.0563 | 0.0791 | 0.0398 | 0.0471 |
We conduct an ablation study on the Beauty dataset, comparing three configurations: the Base model tuned by the raw itemic token sequence, the Base+IA model enhanced with Itemic Alignment, and the full Base+IA+R model incorporating our enhanced reasoning mechanism, as shown in Table 2. It demonstrates that each component is indispensable: Itemic Alignment provides a foundational boost by creating coherent semantic representations of itemic tokens, while the reasoning mechanism yields a further significant gain, confirming that both components synergistically address core challenges in sequential recommendation.
5.4 Industrial Experiments
5.4.1 Training Settings
We adopt Qwen-8B 36 as our backbone model, initializing its parameters from the publicly available pre-trained weights. The model’s vocabulary is extended with 24,576 new tokens representing the three-level hierarchical itemic tokens (8,192 tokens per level), plus two special boundary tokens, <|item_begin|> and <|item_end|>. For our production environment, we implement a daily incremental training pipeline. The model is updated each day on a cluster of 80 flagship GPUs, processing approximately 20B tokens per day to stay current with newly generated user interaction data. The details are shown in Appendix A.3.
Table 3: The relative improvement of our online A/B testing on a short-video recommendation scenario.
| Online Metrics | OneRec-Think |
|---|---|
| App Stay Time | +0.159% |
| Watch Time | +0.169% |
| Video View | +0.150% |
| Follow | +0.431% |
| Forward | +0.758% |
| Like | +0.019% |
| Collect | +0.098% |
5.4.2 Results
Online A/B Result.
We deploy OneRec-Think on Kuaishou, a short-video platform with hundreds of millions of daily active users. Using a 1.29% traffic experimental group, we compare OneRec-Think with our online model for one week and report the result in Table 3, where the primary metric is APP Stay Time (reflecting total user engagement time). The primary metric, App Stay Time, shows significant gains that increase by 0.159%. Note that in industrial recommendation systems, 0.1% improvements are considered substantial. Furthermore, interactive metrics such as Video View and Forward exhibit positive trends, indicating enhanced user engagement. We conducted multiple experiments at different times and consistently observed significant improvements in stay time and related interaction metrics.
Table 4: The Bertscore for User Understanding and Short Video Understanding Benchmark.
| Benchmark | Qwen3 | Qwen3 | Qwen3 |
|---|---|---|---|
| + TW | + TW + MI | ||
| User | 0.6588 | 0.6492 | 0.7053 |
| Short Video | 0.6031 | 0.6443 | 0.7300 |

Figure 5: The model’s reasoning process evolves from broad interest matching (left) to fine-grained theme specification (middle), with recommendations (right) showing semantic consistency with each reasoning step.
Ablation on Itemic Alignment on industrial benchmark
We evaluate Token Warm-up (TW) and Multi-Task Integration (MI) of the Itemic Alignment stage on our industrial User and Short Video Understanding benchmarks using BertScore 37 (details in Appendix A.3.2). Results in Table 4 reveal distinct roles for each component. On the text-heavy User Understanding task, TW provides limited gain over the strong Base model since the LLM can effectively process the abundant textual information directly, while MI delivers a substantial boost by translating aligned representations into actionable insights. In contrast, in the pure itemic token Short Video Understanding task, it shows progressive gains from both TW and MI, confirming their necessity for interpreting non-textual item information. These results validate that these two substages both contribute to the final performance of Itemic Alignment.

Figure 6: Demonstration of itemic-textual interleaved reasoning.
5.5 Case Study
Our case studies demonstrate the model’s sophisticated reasoning capabilities across different scenarios. In conversational settings (Fig. 3), when the user expresses negative emotions, the model detects this affective signal and strategically shifts recommendations from general interests toward relaxing and positive content, demonstrating its ability to actively optimize the viewing experience through the interaction with the user. In reasoning-based short-video recommendation (Fig. 4), the model generates diverse reasoning paths that capture fine-grained user preferences, such as specific gameplay mechanics and narrative patterns, enabling more precise recommendations beyond coarse topic matching. Furthermore, our consistency analysis (Fig. 5) reveals strong alignment between reasoning textx and recommended items when applying beam search at intermediate reasoning steps, confirming that the reasoning process genuinely guides recommendation generation rather than serving as post-hoc justification. Notably, our model achieves itemic-textual interleaved reasoning paths (Fig. 6). Through precise content anchoring by itemic tokens and causal articulation by textual tokens, the interleaved reasoning delivers enhanced recommendation accuracy and transparent explanations beyond isolated modality approaches. These results collectively validate our model’s capacity for authentic, multi-faceted reasoning by demonstrating its ability to adapt to real-time interactions, capture fine-grained preferences, and maintain semantic consistency across diverse recommendation scenarios.
6 Conclusion
We present OneRec-Think, a novel framework that bridges reasoning capabilities with generative recommendation through three key innovations: hierarchical itemic token alignment, reasoning activation via CoT supervised fine-tuning, and reinforcement-based reasoning refinement. Our method fundamentally transforms recommendation systems from mere item predictors into reasoning-aware models that generate interpretable rationales alongside high-quality recommendations. Extensive experiments demonstrate that OneRec-Think not only achieves state-of-the-art performance across multiple benchmarks, but also translates to concrete industrial impact with a 0.15% gain in primary metrics like APP Stay Time. Future work will focus on exploring user long-sequence modeling and dense RL reward for finer-grained preference modeling, further bridging LLM-based reasoning with industrial recommendation systems.
Limitations
Despite promising empirical results, current public datasets exhibit quality constraints through their limited behavior sequence lengths and restricted item spaces. These limitations hinder our Reasoning Activation and Reasoning Enhancement modules from acquiring high-quality reasoning capabilities comparable to those learned from industrial-scale data. Consequently, we simplify and adapt our approach to achieve a stable yet simplified reasoning capacity, which remains robust within the public datasets. To address these issues, we are actively constructing a large-scale benchmark with extended behavioral trajectories and diversified item catalogs that will enable more comprehensive evaluation of reasoning capabilities for reasoning-based recommendation models.
Ethics Statement
In this work, we have conducted experiments for two settings: one for open-source benchmark datasets and one for the industrial scenario. For the experiments for open-source benchmark datasets, all datasets are publicly available from previous works or public APIs while maintaining anonymity. For the industrial scenario, we utilize user interaction data collected from our platform to train the recommendation model. All data collection and usage strictly comply with our platform’s privacy policy and terms of service, to which users have provided explicit consent. Importantly, our training process operates solely on aggregated behavioral sequences, textual content, and user base information without accessing or processing any personally identifiable information.
References
Appendix A Appendix
A.1 Experiment settings
Details of Baselines
We compare OneRec-Think with competitive baselines within two groups of work, traditional recommender models and generative recommender models: 1) BERT4Rec 32 leverages BERT’s pre-trained language representations to capture semantic user-item relationships. 2) HGN 33 utilizes graph neural networks to learn user and item representations for predicting user-item interactions. 3) GRU4Rec 34 is a lightweight graph convolutional network model focusing on high-order connections between users and items. 4) SASRec 35 employs self-attention mechanisms to capture long-term dependencies in user interaction history. 5) TIGER 12 introduces codebook-based identifiers via RQ-VAE, which quantizes semantic information into code sequences for LLM-based generative recommendation. 6) HSTU 25 reformulates recommendation problems as sequential transduction tasks within a generative modeling framework and proposes a new architecture for streaming data. 7) ReaRec 31 enhances user representations through implicit multi-step reasoning within an inference-time computing framework for recommendation. Evaluation Metrics. We use two metrics: top- Recall (R@ ) and NDCG (N@ ) with = 5 and 10, following 12.

Figure 7: A reasoning example for a short-video recommendation scenario.
Details of experiments on open-source datasets
We adopt Qwen3-1.7B 36 as our backbone model. The model’s vocabulary is extended with 1,024 new tokens representing the four-level hierarchical semantic IDs (256 tokens per level), in addition to two special boundary tokens, <|item_begin|> and <|item_end|>. All models were trained on a server equipped with flagship GPUs. To generate the top-K recommendations during evaluation, we employ a beam search strategy with a beam width of 10. Given the inherent challenge of deriving a robust reasoning path from the short and sparse item sequences typical of public benchmarks, we strategically employ manually constructed category-based CoT as the pruned content for Reasoning Activation to ensure stable semantic guidance. For the training data, we adopt the pre-processing techniques from previous work 12 38, discarding sparse users and items with interactions less than 5. We consider the sequential recommendation setting and use leave-one-out strategy 12 13 to split datasets. For training, we follow 35 to restrict the number of items in a user’s history to 50.
A.2 Model Demonstration
Reasoning Cases for Short-video Recommendation
In this part, we show some cases of short video recommendations of another user. Figure 7 presents two reasoning paths generated by our model, demonstrating its capacity for multi-step interest inference and underlying need identification. In the first case, the model connects the user’s gaming preferences with hardware comparison behaviors to deduce an unstated need for performance optimization, ultimately recommending monitor analysis videos. The second case reveals deeper psychological needs by associating sports/military viewing history with adolescent rebellion searches, identifying parenting challenges as the core concern. Both examples showcase our model’s ability to transcend superficial topic matching and perform causal reasoning about user motivations, enabling recommendations that address both expressed interests and latent needs.
Semantic Comprehension Validation
After semantic alignment, the model acquires the capability to comprehend and articulate the semantic meaning of item tokens through natural language. To validate this emergent ability, we evaluate the capacity of the model to generate descriptive captions for itemic tokens without explicit training on this task. When prompted to explain what an itemic token represents, the model leverages the learned semantic correspondences to produce coherent textual descriptions that accurately capture the characteristics of the items. This demonstrates that the alignment process successfully establishes genuine semantic understanding rather than superficial pattern matching, as the model can now bidirectionally translate between discrete itemic tokens and their rich natural language semantics. The following cases in Beauty datset showcase the model’s caption generation capability for item semantic tokens:
A.3 Implementation Details
A.3.1 Itemic Alignment
Task details
Here, we first introduce the aforementioned four types of tasks.
1. Interleaved User Persona Grounding. This part contains the interleaved itemic tokens with rich, natural-language text extracted from static user profiles. This process forces the model to create a robust mapping between the itemic tokens and their real-world meanings, grounded in user attributes, stated interests, and historical behaviors. The sample data is shown below.
Footnotes
-
Qiyao Peng, Hongtao Liu, Hua Huang, Qing Yang, and Minglai Shao. 2025. A survey on llm-powered agents for recommender systems. arXiv preprint arXiv:2502.10050. ↩
-
Yu Zhang, Shutong Qiao, Jiaqi Zhang, Tzu-Heng Lin, Chen Gao, and Yong Li. 2025b. A survey of large language model empowered agents for recommendation and search: Towards next-generation information retrieval. arXiv preprint arXiv:2503.05659. ↩
-
Yashar Deldjoo, Zhankui He, Julian McAuley, Anton Korikov, Scott Sanner, Arnau Ramisa, René Vidal, Maheswaran Sathiamoorthy, Atoosa Kasirzadeh, and Silvia Milano. 2024. A review of modern recommender systems using generative models (gen-recsys). In Proceedings of the 30th ACM SIGKDD conference on Knowledge Discovery and Data Mining, pages 6448–6458. ↩
-
Lei Li, Yongfeng Zhang, Dugang Liu, and Li Chen. 2023. Large language models for generative recommendation: A survey and visionary discussions. arXiv preprint arXiv:2309.01157. ↩
-
Wenjie Wang, Xinyu Lin, Fuli Feng, Xiangnan He, and Tat-Seng Chua. 2023. Generative recommendation: Towards next-generation recommender paradigm. arXiv preprint arXiv:2304.03516. ↩
-
Jiaxin Deng, Shiyao Wang, Kuo Cai, Lejian Ren, Qigen Hu, Weifeng Ding, Qiang Luo, and Guorui Zhou. 2025. Onerec: Unifying retrieve and rank with generative recommender and iterative preference alignment. arXiv preprint arXiv:2502.18965. ↩
-
Guorui Zhou, Jiaxin Deng, Jinghao Zhang, Kuo Cai, Lejian Ren, Qiang Luo, Qianqian Wang, Qigen Hu, Rui Huang, Shiyao Wang, and 1 others. 2025a. Onerec technical report. arXiv preprint arXiv:2506.13695. ↩ ↩2 ↩3 ↩4 ↩5
-
Guorui Zhou, Hengrui Hu, Hongtao Cheng, Huanjie Wang, Jiaxin Deng, Jinghao Zhang, Kuo Cai, Lejian Ren, Lu Ren, Liao Yu, and 1 others. 2025b. Onerec-v2 technical report. arXiv preprint arXiv:2508.20900. ↩ ↩2
-
Zhipeng Wei, Kuo Cai, Junda She, Jie Chen, Minghao Chen, Yang Zeng, Qiang Luo, Wencong Zeng, Ruiming Tang, Kun Gai, and 1 others. 2025. Oneloc: Geo-aware generative recommender systems for local life service. arXiv preprint arXiv:2508.14646. ↩
-
Xian Guo, Ben Chen, Siyuan Wang, Ying Yang, Chenyi Lei, Yuqing Ding, and Han Li. 2025b. Onesug: The unified end-to-end generative framework for e-commerce query suggestion. arXiv preprint arXiv:2506.06913. ↩
-
Ben Chen, Xian Guo, Siyuan Wang, Zihan Liang, Yue Lv, Yufei Ma, Xinlong Xiao, Bowen Xue, Xuxin Zhang, Ying Yang, and 1 others. 2025. Onesearch: A preliminary exploration of the unified end-to-end generative framework for e-commerce search. arXiv preprint arXiv:2509.03236. ↩
-
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Tran, Jonah Samost, and 1 others. 2023. Recommender systems with generative retrieval. Advances in Neural Information Processing Systems, 36:10299–10315. ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8 ↩9 ↩10
-
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, and Ji-Rong Wen. 2024. Adapting large language models by integrating collaborative semantics for recommendation. In ICDE. IEEE. ↩ ↩2 ↩3
-
Yidan Wang, Zhaochun Ren, Weiwei Sun, Jiyuan Yang, Zhixiang Liang, Xin Chen, Ruobing Xie, Su Yan, Xu Zhang, Pengjie Ren, and 1 others. 2024b. Content-based collaborative generation for recommender systems. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, pages 2420–2430. ↩
-
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, and 1 others. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837. ↩
-
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners. Advances in neural information processing systems, 35:22199–22213. ↩
-
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171. ↩
-
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of thoughts: Deliberate problem solving with large language models, 2023. URL https://arxiv. org/abs/2305.10601, 3:1. ↩
-
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. 2024. Scaling llm test-time compute optimally can be more effective than scaling model parameters. arXiv preprint arXiv:2408.03314. ↩
-
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, and 1 others. 2025a. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948. ↩
-
ByteDance Seed, Jiaze Chen, Tiantian Fan, Xin Liu, Lingjun Liu, Zhiqi Lin, Mingxuan Wang, Chengyi Wang, Xiangpeng Wei, Wenyuan Xu, and 1 others. 2025. Seed1. 5-thinking: Advancing superb reasoning models with reinforcement learning. arXiv preprint arXiv:2504.13914. ↩
-
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, and 1 others. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300. ↩ ↩2 ↩3
-
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, and 1 others. 2025. Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476. ↩
-
Yu Yue, Yufeng Yuan, Qiying Yu, Xiaochen Zuo, Ruofei Zhu, Wenyuan Xu, Jiaze Chen, Chengyi Wang, TianTian Fan, Zhengyin Du, and 1 others. 2025. Vapo: Efficient and reliable reinforcement learning for advanced reasoning tasks. arXiv preprint arXiv:2504.05118. ↩
-
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhaojie Gong, Fangda Gu, Michael He, and 1 others. 2024. Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations. arXiv preprint arXiv:2402.17152. ↩ ↩2 ↩3
-
Alicia Tsai, Adam Kraft, Long Jin, Chenwei Cai, Anahita Hosseini, Taibai Xu, Zemin Zhang, Lichan Hong, Ed H. Chi, and Xinyang Yi. 2024. Leveraging LLM reasoning enhances personalized recommender systems. In Findings of the Association for Computational Linguistics: ACL 2024, pages 13176–13188, Bangkok, Thailand. Association for Computational Linguistics. ↩
-
Millennium Bismay, Xiangjue Dong, and James Caverlee. 2024. Reasoningrec: Bridging personalized recommendations and human-interpretable explanations through llm reasoning. arXiv preprint arXiv:2410.23180. ↩
-
Yi Fang, Wenjie Wang, Yang Zhang, Fengbin Zhu, Qifan Wang, Fuli Feng, and Xiangnan He. 2025. Reason4rec: Large language models for recommendation with deliberative user preference alignment. CoRR. ↩
-
Jieyong Kim, Hyunseo Kim, Hyunjin Cho, SeongKu Kang, Buru Chang, Jinyoung Yeo, and Dongha Lee. Review-driven personalized preference reasoning with large language models for recommendation. corr, abs/2408.06276, 2024. doi: 10.48550. arXiv preprint ARXIV.2408.06276. ↩
-
Junjie Zhang, Beichen Zhang, Wenqi Sun, Hongyu Lu, Wayne Xin Zhao, Yu Chen, and Ji-Rong Wen. 2025a. Slow thinking for sequential recommendation. arXiv preprint arXiv:2504.09627. ↩
-
Jiakai Tang, Sunhao Dai, Teng Shi, Jun Xu, Xu Chen, Wen Chen, Jian Wu, and Yuning Jiang. 2025. Think before recommend: Unleashing the latent reasoning power for sequential recommendation. arXiv preprint arXiv:2503.22675. ↩ ↩2 ↩3
-
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang. 2019. Bert4rec: Sequential recommendation with bidirectional encoder representations from transformer. In CIKM, pages 1441–1450. ACM. ↩ ↩2
-
Chen Ma, Peng Kang, and Xue Liu. 2019. Hierarchical gating networks for sequential recommendation. In KDD. ACM. ↩ ↩2
-
Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk. 2016. Session-based recommendations with recurrent neural networks. In ICLR. ICLR. ↩ ↩2
-
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recommendation. In ICDM, pages 197–206. IEEE. ↩ ↩2 ↩3
-
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, and 1 others. 2025. Qwen3 technical report. arXiv preprint arXiv:2505.09388. ↩ ↩2
-
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi. 2019. Bertscore: Evaluating text generation with bert. arXiv preprint arXiv:1904.09675. ↩
-
Wenjie Wang, Honghui Bao, Xinyu Lin, Jizhi Zhang, Yongqi Li, Fuli Feng, See-Kiong Ng, and Tat-Seng Chua. 2024a. Learnable item tokenization for generative recommendation. In CIKM. ACM. ↩