Qi Li Yanzhe Zhao Yongxin Zhou Yameng Wang Yandong Yang
Yuanjia Zhou Jue Wang Zuojian Wang Jinxiang Liu
Honor Device Co., Ltd Corresponding author.
Abstract
Multimodal Large Language Models (MLLMs) have shown immense promise in universal multimodal retrieval, which aims to find relevant items of various modalities for a given query. But their practical application is often hindered by the substantial computational cost incurred from processing a large number of tokens from visual inputs. In this paper, we propose Magic-MM-Embedding, a series of novel models that achieve both high efficiency and state-of-the-art performance in universal multimodal embedding. Our approach is built on two synergistic pillars: (1) a highly efficient MLLM architecture incorporating visual token compression to drastically reduce inference latency and memory footprint, and (2) a multi-stage progressive training strategy designed to not only recover but significantly boost performance. This coarse-to-fine training paradigm begins with extensive continue pretraining to restore multimodal understanding and generation capabilities, progresses to large-scale contrastive pretraining and hard negative mining to enhance discriminative power, and culminates in a task-aware fine-tuning stage guided by an MLLM-as-a-Judge for precise data curation. Comprehensive experiments show that our model outperforms existing methods by a large margin while being more inference-efficient.
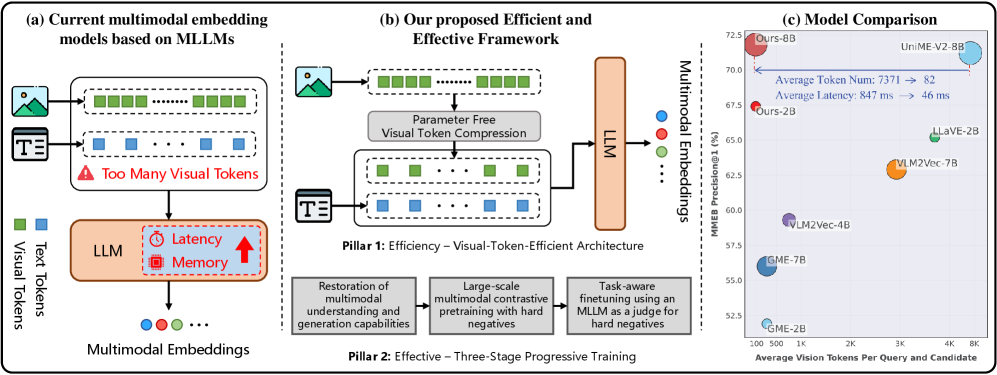
Figure 1: Breaking the efficiency-performance trade-off for MLLM embedders for universal multimodal retrieval. (a) Standard MLLM-based embedders suffer from high computational costs due to processing redundant, dense visual token sequences. (b) We propose a visual token compression model paired with a robust three-stage progressive training strategy. (c) Comparisons on MMEB 35 demonstrate that our approach establishes a new state-of-the-art using much less visual tokens with reduced inference latency.
1 Introduction
Multimodal embedding models are designed to project heterogeneous data modalities, such as text, images, and interleaved image-text data, into a unified semantic space. These models are widely applied across various domains, such as multimodal search 1 2 3 4, recommendation systems 5 6, and retrieval-augmented generation 7 8 9. Recently, the field has recently witnessed a significant paradigm shift, moving beyond the dual-tower architectures such as CLIP 10 and UniIR 1, towards Multimodal Large Language Models (MLLMs) 11 12 with stronger multimodal understanding capabilities.
This transition is driven by the intrinsic limitations of dual-tower frameworks: (1) modal-independent encoding architecture with feature post-fusion, which lacks deep cross-modal interaction, limits their ability to perform fine-grained multimodal reasoning 13 14 15. (2) limited language understanding ability, where rigid context constraints and limited prior knowledge restrict the understanding of complex semantics 16 17 18. In contrast, MLLM-based methods treat visual features as discrete tokens, processed jointly with text in a unified transformer. This facilitates deep token-level cross-modal fusion, rather than shallow global alignment. Leveraging this design, along with the extensive world knowledge and robust instruction-following capabilities of LLMs, these models can perform complex multimodal retrieval in diverse scenarios.
Building upon these advantages, recent research has rapidly advanced MLLM-based universal multimodal embedding approaches through enhancement of data scale and quality 19 20 21 22, gradient amplification on hard negatives 23 24 21, refinement of hard negative mining strategies 25 15 26 21 22, expert knowledge distillation 15 27, multi-stage progressive training 28 15 21 22, incorporation of thinking and reinforcement learning 29 30 31, and coordination with reranker during inference 28 27 22.
However, these advancements overlook a critical bottleneck: the prohibitive cost of long visual token sequences. Standard MLLM architectures typically adopt a full-sequence integration strategy, where the dense stream of patch tokens output by the Vision Transformer 32 is fed in its entirety into the LLM backbone. For instance, the widely-used LLaVA-1.5 33 partitions a standard image into 576 visual tokens, all of which are directly injected into the language model. While this full-sequence injection benefits fine-grained generation tasks like OCR, it introduces massive redundancy for retrieval, where the goal is to distill multimodal information from these redundant visual tokens together with textual tokens into a single [EOS] token. This creates a significant imbalance: the computational cost of processing these redundant visual tokens scales quadratically with their sequence length, while their contribution to the semantic quality of the final embeddings is often marginal. Consequently, this inefficiency acts as a primary barrier to deploying MLLM-based embedders in large-scale, latency-critical retrieval systems.
To address this challenge of computational inefficiency while delivering high performance, we propose a novel framework that synergistically combines architectural efficiency with a curated training strategy. Architecturally, we adopt a parameter-free spatial interpolation module which projects the long visual sequence into a compressed form, reducing the token overhead by 75% while avoiding the optimization difficulties of learnable abstractors 34 35. To mitigate any potential performance degradation from aggressive compression and learn robust discriminative representations, we pair this efficient architecture with a three-stage training pipeline: (1) Multimodal Foundational Capability Restoration. We begin with generative continue training on general multimodal instruction datasets. This stage re-aligns the compressed visual features with the LLM, ensuring the preservation of foundational multimodal understanding and generation abilities. (2) Multimodal Contrastive Pretraining. We construct a general embedder using 16M multimodal samples with contrastive training. This stage aims to cultivate robust general representation capabilities by evolving from a contrastive warm-up to a self-refinement phase with retrieval-based hard negative mining. (3) Task-aware Finetuning. We refine the model on a curated, high-quality multi-task dataset through a retrieve-and-curate strategy. Using the previous stage’s model, we retrieve candidates for each query of the training set and leverage an MLLM as a Judge to construct high-quality hard negatives. These curated samples then drive the final stage of contrastive learning, yielding the final embedding model to handle diverse and complex scenarios. Through extensive experiments, our approach establishes a new state-of-the-art on various natural image 13 and visual document 36 retrieval tasks. Crucially, this superior performance is achieved with remarkable token efficiency, with only a quarter of the visual tokens, validating the power of our co-designed compression and training strategy. Our main contributions are as follows:
- We propose a novel framework that successfully reconciles efficiency and performance for MLLM-based universal embedding. We demonstrate that a model with aggressive visual token compression can significantly outperform its non-compressed counterparts when supported by a dedicated, advanced training pipeline.
- We introduce a coarse-to-fine training strategy specifically designed for compressed MLLMs. This pipeline provides a systematic and effective methodology for restoring foundational abilities, building robust discriminative power, and achieving strong multi-task generalization with curated data from MLLM-as-a-Judge.
- Through extensive experiments, we demonstrate that our proposed model establishes new state-of-the-art results, validating the superiority of our holistic approach in creating a model that is both computationally efficient and highly effective.
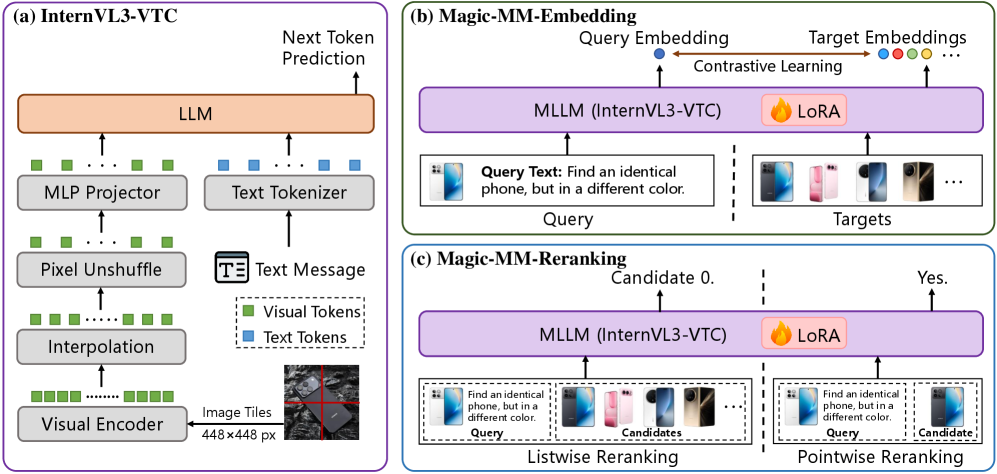
Figure 2: Overview of the proposed visual-token-efficient architecture for universal multimodal retrieval. (a) The proposed MLLM architecture with Visual Token Compression, InternVL3-VTC. (b, c) The proposed inference-efficient, universal multimodal embedder and reranker, both of which are built upon InternVL3-VTC.
2 Related Work
Multimodal representation learning was first popularized by the CLIP-style models 10 37 38 39 40 34 41 42 16. These models adopt an image–text dual encoder architecture and therefore only support bidirectional text–image retrieval. Building on this, methods such as UniIR 1 and MagicLens 2 fuse features from the two towers, extending the model input from a single modality to interleaved image–text content. However, these methods essentially follow a late fusion paradigm: they first encode each modality independently and then fuse the representations, which limits their ability to capture fine grained cross modal relationships 13 14 15. In addition, these models use BERT-style 43 text encoders, which lack sufficient real-world knowledge and have strict input length limitations, leading to suboptimal results in complex text understanding 16 17 18.
Compared to CLIP-style backbones, MLLMs 11 44 12 natively support interleaved text and image inputs and exhibit stronger multimodal understanding and instruction following capabilities. Benefiting from the rapid progress of MLLMs, multimodal embedding paradigms based on MLLMs have quickly emerged. E5-V 14 trains the language component of MLLMs in a text to text fashion, enabling zero shot multimodal retrieval. However, due to the lack of training on large scale multimodal contrastive data, its ability to handle complex multimodal retrieval tasks remains limited. VLM2Vec 13 introduces MMEB, the first comprehensive multi-task multimodal embedding training and evaluation benchmark. VLM2Vec brings MLLMs into a contrastive learning framework, leveraging their instruction-following and multimodal reasoning capabilities. By training on the MMEB training set, it achieves strong multi-task generalization across a wide range of retrieval tasks. To further improve discriminative capability, subsequent work systematically conducted extensive optimizations, including improving data scale and quality 19 20 21 22, amplifying gradients on hard negatives 23 24 21, refining hard negative mining strategies 25 15 26 21 22, distilling expert knowledge 15 27, adopting multi-stage progressive training 28 15 21 22, introducing thinking and reinforcement learning 29 30 31, and coordinating with reranker during inference 28 27 22. With these community efforts, the discriminative power of MLLM based multimodal embedding models has been significantly improved. However, because these models directly adopt the general-purpose MLLMs architecture, the issues of high inference cost 45 46 47 caused by visual token redundancy have not yet received attention or solutions.
3 Methodology
Our objective is to develop a highly efficient and effective MLLM-based universal multimodal embedding model for retrieval. The overview of the proposed architecture is shown in Figure˜2. We begin by formally defining the universal multimodal retrieval task before detailing our proposed framework, including our architectural modifications and progressive training pipeline.
3.1 Preliminaries
We formulate the learning of universal multimodal embedding as a unified mapping function within a shared semantic space. Let represent the multimodal input space. Each input , which serves as either a query or a candidate , is composed of task instructions, visual context, and textual context. The corresponding input templates for queries and candidates are as follows, and the task instructions for different datasets are shown in Tables˜11 and 12.
![[Uncaptioned image]](https://arxiv.org/html/2602.05275v1/x3.png)
[Uncaptioned image]
To obtain multimodal embeddings, we employ an MLLM with visual token compression as the encoder to map an input to a sequence of hidden states , where each hidden state . We apply normalization to the hidden representation of the last token, , to obtain the final embedding :
To learn a discriminative embedding space, we employ the InfoNCE loss 48 for model training. For a given query , we define a candidate set for loss calculation, where denotes the ground-truth positive target associated with , and is the set of negatives. Each represents a negative sample obtained via in-batch sampling or hard negative mining. The model is trained to maximize the semantic alignment between query and the positive target while suppressing the negatives, by minimizing the following objective:
where is the temperature, and denotes the dot product similarity.
3.2 Parameter-free Visual Token Compression
Standard MLLM Paradigm. Let denote the space of input images. Standard MLLMs typically rely on a visual encoder, , to extract features from an input image . This encoder produces a spatial feature map , where represents the spatial grid size and is the channel dimension. In conventional approaches, is flattened into a sequence of tokens and projected into the LLM input space via a connector. However, the long visual token sequence introduces a significant computational bottleneck due to the quadratic complexity of the LLM attention mechanism.
Visual Token Compression via Interpolation. To alleviate this “token overload”, we introduce a parameter-free visual compression module inserted between the visual encoder and the connector. Unlike complex learned compression schemes, we employ a direct bilinear interpolation strategy 12 49 on the spatial dimensions of the feature map. Formally, given the output feature map from the visual encoder, we apply a bilinear downsampling operation to reduce the spatial resolution by a factor of . The compressed feature map is computed as:
where the target spatial dimensions are and .
The compressed map is then flattened into a visual token sequence and fed into the connector for projection. This operation reduces the total number of visual tokens from to while preserving the spatial layout and semantic integrity of the image. By reducing the sequence length quadratically before it enters the LLM, we significantly lower both inference latency and memory consumption without introducing any parameters.
3.3 Progressive Coarse-to-Fine Training Pipeline
While our model architecture significantly improves efficiency with reduced visual tokens, directly training this compressed model with a standard contrastive objective can lead to suboptimal performance due to the sudden shift in feature distribution and potential information loss. To overcome this, we design a “coarse-to-fine” progressive training pipeline comprising three distinct stages: Generative Restoration, Contrastive Pretraining, and Task-Aware Refinement.
Stage 1: Multimodal Foundational Capability Restoration. The introduction of the interpolation module alters the spatial structure and density of visual features that the pretrained LLM backbone expects. Therefore, the primary goal of the first stage is not retrieval, but alignment. To this end, we re-align compressed visual representations with the LLM semantic space. Through generative training on general-purpose multimodal instruction-following datasets, we restore fundamental multimodal understanding and generation capabilities. For the textual response token sequence , the model is optimized using the standard auto-regressive Next Token Prediction (NTP) loss:
where is the ground-truth next token, and denotes the multimodal input consisting of visual and textual context. This step is vital to bridge the distribution gap caused by token compression, ensuring the MLLM retains its reasoning capabilities before transitioning to embedding learning.
Stage 2: Multimodal Contrastive Pretraining. With the multimodal foundational ability restored, we pivot the model towards multimodal representation learning. This stage operates on a large-scale multimodal retrieval corpus and proceeds in two steps to progressively increase difficulty. We first warm-up the model by training with standard InfoNCE loss with in-batch negatives as Equation˜2. Subsequently, to encourage the model to learn fine-grained distinctions, we introduce a Global Hard Negative Mining strategy to inject hard negatives into the training set and conduct a new round of training. Unlike the warm-up phase, which uses random in-batch negatives, for each sub-dataset, we mine informative negatives for every query from all candidates in the entire dataset. Specifically, for each query , we retrieve a ranked list of candidates. We exclude the ground-truth positive from this list and randomly sample 2 hard negatives. These negatives are selected from positions 50–100 in the list, which helps avoid false negatives that are common in top-ranked results (e.g., Top-10), while keeping the negatives more challenging than random batch negatives.
Stage 3: Task-Aware Finetuning with an MLLM as a Judge. The final stage focuses on enhance the model for handle diverse scenarios and complex tasks. Standard training datasets often suffer from “false negatives” and lack sufficiently challenging negatives. To resolve this, we further employ an expert MLLM as a judge to perform data curation and generate high-fidelity hard negatives. Concretely, for each query in the target training set, we perform a “retrieve-and-judge” process. We first utilize our model from stage 2 to retrieve the top- () candidates . We feed each pair , where , into Qwen3-VL 11 with following judgment template to assess their relevance. The judgment instructions used for each dataset are presented in Table˜13.
![[Uncaptioned image]](https://arxiv.org/html/2602.05275v1/x4.png)
[Uncaptioned image]
We then examine the output logits of the ‘yes’ and ‘no’ tokens to determine relevance. If , the candidate is deemed relevant. This helps us discover previously unlabeled true positives, thereby expanding the positive set beyond the original ground-truth positives; If , the candidate is deemed irrelevant. Since these items were retrieved in the Top-20 by our model, they constitute high-quality hard negatives. For constrastive loss calculation, we keep the original ground-truth as the only positive to preserve consistency. The negative sample set is augmented with judge-identified hard negatives, which serve as challenging distractors and force the model to distinguish more confusing samples.
3.4 Synergistic Reranker
To construct a comprehensive retrieval system following previous works 28 27, we train a reranker based on the model from stage 1 to leverage its preserved multimodal understanding and generation capabilities. Thanks to the flexibility of MLLM models, we employ a joint training strategy that combines pointwise and listwise training objectives. Crucially, unlike standard approaches that rely solely on the original dataset labels, our reranker is trained on the judge-curated set from stage 3 of embedding model training. For a given query , we define the augmented positive set as the union of the original ground truth and the judge-identified true positives . Similarly, the negative set consists of the judge-verified hard negatives.
For pointwise reranking formulation, the model evaluates query-candidate pairs independently. We construct training triplets by sampling a positive candidate and a hard negative candidate . We instruct the model, using the following template, to output the token ‘Yes’ for positive pairs and ‘No’ for negative pairs.
![[Uncaptioned image]](https://arxiv.org/html/2602.05275v1/x5.png)
[Uncaptioned image]
The pointwise loss is minimized using standard Cross Entropy (CE) loss:
where represents the autoregressive output process of the reranker.
For listwise reranking training, we construct a candidate list by sampling hard negatives from (where ) and one positive candidate sampled from the augmented set . We randomly insert into the list at position and prompt the model to identify the most relevant candidate. The input template for listwise reranking is as follows:
![[Uncaptioned image]](https://arxiv.org/html/2602.05275v1/x6.png)
[Uncaptioned image]
The model is trained to directly generate the position index of the positive candidate. The listwise loss is formulated as:
The final objective is a weighted sum of both tasks: .
4 Dataset Construction
Stage 1. In this stage, to restore the multimodal understanding and generation abilities of the token compression model, we construct a multimodal instruction-following dataset containing 32M examples. This corpus is composed of both open-source and in-house data, covering a wide range of task types, including multimodal and text-only instruction data, captioning, grounding and classification. A detailed breakdown of the dataset composition is provided in Table˜1. We perform rule-based deduplication and standardize all annotations into a unified format.
Table 1: Details of the training data for restoring multimodal understanding and generation capabilities in stage 1.
| Task | #Samples | Datasets |
| Multimodal Instruction Data | 12.8M | Infinity-MM 21, Bunny-v1.1 25, VLFeedback 48, RLHF-V 93, |
| RLAIF-V 94, DT-VQA 101, LLaVA Visual Instruct 150K 56, | ||
| Monkey 50, LVIS-Instruct4V 83, LRV-Instruction 54 | ||
| Pure Text Instruction Data | 8.8M | Infinity Instruct 45, ShareGPT-Chinese-English-90k 77, |
| firefly-train-1.1M 91, COIG-CQIA 2 | ||
| Captioning | 1.7M | ShareGPT4V 9, In-house |
| Grounding | 5.7M | RefCOCO 36, RefCOCO+ 36, RefCOCOg 66, Objects365 v2 76, |
| Visual Genome 38, gRefCOCO 53, Open Images V6 39, | ||
| V3Det 82, In-house | ||
| Classification | 2.8M | In-house |
Stage 2. In this stage, to adapt the model to multimodal representation learning and strengthen its discriminative power, we construct a multimodal retrieval dataset comprising 16M samples. The dataset consists of the following three categories of data:
- Single-Modal: Includes both Text-to-Text (T T) and Image-to-Image (I I) pairs.
- Cross-Modal: The query or candidate is unimodal, and the query–candidate pair spans different modalities, such as Text-to-Image retrieval (T I) or Text-to-Visual-Document retrieval (T VD).
- Fused-Modal: The query and/or candidate contains both image and text. For example, in the MegaPairs dataset 20, the query is a fusion of an image and a textual instruction, and the target is an image relevant to this mixed image-text query (Image-Text-to-Image, IT I).
The training data are sampled from MegaPairs 20, Colpali train set 3, VisRAG 7, Docmatix 50, BAAI-MTP 51, ImageNet-1K 52, BLIP Bootstrapped Image-Text Pairs 39, MMEB-train 13, and mmE5-synthetic 53. A more detailed composition of the stage 2 training data is presented in Table˜2.
Table 2: Details of the training data for multimodal embedding representation learning in stage 2. ∗ indicates that these datasets all come from MMEB-train 13.
| Class | Task | #Samples | Datasets |
| Single-Modal | T T (1) | 1M | BAAI-MTP 4 |
| I I (2) | 1.3M | ImageNet-1K 13, NIGHTS ∗ 19 | |
| Cross-Modal | T I (5) | 5.3M | VisualNews ∗ 55, MSCOCO ∗ 52, mmE5-synthetic 8, VisDial ∗ 12, |
| BLIP Bootstrapped Image-Text Pairs 47 | |||
| T VD (3) | 1.6M | Docmatix 43, Colpali train set 18, VisRAG 92 | |
| I T (7) | 0.5M | ImageNet-1K ∗ 13, HatefulMemes ∗ 37, VOC2007 ∗ 17, SUN397 ∗ 88, | |
| VisualNews ∗ 55, MSCOCO ∗ 52, mmE5-synthetic 8 | |||
| Fused-Modal | IT I (5) | 5.3M | MegaPairs 106, mmE5-synthetic 8, CIRR ∗ 60, N24News ∗ 85, |
| MSCOCO ∗ 52 | |||
| IT T (8) | 1.6M | Docmatix 43, mmE5-synthetic 8, OK-VQA ∗ 67, A-OKVQA ∗ 75, | |
| DocVQA ∗ 70, InfographicVQA ∗ 69, ChartQA ∗ 68, Visual7W ∗ 109 | |||
| T IT (2) | 3.2K | WebQA ∗ 7, mmE5-synthetic 8 | |
| IT IT (1) | 3.1K | mmE5-synthetic 8 |
Stage 3. At this stage, to enhance the model’s ability to handle diverse and complex scenarios, we curated a dataset containing 1.5M high-quality, multi-task samples. These data are designed for both image-based vision tasks and visual document retrieval tasks. For the image-based vision tasks, we use MMEB-train 13 as the training set, while for the visual document retrieval tasks, we adopt the Colpali train set 3 and VisRAG 7 as training data.
5 Experiments
5.1 Evaluation Setup & Benchmarks.
We first evaluate the performance of Magic-MM-Embedding on natural image retrieval and visual document retrieval tasks. For natural image retrieval, we use MMEB 13, a comprehensive benchmark comprising 36 sub-datasets and 4 meta-tasks, to assess and report Precision@1. For visual document retrieval (VisDoc), we follow the VLM2Vec-V2 36 settings and use ViDoRe v1 (VDRv1) 3, ViDoRe v2 (VDRv2) 54, VisRAG (VR) 7, and ViDoSeek 55 +MMLongBench-Doc (OOD) 56 to evaluate and report NDCG@5. To assess the performance of Magic-MM-Embedding on cross-modal retrieval, following the UniME-V2 settings 27, we further conduct evaluations on Flickr30K 57, MSCOCO 58, ShareGPT4V 59, Urban1K 16, and SugarCrepe 60 and report Precision@1.
Table 3: Results on the MMEB benchmark 13. The scores are averaged per meta-task. The best performance in each block is in bold. “E” refers to the single-stage retrieval performance using only embedder; “E+R” refers to the two-stage retrieval results, obtained by first using the embedder to retrieve a candidate set, followed by a final ranking from the reranker.
| Model | Backbone (Model Size) | Per Meta-Task Score | Average Score | ||||||
| Classification | VQA | Retrieval | Grounding | IND | OOD | Overall | |||
| # of datasets | 10 | 10 | 12 | 4 | 20 | 16 | 36 | ||
| Zero-shot Results | |||||||||
| CLIP 74 | - (0.4B) | 42.8 | 9.1 | 53.0 | 51.8 | 37.1 | 38.7 | 37.8 | |
| SigLIP 96 | - (0.9B) | 40.3 | 8.4 | 31.6 | 59.5 | 32.3 | 38.0 | 34.8 | |
| EVA-CLIP 79 | - (8.1B) | 56.0 | 10.4 | 49.2 | 58.9 | 38.1 | 45.6 | 43.7 | |
| MagicLens 99 | - (0.4B) | 38.8 | 8.3 | 35.4 | 26.0 | 31.0 | 23.7 | 27.8 | |
| E5-V 34 | Phi3.5-V (4.2B) | 39.1 | 9.6 | 38.0 | 57.6 | 33.1 | 31.9 | 36.1 | |
| E5-V 34 | LLaVA-1.6 (8.4B) | 39.7 | 10.8 | 39.4 | 60.2 | 34.2 | 33.4 | 37.5 | |
| Trained with MMEB | |||||||||
| VLM2Vec-V1 35 | Qwen2VL (2.2B) | 59.0 | 49.4 | 65.4 | 73.4 | 66.0 | 52.6 | 59.3 | |
| UniME 22 | Phi3.5-V (4.2B) | 54.8 | 55.9 | 64.5 | 81.8 | 68.2 | 52.7 | 64.2 | |
| LLaVE 41 | Aquila-VL (2.0B) | 62.1 | 60.2 | 65.2 | 84.9 | 69.4 | 59.8 | 65.2 | |
| UniME-V2 (E) 23 | Qwen2VL (2.2B) | 62.1 | 56.3 | 68.0 | 72.7 | 67.4 | 58.9 | 63.6 | |
| UniME-V2 (E+R) 23 | Qwen2VL (2.2B) | 64.1 | 64.3 | 71.6 | 70.6 | 69.8 | 64.3 | 67.4 | |
| Magic-MM-Embedding (E) | InternVL3-VTC (1.9B) | 60.9 | 63.3 | 72.2 | 84.6 | 74.7 | 59.5 | 68.0 | |
| Magic-MM-Embedding (E+R) | InternVL3-VTC (1.9B) | 61.3 | 67.2 | 73.5 | 89.8 | 75.2 | 63.9 | 70.2 | |
| VLM2Vec-V1 35 | Qwen2VL (8.3B) | 62.6 | 57.8 | 69.9 | 81.7 | 65.2 | 56.3 | 65.8 | |
| UniME 22 | LLaVA-OV (8.0B) | 66.8 | 66.6 | 70.5 | 90.9 | 74.6 | 65.8 | 70.7 | |
| LLaVE 41 | LLaVA-OV (8.0B) | 65.7 | 65.4 | 70.9 | 91.9 | 75.0 | 64.4 | 70.3 | |
| QQMM 89 | LLaVA-OV (8.0B) | 66.8 | 66.8 | 70.5 | 90.4 | 74.7 | 65.6 | 70.7 | |
| UniME-V2 23 | LLaVA-OV (8.0B) | 65.3 | 67.6 | 72.9 | 90.2 | 74.8 | 66.7 | 71.2 | |
| UniME-V2 (E) 23 | Qwen2VL (8.3B) | 64.0 | 60.1 | 73.1 | 82.8 | 72.0 | 63.0 | 68.0 | |
| UniME-V2 (E+R) 23 | Qwen2VL (8.3B) | 63.8 | 66.3 | 73.5 | 75.0 | 71.7 | 65.6 | 69.0 | |
| Magic-MM-Embedding (E) | InternVL3-VTC (8.1B) | 64.8 | 68.1 | 75.0 | 88.7 | 78.3 | 63.6 | 71.8 | |
| Magic-MM-Embedding (E+R) | InternVL3-VTC (8.1B) | 64.3 | 70.9 | 75.7 | 90.4 | 78.4 | 65.9 | 72.8 | |
5.2 Implementation Details
Model Architecture. We implement our framework using PyTorch and the ms-swift 61 library. We adopt InternVL3 44 as our backbone MLLM and name the proposed Visual Token Compression variant InternVL3-VTC. For our parameter-free spatial compression design, we utilize bilinear interpolation to downsample the visual feature map by a factor of 2 in each spatial dimension, thereby retaining only one-fourth of the original visual tokens.
Image Tiling Strategy. For the image tiling strategy, we follow the approach used in InternVL3 44. To ensure computational efficiency, however, we reduce the maximum number of image tiles (MAX_NUM) during both training and inference. Specifically, in stage 1 training, MAX_NUM is set to 4. During the training and inference of downstream embedder and reranker models, we adopt a data-dependent policy: for data containing visual document images, MAX_NUM is set to 4, while for all other natural image data, MAX_NUM is uniformly set to 1.
Embedder Implementation. In stage 1, we train the full model parameters on 48 NVIDIA A800 (80GB) GPUs with a learning rate of and a global batch size of 48. We set the gradient accumulation steps to 8 and apply dataset packing, training the model for 30,000 steps to restore its generative capability. In stages 2 and 3, we perform contrastive pretraining and task-aware fine-tuning using Low-Rank Adaptation (LoRA) on the same 48 NVIDIA A800 (80GB) GPUs. Both stages use a unified maximum learning rate of and a LoRA rank of 16; Detailed hyperparameters are provided in Table˜14. For hard negative judging in stage 3, we employ Qwen3-VL-7B 22 as the discriminator and insert 12 hard negative samples per training instance.
Reranker Implementation. The reranker is initialized from the stage 1 checkpoint. We train it using the same judge-curated data from stage 3 and organize data into pointwise and listwise traing. The model is trained with 24 NVIDIA A800 (80GB) GPUs with a learning rate of and batchsize per device is set to 16 and 12 for 8B and 2B models separately. The model is trained for 2 epochs. The loss weights are set to 1 for both pointwise and listwise objectives. During inference, The reranker is utilized to obtain the two-stage retrieval results, by first using the embedder to retrieve a candidate set, followed by a final ranking from the reranker with pointwise reranking from the Top-5 results from the embedder.
Table 4: Results on the VisDoc 36. The best performance in each block is in bold. “E” refers to the single-stage retrieval performance using only embedder; “E+R” refers to the two-stage retrieval results, obtained by first using the embedder to retrieve a candidate set, followed by a final ranking from the reranker.
| Model | Backbone (Model Size) | VisDoc | ||||
| VDRv1 | VDRv2 | VR | OOD | Overall | ||
| # of Datasets | 10 | 4 | 6 | 4 | 24 | |
| GME 102 | Qwen2VL (2.2B) | 86.1 | 54.0 | 82.5 | 43.1 | 72.7 |
| ColPali 18 | Paligemma (2.9B) | 83.6 | 52.0 | 81.1 | 43.1 | 71.0 |
| Ops-MM-embedding-v1 72 | Qwen2VL (8.3B) | 80.1 | 59.6 | 79.3 | 43.3 | 70.3 |
| VLM2Vec-V2 71 | Qwen2VL (2.2B) | 75.5 | 44.9 | 79.4 | 39.4 | 65.4 |
| Magic-MM-Embedding (E) | InternVL3-VTC (1.9B) | 83.4 | 53.3 | 85.6 | 42.2 | 72.1 |
| Magic-MM-Embedding (E+R) | InternVL3-VTC (1.9B) | 84.4 | 56.1 | 87.4 | 41.8 | 73.3 |
| Ops-MM-embedding-v1 72 | Qwen2VL (8.3B) | 80.1 | 59.6 | 79.3 | 43.3 | 70.3 |
| GME 102 | Qwen2VL (8.3B) | 89.4 | 55.6 | 85.0 | 44.4 | 75.2 |
| LamRA-Qwen2 59 | Qwen2VL (8.3B) | 22.0 | 11.5 | 37.4 | 21.0 | 23.9 |
| LamRA-Qwen2.5 59 | Qwen2.5VL (8.3B) | 56.3 | 33.3 | 58.2 | 40.1 | 50.2 |
| VLM2Vec-V2 71 | Qwen2VL (8.3B) | 78.8 | 52.6 | 82.7 | 42.1 | 69.3 |
| Magic-MM-Embedding (E) | InternVL3-VTC (8.1B) | 86.1 | 59.9 | 87.6 | 43.4 | 75.0 |
| Magic-MM-Embedding (E+R) | InternVL3-VTC (8.1B) | 86.9 | 60.4 | 89.2 | 43.1 | 75.8 |
5.3 Experimental Results
Multimodal Retrieval on MMEB. In Table˜3, we presents the performance comparison against representative baselines. As the results show, traditional dual-tower models such as CLIP, significantly lag behind MLLM-based approaches, due to the inherent limitation of architecture. Among the MLLM methods, our proposed embedder establishes a new state-of-the-art, surpasses strong baselines like UniME-V2 27 and QQMM 24, proves that our progressive training strategy successfully overcomes the potential information loss of token compression. Regarding the two-stage retrieval paradigm, both our method and UniME-V2 27 demonstrate that incorporating a reranker further boosts accuracy. However, a direct comparison reveals our consistent superiority: our model outperforms UniME-V2 in both the standalone embedder setting and the full “Embedder + Reranker” setting. This confirms that our framework provides a stronger foundational retriever and a more effective overall pipeline than the previous best-performing method.
Multimodal Retrieval on VisDoc. Beyond general multimodal retrieval, we evaluate our model on the challenging domain of Visual Document Retrieval (VisDoc), a fine-grained task theoretically demanding high-resolution inputs to preserve textual details. In Table˜4, we report the comparsion result. Surprisingly, our token-efficient method achieves state-of-the-art results despite compressing visual features by 75%, challenging the assumption that high redundancy is strictly necessary for fine-grained retrieval. Additionally, we observe that GME 19 serves as a formidable baseline, outperforming our standalone embedder; we attribute this to GME’s use of massive, proprietary task-aware datasets compared to our smaller, publicly available training sources. However, our full “Embedder + Reranker” pipeline successfully surpasses GME to establish a new state-of-the-art. This demonstrates that our synergistic training strategy effectively bridges the data gap, allowing us to achieve superior performance using only public data and significantly fewer visual tokens.
Table 5: Cross-modal retrieval results on Flickr30K 57, MSCOCO 58, ShareGPT4V 59, Urban1K 16 and SugarCrepe 60.
| Models | Backbone (Model Size) | Short Caption | Long Caption | Compositional | ||||||||
| Flickr30K | MSCOCO | ShareGPT4V | Urban1K | SugarCrepe | ||||||||
| Replace | Swap | Add | ||||||||||
| OpenCLIP 74 | - (0.4B) | 67.3 | 87.2 | 37.0 | 58.1 | 81.8 | 84.0 | 47.0 | 47.0 | 79.5 | 62.7 | 74.9 |
| CLIP 10 | - (2.5B) | 79.5 | 92.9 | 51.3 | 67.3 | 90.1 | 93.6 | 77.8 | 80.7 | 86.5 | 68.9 | 88.4 |
| EVA-CLIP 79 | - (8.1B) | 80.3 | 94.5 | 52.0 | 70.1 | 93.1 | 91.2 | 80.4 | 77.8 | 85.9 | 70.3 | 86.7 |
| E5-V 34 | Phi3.5-V (4.2B) | 72.2 | 79.6 | 44.7 | 53.4 | 86.0 | 88.5 | 83.8 | 83.6 | 88.2 | 66.6 | 75.3 |
| VLM2Vec 35 | Qwen2-VL (2.2B) | 69.3 | 89.6 | 40.0 | 62.5 | 78.1 | 88.2 | 78.7 | 83.9 | 67.2 | 46.5 | 66.4 |
| UniME 22 | Qwen2-VL (2.2B) | 74.9 | 90.6 | 44.0 | 63.5 | 83.6 | 88.6 | 83.3 | 83.2 | 65.6 | 45.2 | 65.7 |
| UniME-V2 23 | Qwen2-VL (2.2B) | 79.8 | 89.9 | 53.7 | 65.1 | 91.6 | 94.2 | 95.6 | 92.2 | 70.9 | 51.2 | 70.2 |
| Magic-MM-Embedding | InternVL3-VTC (1.9B) | 84.4 | 93.0 | 61.4 | 75.8 | 97.2 | 97.3 | 98.4 | 97.8 | 91.6 | 82.6 | 94.2 |
| E5-V 34 | LLaVA-1.6 (8.4B) | 77.3 | 85.7 | 49.1 | 57.6 | 85.1 | 82.1 | 88.9 | 83.2 | 86.3 | 68.7 | 66.9 |
| VLM2Vec 35 | Qwen2-VL (8.3B) | 80.0 | 94.2 | 49.2 | 68.5 | 78.5 | 90.4 | 94.0 | 94.2 | 70.0 | 51.7 | 72.2 |
| UniME 22 | Qwen2-VL (8.3B) | 80.8 | 92.7 | 50.9 | 69.8 | 86.5 | 93.8 | 95.3 | 94.0 | 68.8 | 53.0 | 69.8 |
| UniME 22 | LLaVA-OV (8.0B) | 83.3 | 94.4 | 54.8 | 74.0 | 93.9 | 89.3 | 94.3 | 95.5 | 80.5 | 65.5 | 82.2 |
| UniME-V2 23 | Qwen2-VL (8.3B) | 84.6 | 93.5 | 57.3 | 70.3 | 94.3 | 95.2 | 97.2 | 96.3 | 77.8 | 62.2 | 79.0 |
| UniME-V2 23 | LLaVA-OV (8.0B) | 85.5 | 93.7 | 60.9 | 74.1 | 95.1 | 94.1 | 96.3 | 96.7 | 88.6 | 73.7 | 90.5 |
| Magic-MM-Embedding | InternVL3-VTC (8.1B) | 82.9 | 93.1 | 63.2 | 79.3 | 98.5 | 98.3 | 98.5 | 98.7 | 92.6 | 86.9 | 95.1 |
Text-Image Cross-Modal Retrieval. Following previous works 27 28, we further evaluate the text-image cross-modal retrieval ability of our embedding model without reranker. Based on the results in Table˜5, in almost datasets, our embedding method consistently delivers new state-of-the-art results. On the 8B scale, our method achieves significant gains even on benchmarks where the strong baseline UniME-V2 has reached near-saturation levels 95%. Specifically, we improve Precision@1 on ShareGPT4V (text-to-image) from 95.1% to 98.5% and on Urban1K (image-to-text) from 96.7% to 98.7%. The superiority is even more profound at the 2B scale, where our model dominates UniME-V2 on the challenging SugarCrepe benchmark by a massive margin—scoring 91.6%, 82.6%, and 94.2% on its three sub-settings compared to 70.9%, 51.2%, and 70.2%, respectively. Crucially, these results of our method are achieved using only 64 visual tokens, far fewer than other standard methods. This empirical evidence leads to a pivotal conclusion: visual token compression is not a trade-off but a strategic advantage. When synergized with our progressive training pipeline, it significantly enhances inference efficiency while simultaneously achieving better crossmodal alignment.
Table 6: Inference efficiency comparison. # and # refer to the average number of visual tokens in queries and candidates containing images, respectively. and mean the average latency (millisecond) of query inference and candidate inference, respectively. The best performance in each block is in bold.
| Model | Backbone (Model Size) | MMEB | VisDoc | ||||||
| # | # | # | # | ||||||
| VLM2Vec 35 | Phi3.5-V (4.2B) | 757.0 | 99.4 | 757.0 | 85.9 | 0 | 34.0 | 757.0 | 128.6 |
| GME 102 | Qwen2VL (2.2B) | 362.8 | 46.8 | 256.0 | 34.5 | 0 | 19.3 | 1024.0 | 153.8 |
| LLaVE 41 | Aquila-VL (2.0B) | 3699.0 | 162.8 | 3699.0 | 143.0 | 0 | 18.5 | 3699.0 | 233.6 |
| InternVL3 107 | InternVL3 (1.9B) | 398.4 | 37.1 | 256.0 | 29.2 | 0 | 19.8 | 1280.0 | 103.6 |
| Magic-MM-Embedding | InternVL3-VTC (1.9B) | 99.6 | 29.9 | 64.0 | 26.1 | 0 | 19.7 | 320.0 | 57.3 |
| VLM2Vec 35 | LLaVA-1.6 (8.4B) | 2928.0 | 332.3 | 2928.0 | 278.9 | 0 | 32.4 | 2928.0 | 458.1 |
| GME 102 | Qwen2VL (8.3B) | 362.8 | 82.2 | 256.0 | 56.7 | 0 | 26.6 | 1024.0 | 268.2 |
| LamRA 59 | Qwen2.5VL (8.3B) | 362.8 | 83.4 | 256.0 | 61.6 | 0 | 28.9 | 1024.0 | 251.7 |
| UniME-V2 23 | LLaVA-OV (8.0B) | 7371.0 | 906.9 | 7371.0 | 788.1 | 0 | 32.1 | 7371.0 | 1341.1 |
| InternVL3 107 | InternVL3 (8.1B) | 398.4 | 76.7 | 256.0 | 55.9 | 0 | 33.8 | 1280.0 | 260.4 |
| Magic-MM-Embedding | InternVL3-VTC (8.1B) | 99.6 | 50.9 | 64.0 | 40.6 | 0 | 33.8 | 320.0 | 94.8 |
Comparison on Inference Cost. We compared the inference efficiency of the proposed Magic-MM-Embedding with the currently popular MLLM-based Embedders, as shown in Table˜6. For each MLLM backbone, we selected one embedding model for comparison. We randomly sampled 5,000 queries and candidates from the MMEB and VisDoc training sets. We measured the average inference latency and the average number of visual tokens for queries and candidates on both MMEB and VisDoc. To ensure fairness, we resized the resolution of visual document images to 896 896, and the resolution of natural images to 448 448. All results were obtained using an NVIDIA L20 (48GB) GPU with a batch size of 1 and BF16 precision. No acceleration techniques were used during testing.
Under models with similar parameter scales, Magic-MM-Embedding demonstrated significantly lower inference latency than almost all existing models, thanks to the substantial reduction in computational complexity brought by visual token compression. For example, compared to LLaVE-2B based on Aquila-VL, Magic-MM-Embedding-2B reduced the inference latency for MMEB queries from 162.8 ms to 29.9 ms and for VisDoc candidates from 233.6 ms to 57.3 ms. We observed that for query inference latency in VisDoc, Magic-MM-Embedding(2B/8B) had slightly higher latency than GME(2B/8B). This is because, for T VD tasks, the system prompt length of InternVL3 is slightly longer than that of Qwen2-VL, given the nearly identical parameter scale of the language models. However, this latency difference can be mitigated in actual deployment using prefix cache techniques 62. We also conducted a comparison with the native InternVL3 architecture. The only difference in Magic-MM-Embedding is the introduction of a parameter-free visual token compression module. We find that, compared with the native architecture, reducing the number of visual tokens by 75% leads to a significant improvement in inference efficiency.
5.4 Ablation Study
Ablation Study on Progressive Training Pipeline & Reranker. We analyze the contribution of each component in our progressive coarse-to-fine training pipeline. The results are reported in Table˜7. All experiments are conducted with Magic-MM-Embedding-2B. We use the model after contrastive warm-up in stage 2 as the baseline, where learning is performed using only in-batch negatives. We find that incorporating the global hard negative mining strategy yields absolute gains of 2.5 and 2.3 on MMEB and VisDoc, respectively. This indicates that the introduction of hard negatives substantially enhances the discriminative ability of the model. On top of this, we further finetune the model using high-quality multi-task data filtered by MLLM judgment. This brings additional improvements of 2.6 and 1.4 on MMEB and VisDoc, which shows that task-aware finetuning with MLLM-as-a-Judge helps the model adapt effectively to complex and diverse downstream tasks. We also study the impact of the synergistic reranker on model performance. As shown in Table˜7, adding a reranker yields further improvements of 2.2 and 1.2 on MMEB and VisDoc, respectively. This confirms that incorporating reranking into the inference pipeline can further enhance retrieval performance.
Table 7: Ablation study on progressive training pipeline & reranker. We report the average score on MMEB and VisDoc. Each row represents the cumulative addition of a component. “Warm-Up” denotes a contrastive warm-up phase in stage 2 using only in-batch negatives; “Global-HNM” refers to pretraining in stage 2 with Global Hard Negative Mining; “MLLM-Judge-FT” indicates finetuning with an MLLM as a judge; and “Reranker” represents a two-stage retrieval with synergistic reranker.
| Stage 2 | Stage 2 | Stage 3 | Inference | MMEB | VisDoc |
| (Warm-Up) | (Global-HNM) | (MLLM-Judge-FT) | (Reranker) | ||
| ✓ | ✗ | ✗ | ✗ | 62.9 | 68.4 |
| ✓ | ✓ | ✗ | ✗ | 65.4 | 70.7 |
| ✓ | ✓ | ✓ | ✗ | 68.0 | 72.1 |
| ✓ | ✓ | ✓ | ✓ | 70.2 | 73.3 |
Ablation Study on the Number and Types of Hard Negatives (HN). We investigate the sensitivity of our model to the number of hard negatives during stage 3 training, as shown in Table˜8. All experiments are conducted on Magic-MM-Embedding-2B, where is varied from 0 to 20. The results show that, compared with using only the standard in-batch negatives sampling strategy, introducing any number of MLLM-based hard negatives consistently yields substantial performance improvements. As increases, the model performance first improves and then slightly declines. For example, on MMEB, the performance peaks at , and further increasing leads to a mild degradation. To verify the effectiveness of using an MLLM as an “expert” to mine hard negatives, we further compare our approach with a rule-based hard negative mining strategy, as reported in Table˜8. This strategy removes the ground-truth sample from the retrieved Top- candidates and treats the remaining samples as hard negatives, inevitably introducing false negatives. The experimental results show that, for the same value of , models trained with MLLM-based hard negatives consistently and significantly outperform those trained with the same number of Rule-based hard negatives.
Table 8: Impact of the Number and Types of Hard Negatives (HN). “Avg.” means the average of the MMEB score and the VisDoc score.
| #HN () | MLLM-based HN | Rule-based HN | ||||
| MMEB | VisDoc | Avg. | MMEB | VisDoc | Avg. | |
| 0 | 65.5 | 70.6 | 68.1 | 65.5 | 70.6 | 68.1 |
| 4 | 67.4 | 71.7 | 69.5 | 65.7 | 69.5 | 67.6 |
| 8 | 67.8 | 71.9 | 69.9 | 66.5 | 70.6 | 68.6 |
| 12 | 68.0 | 72.1 | 70.0 | 67.0 | 70.1 | 68.5 |
| 16 | 67.9 | 72.1 | 70.0 | 65.9 | 70.7 | 68.3 |
| 20 | 67.6 | 71.9 | 69.8 | 67.1 | 70.5 | 68.8 |
Ablation Study on Visual Token Compression for Training Efficiency. We use InternVL3-VTC-2B and the vanilla InternVL3-2B as backbones to investigate the impact of with and without a token compression module on training efficiency. Both models are trained with contrastive learning on the 16M dataset used during the stage 2 warm-up phase. During training, the batch size is increased to the maximum allowed by GPU memory to ensure sufficient training of the model. All other training hyperparameters are kept identical between the two models except for batch size. The experimental results are shown in Table˜9. We observe that, with almost no degradation in model performance, the proposed visual token compression method can significantly improve training efficiency. For example, for a 2B-scale model, the training time for 2 epochs is reduced from approximately 53 hours to 23 hours. In addition, visual token compression substantially reduces GPU memory consumption, enabling the model to support larger training batch sizes, which is particularly beneficial for contrastive learning methods that rely on in-batch negatives.
Table 9: Ablation of visual token compression for training efficiency.
| Backbone | Training Duration | MMEB | VisDoc | Global Batch Size |
|---|---|---|---|---|
| InternVL3 (vanilla) | 52h 43m 35s | 62.9 | 68.4 | 6144 |
| InternVL3-VTC (ours) | 22h 57m 6s | 63.7 | 68.5 | 3456 |
Ablation Study on LoRA Rank. Table˜10 presents the ablation results of LoRA rank. We conducted experiments using Magic-MM-Embedding-2B during the stage 2 contrastive learning warm-up phase. We set the LoRA rank to 8, 16, and 32 for the experiments. We found that when the LoRA rank is set to 16, the average metrics on MMEB and VisDoc are optimal. Further increasing the LoRA rank leads to a decline in overall performance. Therefore, in all training of the embedder, the LoRA rank is set to 16.
Table 10: Ablation analysis of LoRA rank. “Avg.” means the average of the MMEB score and the VisDoc score.
| LoRA Rank | MMEB | VisDoc | Avg. |
|---|---|---|---|
| 8 | 62.9 | 68.0 | 65.5 |
| 16 | 62.9 | 68.4 | 65.7 |
| 32 | 62.6 | 67.6 | 65.1 |
6 Conclusion
In this work, we identified a critical computational bottleneck in current MLLM-based universal embedding models: the prohibitively high cost of processing redundant visual tokens. To address this, we proposed a simple yet strong baseline using merely 25% of the baseline visual tokens, significantly reducing inference latency and memory footprint with new state-of-the-art performance. Crucially, we demonstrated that the performance of this simplified architecture is not limited by its capacity, but by the quality of its training. And we introduced a novel three-stage progressive training pipeline—advancing from generative restoration to contrastive self-mining, and finally to task-aware refinement guided by an MLLM-as-a-Judge. This strategy effectively distills essential semantic information into the compressed representation. Furthermore, by equipping this efficient embedder with a synergistically trained reranker, we established a comprehensive retrieval system. Extensive experiments demonstrate that our full system outperforms competitors trained on much larger proprietary datasets, proving that high efficiency and superior effectiveness can indeed be achieved simultaneously.
References
Appendix A Task Instruction for Embedding
Table 11: Query and target instructions for different datasets (Part 1 of 2). For the queries in mmE5-synthetic 53, we use the original instructions from the dataset.
| Task | Dataset | Query Instruction | Target Instruction |
| T T | BAAI-MTP 4 | Retrieve relevant texts based on a given query. | Represent the given text. |
| I I | ImageNet-1K 13 | Find a image that looks similar to the provided image. | Represent the given image. |
| NIGHTS 19 | Find a day-to-day image that looks similar to the provided image. | Represent the given image. | |
| T I | BLIP Bootstrapped Image-Text Pairs 47 | Retrieve relevant images based on a given query. | Represent the given image. |
| VisDial 12 | Represent the given dialogue about an image, which is used for image retrieval. | Represent the given image. | |
| VisualNews 55 | Retrieve an image of the given query. | Represent the given image. | |
| MSCOCO 52 | Find me an everyday image that matches the given query. | Represent the given image. | |
| Flickr30K 73 | Find me an everyday image that matches the given query. | Represent the given image. | |
| ShareGPT4V 9 | Find me an everyday image that matches the given query. | Represent the given image. | |
| Urban1K 97 | Find me an everyday image that matches the given query. | Represent the given image. | |
| mmE5-synthetic 8 | - | Represent the given image. | |
| T VD | Docmatix 43 | Retrieve relevant visual documents based on a given query. | Represent the given visual documents. |
| Colpali 18 | Retrieve relevant visual documents based on a given query. | Represent the given visual documents. | |
| VisRAG 92 | Retrieve relevant visual documents based on a given query. | Represent the given visual documents. | |
| ViDoSeek 84 | Retrieve relevant visual documents based on a given query. | Represent the given visual documents. | |
| MMLongBench 64 | Retrieve relevant visual documents based on a given query. | Represent the given visual documents. | |
| Wiki-SS-NQ 62 | Find the document image that can answer the given query. | Represent the given visual documents. | |
| I T | ImageNet-1K 13 | Represent the given image for classification. | Represent the given text. |
| HatefulMemes 37 | Represent the given image for binary classification to determine whether it constitutes hateful speech or not. | Represent the given text. | |
| VOC2007 17 | Identify the object shown in the image. | Represent the given text. | |
| SUN397 88 | Identify the scene shown in the image. | Represent the given text. | |
| Place365 105 | Identify the scene shown in the image. | Represent the given text. | |
| ImageNet-A 27 | Represent the given image for classification. | Represent the given text | |
| ImageNet-R 26 | Represent the given image for classification. | Represent the given text | |
| ObjectNet 3 | Identify the object shown in the image. | Represent the given text | |
| Country-211 74 | Identify the country depicted in the image. | Represent the given text | |
| VisualNews 55 | Find a caption for the news in the given photo. | Represent the given text. | |
| MSCOCO 52 | Find an image caption describing the given everyday image. | Represent the given text. | |
| Flickr30K 73 | Find an image caption describing the given image. | Represent the given text. | |
| ShareGPT4V 9 | Find an image caption describing the given image. | Represent the given text. | |
| Urban1K 97 | Find an image caption describing the given image. | Represent the given text. | |
| SugarCrepe 28 | Find an image caption describing the given image. | Represent the given text. | |
| mmE5-synthetic 8 | - | Represent the given text. |
Table 12: Query and target instructions for different datasets (Part 2 of 2). For the queries in mmE5-synthetic 53, we use the original instructions from the dataset.
| Task | Dataset | Query Instruction | Target Instruction |
| IT I | MegaPairs 106 | Represent the given image with the given query and retrieve the related images. | Represent the given image. |
| CIRR 60 | Given an image, find a similar everyday image with the described changes as the given query. | Represent the given image. | |
| N24News 85 | Represent the given news image with the given query for domain classification. | Represent the given text. | |
| MSCOCO 52 | Select the portion of the image where the object label is represented by the given query. | Represent the cropped image. | |
| FashionIQ 87 | Find an image to match the fashion image and style note. | Represent the given image. | |
| Visual7W-Pointing 109 | Select the portion of the image that answers the given query. | Represent the cropped image. | |
| RefCOCO 36 | Select the portion of the image where the object label is represented by the given query. | Represent the cropped image. | |
| mmE5-synthetic 8 | - | Represent the given image. | |
| IT T | Docmatix 43 | Represent the given image with the given query and retrieve the answer. | Represent the given text. |
| OK-VQA 67 | Represent the given image with the given query and retrieve the answer. | Represent the given text. | |
| A-OKVQA 75 | Represent the given image with the given query and retrieve the answer. | Represent the given text. | |
| DocVQA 70 | Represent the given image with the given query and retrieve the answer. | Represent the given text. | |
| InfographicVQA 69 | Represent the given image with the given query and retrieve the answer. | Represent the given text. | |
| ChartQA 68 | Represent the given image with the given query and retrieve the answer. | Represent the given text. | |
| Visual7W 109 | Represent the given image with the given query and retrieve the answer. | Represent the given text. | |
| ScienceQA 61 | Represent the given image with the given query and retrieve the answer. | Represent the given text. | |
| VizWiz 24 | Represent the given image with the given query and retrieve the answer. | Represent the given text. | |
| GQA 30 | Represent the given image with the given query and retrieve the answer. | Represent the given text. | |
| TextVQA 78 | Represent the given image with the given query and retrieve the answer. | Represent the given text. | |
| mmE5-synthetic 8 | - | Represent the given text. | |
| T IT | WebQA 7 | Find a related image and text content from Wikipedia that answers the given query. | Represent the given Wikipedia image with related text information. |
| EDIS 58 | Find a related image and text content from a news that matches the provided query. | Represent the given image with related text information. | |
| mmE5-synthetic 8 | - | Represent the given image with related text information. | |
| IT IT | OVEN 29 | Retrieve a Wikipedia image-description pair that provides evidence for the given query. | Represent the given image with related text information. |
| RefCOCO-Matching 36 | Select the identical object in the image that follows the given query. | Represent the object in the image that follows the given text. |
Appendix B Judgment Instruction for Hard Negatives Filtering Using MLLM in Stage 3
Table 13: Instructions for MLLM judgment in the stage 3. For the HatefulMemes dataset, because it has only Yes/No labels, removing the ground truth leaves only correct negative samples. Therefore, we did not use MLLMs to judge this dataset.
| Domain | Dataset | Judgment Instruction |
| MMEB | ImageNet-1K 13 | Determine whether a given image contains an object specified by a class label. |
| N24News 85 | Given news containing both image and text content, determine whether the category of the news matches the given category. | |
| VOC2007 17 | Determine whether a given image contains an object specified by a class label. | |
| SUN397 88 | Determine whether the given image matches the given scene description. | |
| OK-VQA 67 | Given a reference image and a question, determine whether the provided answer is correct. | |
| A-OKVQA 75 | Given a reference image and a question, determine whether the provided answer is correct. | |
| DocVQA 70 | Given a reference image and a question, determine whether the provided answer is correct. | |
| InfographicsVQA 69 | Given a reference image and a question, determine whether the provided answer is correct. | |
| ChartQA 68 | Given a reference image and a question, determine whether the provided answer is correct. | |
| Visual7W 109 | Given a reference image and a question, determine whether the provided answer is correct. | |
| VisDial 12 | Determine whether the given dialogue text is relevant to the given target image. | |
| CIRR 60 | Given a text instruction, a reference image, and a target image, determine whether the reference image transformed by the text instruction is relevant to the target image. | |
| VisualNews (T I) 55 | Determine whether the given query text is relevant to the given image. | |
| VisualNews (I T) 55 | Determine whether the given text can serve as a caption for the given image. | |
| MSCOCO (T I) 52 | Determine whether the given query text is relevant to the given image. | |
| MSCOCO (I T) 52 | Determine whether the given text can serve as a caption for the given image. | |
| NIGHTS 19 | Determine whether the two given images are similar. | |
| WebQA 7 | Determine whether the query text is relevant to the given image-text mixed content. | |
| MSCOCO (IT I) 52 | Given a reference image, a object label expressed in text pointing to an object in the reference image, and a crop extracted from an image, determine whether the text label points to the given crop. | |
| VisDoc | Colpali 18 | Determine whether the given query text is relevant to the given visual document image. |
| VisRAG 92 | Determine whether the given query text is relevant to the given visual document image. |
Appendix C Hyperparameters for Embedder Training
Table 14: Hyperparameters for stage 1 and stage 2 training. “Warm-Up” denotes a contrastive warm-up phase in stage 2 using only in-batch negatives; “Global-HNM” refers to pretraining in stage 2 with Global Hard Negative Mining; “MLLM-Judge-FT” indicates finetuning with an MLLM as a judge.
| Hyperparameter | Stage 2 | Stage 2 | Stage 3 | |||
| (Warm-Up) | (Global-HNM) | (MLLM-Judge-FT) | ||||
| 2B | 8B | 2B | 8B | 2B | 8B | |
| #Samples | 16M | 16M | 16M | 16M | 1.5M | 1.5M |
| #Hard Negatives | 0 | 0 | 2 | 2 | 12 | 12 |
| #GPUs | 48 | |||||
| Maximum learning rate | ||||||
| Temperature | 0.03 | |||||
| LoRA rank | 16 | |||||
| Training epochs | 2 | |||||
| Batch size per device | 128 | 72 | 64 | 48 | 12 | 10 |
Footnotes
-
Cong Wei, Yang Chen, Haonan Chen, Hexiang Hu, Ge Zhang, Jie Fu, Alan Ritter, and Wenhu Chen. Uniir: Training and benchmarking universal multimodal information retrievers. In European Conference on Computer Vision, pages 387–404. Springer, 2024. ↩ ↩2 ↩3
-
Kai Zhang, Yi Luan, Hexiang Hu, Kenton Lee, Siyuan Qiao, Wenhu Chen, Yu Su, and Ming-Wei Chang. Magiclens: Self-supervised image retrieval with open-ended instructions. arXiv:2403.19651, 2024. ↩ ↩2
-
Manuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Gautier Viaud, Céline Hudelot, and Pierre Colombo. Colpali: Efficient document retrieval with vision language models. arXiv preprint arXiv:2407.01449, 2024. ↩ ↩2 ↩3 ↩4
-
Xueguang Ma, Sheng-Chieh Lin, Minghan Li, Wenhu Chen, and Jimmy Lin. Unifying multimodal retrieval via document screenshot embedding. arXiv preprint arXiv:2406.11251, 2024. ↩
-
Chao Zhang, Haoxin Zhang, Shiwei Wu, Di Wu, Tong Xu, Xiangyu Zhao, Yan Gao, Yao Hu, and Enhong Chen. Notellm-2: Multimodal large representation models for recommendation. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1, pages 2815–2826, 2025. ↩
-
Ramin Giahi, Kehui Yao, Sriram Kollipara, Kai Zhao, Vahid Mirjalili, Jianpeng Xu, Topojoy Biswas, Evren Korpeoglu, and Kannan Achan. Vl-clip: Enhancing multimodal recommendations via visual grounding and llm-augmented clip embeddings. In Proceedings of the Nineteenth ACM Conference on Recommender Systems, pages 482–491, 2025. ↩
-
Shi Yu, Chaoyue Tang, Bokai Xu, Junbo Cui, Junhao Ran, Yukun Yan, Zhenghao Liu, Shuo Wang, Xu Han, Zhiyuan Liu, and Maosong Sun. Visrag: Vision-based retrieval-augmented generation on multi-modality documents. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. ↩ ↩2 ↩3 ↩4
-
Soyeong Jeong, Kangsan Kim, Jinheon Baek, and Sung Ju Hwang. Videorag: Retrieval-augmented generation over video corpus. arXiv preprint arXiv:2501.05874, 2025. ↩
-
Xueguang Ma, Shengyao Zhuang, Bevan Koopman, Guido Zuccon, Wenhu Chen, and Jimmy Lin. Visa: Retrieval augmented generation with visual source attribution. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 30154–30169, 2025. ↩
-
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Marina Meila and Tong Zhang, editors, Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, volume 139 of Proceedings of Machine Learning Research, pages 8748–8763. PMLR, 2021. ↩ ↩2
-
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report. arXiv preprint arXiv:2511.21631, 2025. ↩ ↩2 ↩3
-
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024. ↩ ↩2 ↩3
-
Ziyan Jiang, Rui Meng, Xinyi Yang, Semih Yavuz, Yingbo Zhou, and Wenhu Chen. Vlm2vec: Training vision-language models for massive multimodal embedding tasks. ICLR, 2025. ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8 ↩9
-
Ting Jiang, Minghui Song, Zihan Zhang, Haizhen Huang, Weiwei Deng, Feng Sun, Qi Zhang, Deqing Wang, and Fuzhen Zhuang. E5-v: Universal embeddings with multimodal large language models. arXiv:2407.12580, 2024. ↩ ↩2 ↩3
-
Tiancheng Gu, Kaicheng Yang, Ziyong Feng, Xingjun Wang, Yanzhao Zhang, Dingkun Long, Yingda Chen, Weidong Cai, and Jiankang Deng. Breaking the modality barrier: Universal embedding learning with multimodal llms. In Proceedings of the 33rd ACM International Conference on Multimedia, MM ’25, page 2860–2869, New York, NY, USA, 2025. Association for Computing Machinery. ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8
-
Beichen Zhang, Pan Zhang, Xiaoyi Dong, Yuhang Zang, and Jiaqi Wang. Long-clip: Unlocking the long-text capability of clip. In ECCV, 2024. ↩ ↩2 ↩3 ↩4 ↩5
-
Anjia Cao, Xing Wei, and Zhiheng Ma. Flame: Frozen large language models enable data-efficient language-image pre-training. arXiv:2411.11927, 2024. ↩ ↩2
-
Mert Yuksekgonul, Federico Bianchi, Pratyusha Kalluri, Dan Jurafsky, and James Zou. When and why vision-language models behave like bags-of-words, and what to do about it? arXiv preprint arXiv:2210.01936, 2022. ↩ ↩2
-
Xin Zhang, Yanzhao Zhang, Wen Xie, Mingxin Li, Ziqi Dai, Dingkun Long, Pengjun Xie, Meishan Zhang, Wenjie Li, and Min Zhang. Gme: Improving universal multimodal retrieval by multimodal llms. arXiv preprint arXiv:2412.16855, 2024. ↩ ↩2 ↩3
-
Junjie Zhou, Yongping Xiong, Zheng Liu, Ze Liu, Shitao Xiao, Yueze Wang, Bo Zhao, Chen Jason Zhang, and Defu Lian. Megapairs: Massive data synthesis for universal multimodal retrieval. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 19076–19095, 2025. ↩ ↩2 ↩3 ↩4
-
Weijian Jian, Yajun Zhang, Dawei Liang, Chunyu Xie, Yixiao He, Dawei Leng, and Yuhui Yin. Rzenembed: Towards comprehensive multimodal retrieval. CoRR, abs/2510.27350, 2025. ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8
-
Mingxin Li, Yanzhao Zhang, Dingkun Long, Keqin Chen, Sibo Song, Shuai Bai, Zhibo Yang, Pengjun Xie, An Yang, Dayiheng Liu, et al. Qwen3-vl-embedding and qwen3-vl-reranker: A unified framework for state-of-the-art multimodal retrieval and ranking. arXiv preprint arXiv:2601.04720, 2026. ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8 ↩9
-
Zhibin Lan, Liqiang Niu, Fandong Meng, Jie Zhou, and Jinsong Su. Llave: Large language and vision embedding models with hardness-weighted contrastive learning. CoRR, abs/2503.04812, 2025. ↩ ↩2
-
Youze Xue, Dian Li, and Gang Liu. Improve multi-modal embedding learning via explicit hard negative gradient amplifying. arXiv preprint arXiv:2506.02020, 2025. ↩ ↩2 ↩3
-
Sheng-Chieh Lin, Chankyu Lee, Mohammad Shoeybi, Jimmy Lin, Bryan Catanzaro, and Wei Ping. Mm-embed: Universal multimodal retrieval with multimodal llms. arXiv preprint arXiv:2411.02571, 2024. ↩ ↩2
-
Raghuveer Thirukovalluru, Rui Meng, Ye Liu, Mingyi Su, Ping Nie, Semih Yavuz, Yingbo Zhou, Wenhu Chen, Bhuwan Dhingra, et al. Breaking the batch barrier (b3) of contrastive learning via smart batch mining. arXiv preprint arXiv:2505.11293, 2025. ↩ ↩2
-
Tiancheng Gu, Kaicheng Yang, Kaichen Zhang, Xiang An, Ziyong Feng, Yueyi Zhang, Tom Weidong Cai, Jiankang Deng, and Lidong Bing. Unime-v2: Mllm-as-a-judge for universal multimodal embedding learning. AAAI, 2026. ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8 ↩9
-
Yikun Liu, Pingan Chen, Jiayin Cai, Xiaolong Jiang, Yao Hu, Jiangchao Yao, Yanfeng Wang, and Weidi Xie. Lamra: Large multimodal model as your advanced retrieval assistant. CVPR, 2024. ↩ ↩2 ↩3 ↩4 ↩5 ↩6
-
Lanyun Zhu, Deyi Ji, Tianrun Chen, Haiyang Wu, and Shiqi Wang. Retrv-r1: A reasoning-driven mllm framework for universal and efficient multimodal retrieval. NeurIPS, 2025. ↩ ↩2
-
Zhibin Lan, Liqiang Niu, Fandong Meng, Jie Zhou, and Jinsong Su. Ume-r1: Exploring reasoning-driven generative multimodal embeddings. arXiv preprint arXiv:2511.00405, 2025. ↩ ↩2
-
Xuanming Cui, Jianpeng Cheng, Hong-you Chen, Satya Narayan Shukla, Abhijeet Awasthi, Xichen Pan, Chaitanya Ahuja, Shlok Kumar Mishra, Yonghuan Yang, Jun Xiao, et al. Think then embed: Generative context improves multimodal embedding. arXiv preprint arXiv:2510.05014, 2025. ↩ ↩2
-
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021. ↩
-
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024. ↩
-
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In International conference on machine learning, pages 19730–19742. PMLR, 2023. ↩ ↩2
-
Junbum Cha, Wooyoung Kang, Jonghwan Mun, and Byungseok Roh. Honeybee: Locality-enhanced projector for multimodal llm. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13817–13827, 2024. ↩
-
Rui Meng, Ziyan Jiang, Ye Liu, Mingyi Su, Xinyi Yang, Yuepeng Fu, Can Qin, Zeyuan Chen, Ran Xu, Caiming Xiong, et al. Vlm2vec-v2: Advancing multimodal embedding for videos, images, and visual documents. arXiv preprint arXiv:2507.04590, 2025. ↩ ↩2 ↩3
-
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. In International conference on machine learning, pages 4904–4916. PMLR, 2021. ↩
-
Jinxiang Liu, Chen Ju, Weidi Xie, and Ya Zhang. Exploiting transformation invariance and equivariance for self-supervised sound localisation. In Proceedings of the 30th ACM International Conference on Multimedia, pages 3742–3753, 2022. ↩
-
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In International conference on machine learning, pages 12888–12900. PMLR, 2022. ↩ ↩2
-
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. In Proceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023. ↩
-
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scaling laws for contrastive language-image learning. arXiv:2212.07143, 2022. ↩
-
Quan Sun, Jinsheng Wang, Qiying Yu, Yufeng Cui, Fan Zhang, Xiaosong Zhang, and Xinlong Wang. Eva-clip-18b: Scaling clip to 18 billion parameters. arXiv:2402.04252, 2023. ↩
-
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019. ↩
-
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479, 2025. ↩ ↩2 ↩3
-
Shaolei Zhang, Qingkai Fang, Zhe Yang, and Yang Feng. Llava-mini: Efficient image and video large multimodal models with one vision token. arXiv preprint arXiv:2501.03895, 2025. ↩
-
Cheng Yang, Yang Sui, Jinqi Xiao, Lingyi Huang, Yu Gong, Chendi Li, Jinghua Yan, Yu Bai, Ponnuswamy Sadayappan, Xia Hu, et al. Topv: Compatible token pruning with inference time optimization for fast and low-memory multimodal vision language model. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 19803–19813, 2025. ↩
-
Mohamed Dhouib, Davide Buscaldi, Sonia Vanier, and Aymen Shabou. Pact: Pruning and clustering-based token reduction for faster visual language models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 14582–14592, 2025. ↩
-
Aäron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. CoRR, abs/1807.03748, 2018. ↩
-
Yuanhan Zhang, Bo Li, haotian Liu, Yong jae Lee, Liangke Gui, Di Fu, Jiashi Feng, Ziwei Liu, and Chunyuan Li. Llava-next: A strong zero-shot video understanding model, April 2024. ↩
-
Hugo Laurençon, Andrés Marafioti, Victor Sanh, and Léo Tronchon. Building and better understanding vision-language models: insights and future directions. arXiv preprint arXiv:2408.12637, 2024. ↩
-
Beijing Academy of Artificial Intelligence. Baai-mtp dataset. https://data.baai.ac.cn/datadetail/BAAI-MTP. Accessed: 2026-01-24. ↩
-
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. ↩
-
Haonan Chen, Liang Wang, Nan Yang, Yutao Zhu, Ziliang Zhao, Furu Wei, and Zhicheng Dou. mme5: Improving multimodal multilingual embeddings via high-quality synthetic data. arXiv preprint arXiv:2502.08468, 2025. ↩ ↩2 ↩3
-
Quentin Macé, António Loison, and Manuel Faysse. Vidore benchmark v2: Raising the bar for visual retrieval. arXiv preprint arXiv:2505.17166, 2025. ↩
-
Qiuchen Wang, Ruixue Ding, Zehui Chen, Weiqi Wu, Shihang Wang, Pengjun Xie, and Feng Zhao. Vidorag: Visual document retrieval-augmented generation via dynamic iterative reasoning agents. arXiv preprint arXiv:2502.18017, 2025. ↩
-
Yubo Ma, Yuhang Zang, Liangyu Chen, Meiqi Chen, Yizhu Jiao, Xinze Li, Xinyuan Lu, Ziyu Liu, Yan Ma, Xiaoyi Dong, et al. Mmlongbench-doc: Benchmarking long-context document understanding with visualizations. Advances in Neural Information Processing Systems, 37:95963–96010, 2024. ↩
-
Bryan A Plummer, Liwei Wang, Chris M Cervantes, Juan C Caicedo, Julia Hockenmaier, and Svetlana Lazebnik. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. In Proceedings of the IEEE international conference on computer vision, pages 2641–2649, 2015. ↩ ↩2
-
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014. ↩ ↩2
-
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Conghui He, Jiaqi Wang, Feng Zhao, and Dahua Lin. Sharegpt4v: Improving large multi-modal models with better captions. In European Conference on Computer Vision, pages 370–387. Springer, 2024. ↩ ↩2
-
Cheng-Yu Hsieh, Jieyu Zhang, Zixian Ma, Aniruddha Kembhavi, and Ranjay Krishna. Sugarcrepe: Fixing hackable benchmarks for vision-language compositionality. Advances in neural information processing systems, 36:31096–31116, 2023. ↩ ↩2
-
Yuze Zhao, Jintao Huang, Jinghan Hu, Xingjun Wang, Yunlin Mao, Daoze Zhang, Zeyinzi Jiang, Zhikai Wu, Baole Ai, Ang Wang, Wenmeng Zhou, and Yingda Chen. Swift:a scalable lightweight infrastructure for fine-tuning, 2024. ↩
-
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023. ↩