Cheng Zhang zhangcheng2122@mails.jlu.edu.cn Jilin UniversityChangchunChina, Hongxia Xie hongxiaxie@jlu.edu.cn Jilin UniversityChangchunChina, Bin Wen wenbin2122@mails.jlu.edu.cn Jilin UniversityChangchunChina, Songhan Zuo zuosh2122@mails.jlu.edu.cn Jilin UniversityChangchunChina, Ruoxuan Zhang zhangrx22@mails.jlu.edu.cn Jilin UniversityChangchunChina and Wen-Huang Cheng wenhuang@csie.ntu.edu.tw National Taiwan UniversityTaipeiTaiwan
Abstract.
With the rapid advancement of diffusion models, text-to-image generation has achieved significant progress in image resolution, detail fidelity, and semantic alignment, particularly with models like Stable Diffusion 3.5, Stable Diffusion XL, and FLUX.1. However, generating emotionally expressive and abstract artistic images remains a major challenge, largely due to the lack of large-scale, fine-grained emotional datasets. To address this gap, we present the EmoArt Dataset—one of the most comprehensive emotion-annotated art datasets to date. It contains 132,664 artworks across 56 painting styles (e.g., Impressionism, Expressionism, Abstract Art), offering rich stylistic and cultural diversity. Each image includes structured annotations: objective scene descriptions, five key visual attributes (brushwork, composition, color, line, light), binary arousal-valence labels, twelve emotion categories, and potential art therapy effects. Using EmoArt, we systematically evaluate popular text-to-image diffusion models for their ability to generate emotionally aligned images from text. Our work provides essential data and benchmarks for emotion-driven image synthesis and aims to advance fields such as affective computing, multimodal learning, and computational art, enabling applications in art therapy and creative design. The dataset and more details can be accessed via the following link:https://zhiliangzhang.github.io/EmoArt-130k/
Affective Computing, Computer Vision, Dataset, Multimedia, Artificial Intelligence

Figure 1. A Sample and Functional Modules of EmoArt. The figure illustrates the pipeline from input image to multi-level emotion and attribute analysis, as well as the system’s capability of learning visual styles such as brushstroke and composition.
Table 1. Comparison of Emotion-related Datasets, R represents Recognition, G represents Generation.
| Dataset | Image Type | Label Source | Tasks | Image | Category | Valence&Arousal | Attributes | Description |
|---|---|---|---|---|---|---|---|---|
| IAPSa 1 | Photo | Human | R | 395 | ✓ | ✓ | ✗ | ✗ |
| GAPED 2 | Photo | Human | R | 730 | ✓ | ✓ | ✗ | ✗ |
| ArtPhoto 3 | Art | Human | R | 806 | ✓ | ✗ | ✗ | ✗ |
| Emotion6 4 | Photo | Human | R | 1980 | ✓ | ✗ | ✗ | ✗ |
| FI 5 | Photo | Human | R | 23308 | ✓ | ✗ | ✗ | ✗ |
| WEBEmo 6 | Photo | Human | R | 268K | ✓ | ✗ | ✗ | ✗ |
| Artemis 7 | Art | Human | G&R | 80K | ✓ | ✗ | ✗ | ✓ |
| EmoSet 8 | Photo/Art | Human&LLM | G&R | 3300K | ✓ | ✗ | ✓ | ✗ |
| FindingEmo 9 | Photo | Human | R | 25K | ✓ | ✓ | ✗ | ✗ |
| EmoArt (Ours) | Art | Human&LLM | G&R | 130K | ✓ | ✓ | ✓ | ✓ |
1. Introduction
“The purpose of art is washing the dust of daily life off our souls.”
– Pablo Picasso
The rapid development of AI-generated content (AIGC), especially diffusion-based text-to-image models like the Stable Diffusion series 10, DALL·E 11, and Imagen 12, has enabled realistic and semantically rich image synthesis. However, effectively conveying complex emotional expression remains a major challenge 13.
Emotional intent is often faint, subjective, and context-dependent, making it difficult for generative models to interpret and reproduce with fidelity. Although real-world image synthesis has advanced, generating artistic images that convey complex emotions and deep affective meaning remains underexplored but essential, as art uniquely expresses complex emotions, culture, and therapeutic value beyond ordinary photos 14.
Existing emotion datasets such as AffectNet 15, EmoSet 8, and ArtEmis 7 are constrained by limited visual diversity, inconsistent labels, or insufficient support for multimodal emotion grounding. To fill this gap, we introduce EmoArt, a large-scale, multidimensional dataset designed to support both emotion understanding and generation in the artistic domain. EmoArt contains 132,664 paintings spanning 56 stylistic genres across a wide range of historical and cultural contexts, collected from The Met, WikiArt, and Europeana. Each image is annotated along three complementary dimensions: (1) content descriptions, (2) visual attributes, and (3) emotional and therapeutic effects.
Annotations are generated via a GPT–4o–assisted pipeline with human verification, ensuring high consistency. We further benchmark leading diffusion models on emotional alignment and visual coherence. EmoArt aims to advance affective computing and computational art, while supporting emotion-aware and well-being–oriented applications.
Our contributions are summarized as follows:
- We introduce EmoArt, a large-scale, richly annotated dataset for emotion-aware image analysis and generation, covering 132,664 artistic images across 56 styles and three emotion-relevant dimensions.
- We benchmark state-of-the-art diffusion models on emotional alignment, validating EmoArt as a robust testbed for affective AIGC research.
2. Comparison with Existing Emotion Datasets
Existing emotion datasets in computer vision and affective computing include early works like ArtPhoto 3 and AbstractPhoto 3 focusing on artistic images with discrete labels; VSO 16 and Twitter I/II 13 5 for social media sentiment; Emotion6 4, FI 5, T4SA 17, and WEBEmo 6 covering diverse online images; and ArtEmis 7, EmoSet 8, and FindingEmo 9 providing large-scale and complex emotion annotations.
As shown in Table 1, existing datasets mostly target real-world photos, have limited or coarse annotations, or low image quality. In contrast, our EmoArt dataset offers large-scale, rich, and structured annotations designed specifically for emotionally-aware image generation.
3. Construction of EmoArt
3.1. Data Collection and Filtering

Figure 2. Construction pipeline of the EmoArt dataset.
To construct the EmoArt dataset(see Figure 2), we collected over 200,000 artworks representing more than 150 artistic styles from publicly accessible sources. These include WikiArt, the Metropolitan Museum of Art, the National Museum of Asian Art, Japanese Print Search and Database, the National Palace Museum (Taiwan), and the National Museum of Korea. The dataset covers both Western and non-Western traditions, ensuring broad regional and stylistic diversity. All works were sourced from public domain or open-access platforms, allowing for legal use and academic reproducibility.
To guarantee the dataset’s quality, representativeness, and ethical usability, we applied four rigorous filtering steps:
- Art Form Filtering: Retained only paintings; excluded non-painting media such as sculpture, crafts, prints, and photography to focus on emotional expression in painted works.
- Content Safety Filtering: Combined automated image classification with manual review to remove NSFW (Not Safe For Work) or explicit content, including some kitsch or overly suggestive artworks.
- Image Quality Filtering: Discarded images below 300×300 pixels or with visible compression artifacts, occlusions, or watermarks to ensure visual clarity and stable model training.
- Category Balance Filtering: Removed underrepresented styles (fewer than 400 samples) to maintain balanced distribution and ensure statistical robustness in analysis.
Through this systematic and thorough curation process, we obtained a legally usable and representative dataset of raw images.
3.2. Data Annotation
To leverage recent advances in multimodal intelligence, we adopt GPT-4o 18 as the core annotation engine for the EmoArt dataset. With cutting-edge image understanding and affective modeling, GPT-4o interprets artistic images and produces structured annotations across visual and emotional dimensions. It processes image and text jointly, providing refined insights into visual semantics and simulating human-like emotional responses.
We design standardized prompt templates and implement a multi-round generation-verification pipeline to ensure annotation quality and consistency. Empirical comparisons with human-labeled samples confirm GPT-4o’s strong alignment, validating its scalability for annotation.
Compared to existing datasets, EmoArt adopts a more hierarchical and multi-dimensional annotation framework, capturing a spectrum from objective visual content to subjective emotion. Each image includes five key components:
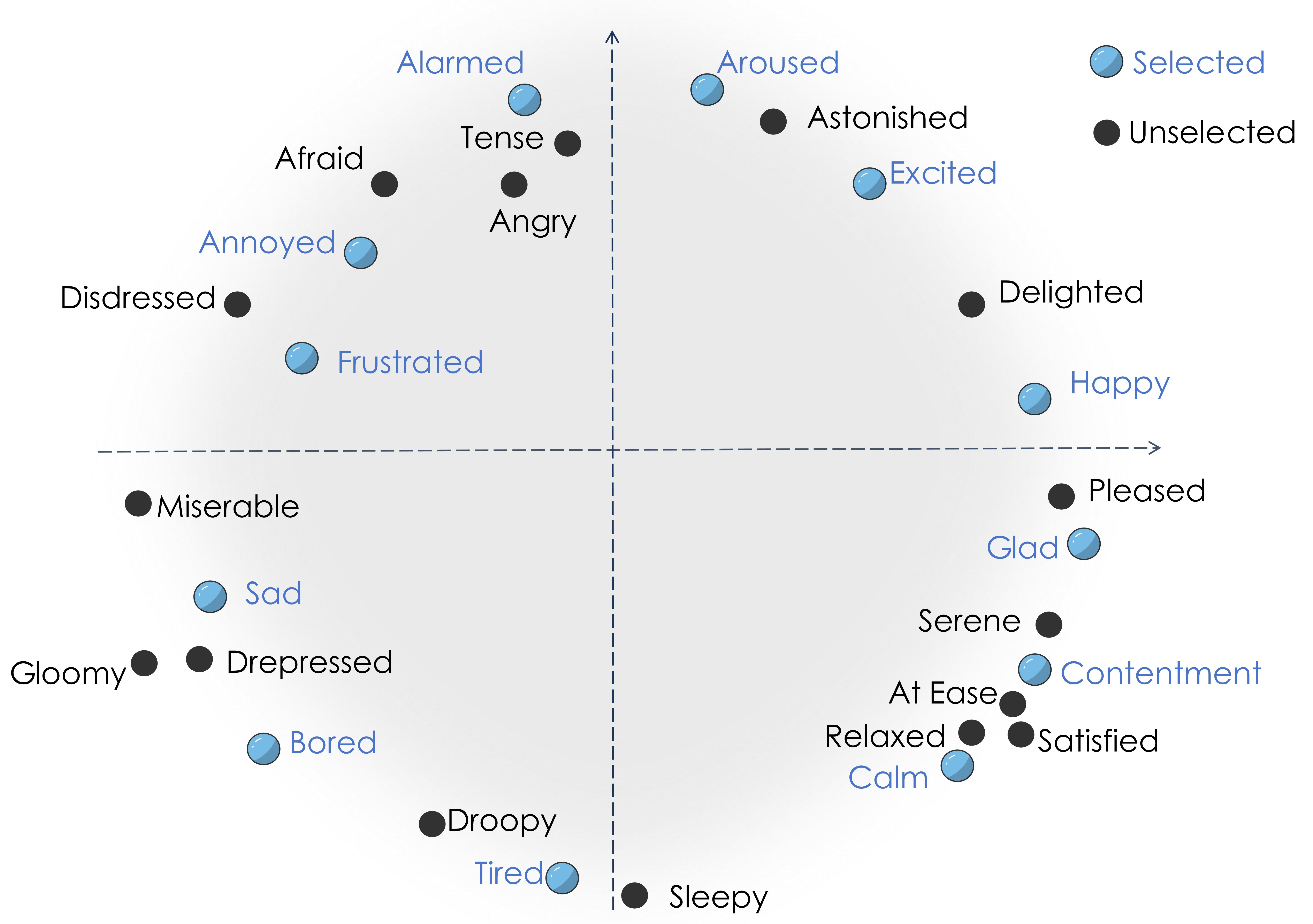
Figure 3. Distribution of 28 common emotions in the arousal-valence space and the selected 12 representative emotions.
This structured five-part annotation enables EmoArt to model the mapping from visual form to emotional perception to language generation with high fidelity.
Table 2. Annotation Agreement Metrics across Annotation Sections.
| Section | True Proportion | False Proportion | Percent Agreement | Positive Agreement | Gwet’s AC1 | McNemar p-value | Sample Size |
|---|---|---|---|---|---|---|---|
| Description | 98.01% | 1.99% | 94.25% | 96.83% | 0.928 | 0.38 | 5,922 |
| Visual Attributes | 98.56% | 1.44% | 95.25% | 97.87% | 0.944 | 0.29 | 5,922 |
| Emotion | 91.47% | 8.53% | 85.25% | 90.14% | 0.785 | 0.23 | 5,922 |
3.3. Human Validation
We conducted a large-scale human validation on 5,600 images from the EmoArt dataset, sampled across 56 artistic styles. Ten trained annotators independently assessed each image along three dimensions: Description, Visual Attributes, and Emotion.
As shown in Table 2, GPT-4o annotations showed high agreement with human labels: 98.01% (Description), 98.56% (Visual Attributes), and 91.47% (Emotion), indicating strong alignment even in subjective categories.
We also measured inter-annotator reliability using standard metrics: overall/positive agreement, Gwet’s AC1, and McNemar’s test. All metrics confirmed high consistency (agreement 85%, AC1 0.75, -values 0.05).
These results validate GPT-4o’s annotation quality and confirm EmoArt as a reliable benchmark for emotion-aware image generation.
4. Data Analysis
4.1. Distribution Analysis

Figure 4. Representative art categories in the dataset: the inner ring shows the major categories, and the outer ring shows the specific subcategories.
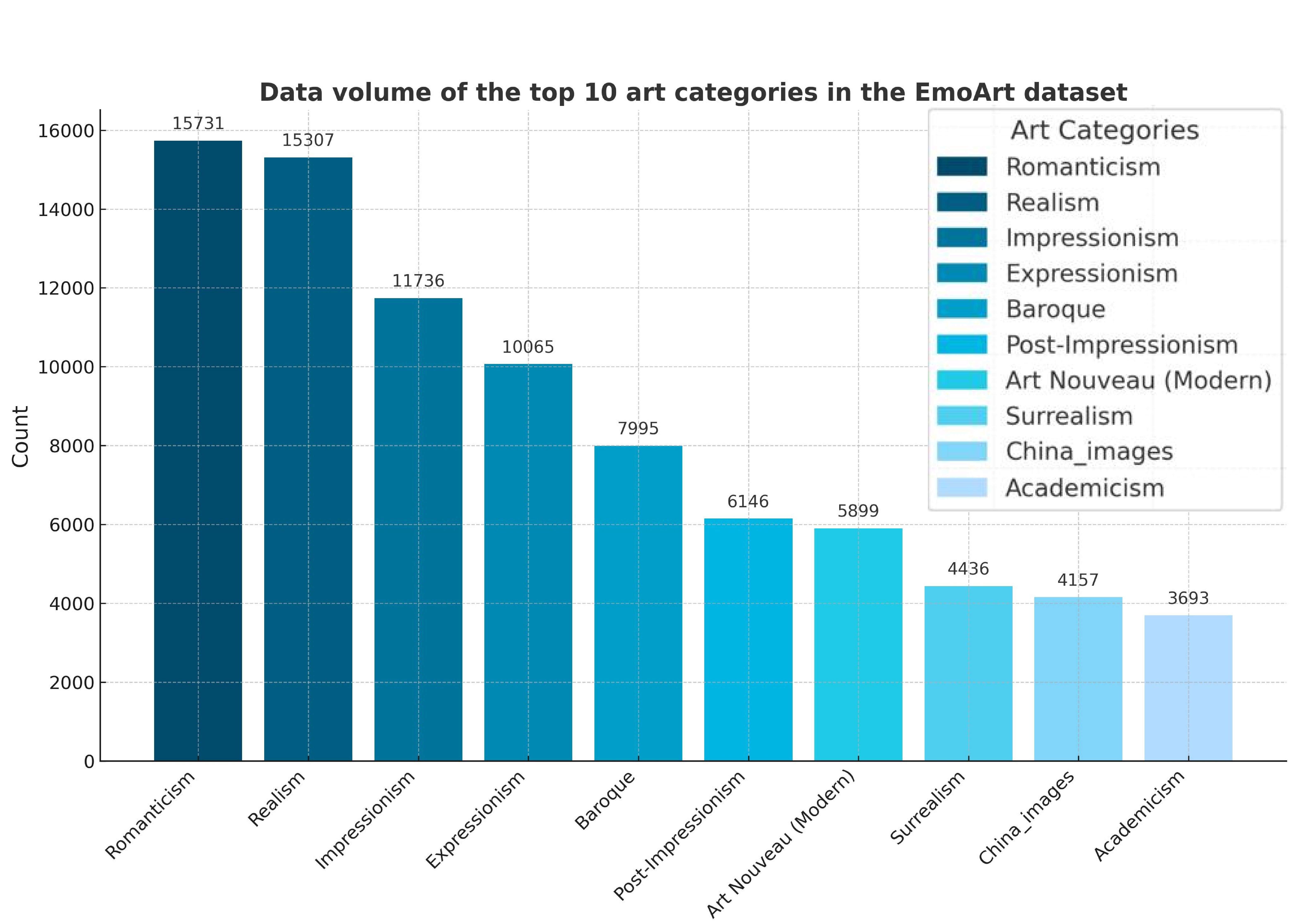
Figure 5. Data volume of the top 10 art categories in the EmoArt dataset.
The EmoArt dataset contains 132,664 samples spanning 56 painting styles across diverse historical periods and cultural contexts, from Early Renaissance to Neo-Pop Art. These styles are grouped into seven thematic domains—Classics, Modern Edge, East Spirit, Chromatic Soul, Dream Visions, Form & Flow, and Social Mirror—each reflecting distinct aesthetic and emotional characteristics. Representative samples are shown in Figure 4, while Figure 5 illustrates the top 10 style categories by image count.
Emotion statistics indicate a strong tendency toward positive valence (87.93%) and low arousal (76.41%), suggesting that most artworks evoke pleasant and calming emotions. The dominant labels are Calm (55.95%), Excited (15.50%), and Contentment (15.35%). Notably, low arousal + positive valence samples constitute 71.33% of the dataset, highlighting the prevalence of soothing and uplifting affect in artistic expression. High-arousal or negative emotions like Alarmed (4.07%) and Sad (4.38%) are comparatively rare.
Table 3. Language Diversity Metrics Comparison Across Datasets.
| Dataset | Average TTR | Average MTLD | Average Entropy | Average Word Count |
|---|---|---|---|---|
| Flickr30K | 0.9097 | 11.9349 | 3.3116 | 12.3392 |
| ArtEmis | 0.9182 | 15.3065 | 3.6680 | 15.8919 |
| COCO Cap. | 0.9065 | 10.1764 | 3.1567 | 10.4746 |
| EmoArt | 0.9358 | 16.3396 | 3.6722 | 16.2184 |
Table 4. Image Generation Model Performance Metrics (Bruchstr. and Compo. stand for Brushstroke and Composition, respectively).
| Model | Brushstr.↑ | Color↑ | Compo.↑ | Light↑ | Line↑ | Overall↑ | LPIPS↓ | SSIM↑ | PSNR↑ | FID↓ |
|---|---|---|---|---|---|---|---|---|---|---|
| FLUX.1-dev | 0.6058 | 0.6703 | 0.6228 | 0.6753 | 0.6216 | 0.6392 | 0.6706 | 0.2108 | 9.5708 | 21.2945 |
| FLUX.1-schnell | 0.5875 | 0.6610 | 0.6263 | 0.6761 | 0.6250 | 0.6352 | 0.6947 | 0.2179 | 9.0199 | 38.1792 |
| Playground | 0.6293 | 0.6788 | 0.6247 | 0.6749 | 0.6354 | 0.6486 | 0.6715 | 0.1947 | 9.6673 | 42.5694 |
| Pixart-sigma | 0.6358 | 0.6746 | 0.6342 | 0.6723 | 0.6356 | 0.6505 | 0.6754 | 0.1658 | 8.9910 | 36.2260 |
| SDXL | 0.5939 | 0.6703 | 0.6257 | 0.6717 | 0.6311 | 0.6385 | 0.7110 | 0.1677 | 9.1273 | 61.9343 |
| SD3.5 | 0.6211 | 0.6742 | 0.6324 | 0.6734 | 0.6317 | 0.6466 | 0.6991 | 0.1590 | 8.4539 | 37.9605 |
| Openjourney | 0.6128 | 0.6380 | 0.6140 | 0.6620 | 0.6304 | 0.6314 | 0.7188 | 0.1480 | 9.0728 | 62.2185 |
| FLUX.1-dev-finetuned | 0.6388 | 0.6974 | 0.6698 | 0.6542 | 0.6421 | 0.6604 | 0.6508 | 0.2102 | 9.6596 | 31.6510 |
Emotional profiles vary significantly across styles and thematic domains. For example, Realism (11.52%) and Romanticism (11.84%), typically associated with the Classics domain, are characterized by calm and peaceful emotions, with Calm accounting for 64.73% and 60.66% of their respective samples, and low-positive emotional combinations dominating (84.55% and 76.85%). In contrast, styles such as Expressionism (7.57%) and Surrealism (3.34%), under Modern Edge and Dream Visions respectively, display heightened emotional intensity, with high arousal present in over 36% of samples and notable proportions of negative affect (24.08% and 28.99%). These styles frequently evoke emotions like Alarmed (5.20% in Expressionism, 10.41% in Surrealism) and Sad (9.35% and 8.57%), reflecting their emphasis on inner turmoil and psychological depth.
Cultural variation is also pronounced. Within the East Spirit domain, traditional Chinese painting (China_images, 3.13%) overwhelmingly conveys calm and positive affective states, with 99.76% of samples exhibiting low arousal and 99.95% positive valence—Calm alone accounts for 89.42%. Similar patterns are found in Ukiyo-e (86.13% low arousal, 95.20% positive valence) and Gongbi (100% low arousal and positive valence), reflecting Eastern aesthetic ideals of harmony, balance, and serenity.
Conversely, the Social Mirror domain—including styles such as Social Realism and Socialist Realism—is marked by more intense and critical emotional content. These styles show significantly higher proportions of negative valence (42.53% and 25.09%, respectively) and elevated levels of Alarmed responses (18.06% and 9.82%), consistent with their focus on social critique and depictions of human struggle.
4.2. Linguistic analysis
To evaluate the linguistic diversity and expressive complexity of the image description texts in the EmoArt dataset, we selected four commonly used quantitative metrics: TTR (Type-Token Ratio), MTLD (Mean Textual Lexical Diversity), lexical entropy (Entropy), and average word count, comparing the results with multiple mainstream visual-text datasets. As shown in Table 3, EmoArt consistently outperforms others across all metrics. Specifically, EmoArt achieves a high TTR of 0.9358, an MTLD of 16.34, and a lexical entropy of 3.6722, indicating richer vocabulary and greater local variability. Its average word count of 16.22 further reflects more detailed and expressive descriptions than COCO Captions 19 and Flickr30K 20.
These results confirm that EmoArt provides superior linguistic richness and information density, making it a strong foundation for tasks such as sentiment analysis, vision-language modeling, and text generation.
5. Can AI Feel Art? Emotional Image Generation Benchmarks with EmoArt
We conducted a comprehensive evaluation of several state-of-the-art text-to-image diffusion models on our proposed EmoArt dataset.
5.1. Experimental Setup
We established baselines using seven state-of-the-art diffusion models: FLUX.1-dev 21, FLUX.1-schnell 21, SDXL 22, SD3.5 23, PixArt-sigma 24, Playground 25, and Openjourney 26.
To explore the effectiveness of EmoArt, we fine-tuned FLUX.1-dev using LoRA. The training used 50 curated paintings per artistic category, along with their Description, Arousal, and Valence annotations. Fine-tuning was conducted on a single NVIDIA A100 GPU, and evaluation followed the same metrics as the baseline.
We evaluated the quality of generated images using a comprehensive set of metrics:
- FID: Assesses distributional similarity between generated and real images via Inception features. Lower is better.
- SSIM: Measures structural and perceptual similarity. Ranges from 0 to 1, with higher values indicating better visual similarity.
- PSNR: Quantifies reconstruction quality using mean squared error. Higher values imply lower distortion.
- LPIPS: Estimates perceptual similarity using deep features; lower scores indicate better alignment with human perception.
- Attributes Alignment: Our proposed metric evaluates semantic fidelity to five artistic attributes. We fine-tune MiniCPM-V-2.6 on EmoArt and compute similarity to ground-truth text in the CLIP embedding space.

Figure 6. Results from multiple text-to-image diffusion models. The input prompt format is: Style + Arousal + Valence + Description.
5.2. Quantitative Analysis
Question 1: Which model performs best in subjective evaluation metrics?
Answer: FLUX.1-dev-finetuned outperforms all other models across the majority of subjective evaluation metrics, demonstrating a clear advantage in perceived image quality.
As summarized in Table 4, FLUX.1-dev-finetuned, trained with the proposed EmoArt dataset, achieves the highest scores in brushstroke (0.6388), color (0.6974), composition (0.6698), line quality (0.6421), and overall quality (0.6604), reflecting strong alignment with human aesthetic judgments. This performance boost over its base model FLUX.1-dev demonstrates the effectiveness of emotion-annotated fine-tuning in guiding stylistic and emotional rendering. The EmoArt dataset provides fine-grained supervision on visual elements and emotional intent, allowing the model to better internalize artistic patterns and generate images that resonate more deeply with viewers.
Interestingly, FLUX.1-schnell slightly outperforms FLUX.1-dev in light and shadow (0.6761 vs. 0.6753), suggesting that its training configuration is particularly effective in capturing lighting dynamics, possibly due to better low-level feature representation. Other models like Openjourney and SDXL exhibit moderate performance in overall quality (0.6314 and 0.6385), but struggle with consistent brushstroke or compositional control, likely due to limited exposure to artistic styles during training.
In general, these results indicate the importance of emotion-aware fine-tuning and structured artistic supervision in improving the subjective quality of generated images. Models trained with EmoArt not only achieve better emotional alignment but also exhibit enhanced stylistic authenticity.
Question 2: How do the models perform in attribute alignment, and what insights does it offer for evaluation?
Answer: FLUX.1-dev-finetuned achieves the best results across most Attributes Alignment metrics, revealing strong correlations between emotional dimensions and visual attributes, thereby supporting the validity of the EmoArt annotations.
Specifically, FLUX.1-dev-finetuned shows significant alignment between arousal and valence with core visual attributes such as brushstroke, color, light, composition, and line. This indicates that the images generated by this model more effectively reflect the intended emotional content, reinforcing the scientific reliability of the EmoArt framework.
Although FLUX.1-dev-finetuned does not achieve top performance in conventional evaluation metrics such as FID, PSNR, LPIPS, and SSIM, its near-optimal performance in Attributes Alignment highlights the strength of the proposed framework. These results suggest that traditional pixel-based metrics may not fully capture the perceptual and emotional quality of generated images, and that attribute evaluations can serve as a novel and complementary assessment perspective.
5.3. Qualitative Analysis
Question 3: How do the models differ in their ability to express emotion and artistic style in qualitative evaluations?
Answer: In qualitative evaluations, FLUX.1-dev-finetuned demonstrates a markedly superior capacity for emotional expression and stylistic fidelity across diverse artistic genres.
As illustrated in the first row of Figure 6, FLUX.1-dev-finetuned effectively employs pure blocks of blue and white to evoke a calming atmosphere, faithfully capturing the essence of Color Field Painting. In contrast, FLUX.1-dev and SDXL generate images that lack stylistic clarity, exhibiting visual clutter and compositional inconsistency.
In the second row, which focuses on traditional Chinese painting, FLUX.1-dev-finetuned adopts a minimalist, balanced composition and soft brushwork, conveying serenity and harmony aligned with East Asian aesthetics. Conversely, FLUX.1-dev, SDXL, and PixArt-sigma rely on more vivid colors and intricate layouts, which diminish the subtle emotional tone intrinsic to this genre.
The third row evaluates depictions of high-arousal, anxious emotions. Here, FLUX.1-dev-finetuned stands out with chaotic line work and asymmetric composition, effectively visualizing emotional intensity. While FLUX.1-dev, SDXL, and PixArt-sigma also utilize non-equilibrium layouts, their outputs reveal template-like patterns and limited diversity, resulting in a less compelling emotional impact.
6. Conclusion and License
EmoArt offers 132,664 systematically annotated artworks spanning 56 diverse artistic styles, enabling fine-grained analysis and generation of emotionally expressive visual content. It serves as a valuable and comprehensive resource for affective computing, computational creativity, and multimodal learning across various research and application domains. The dataset is publicly available under the CC BY-NC 4.0 license at https://huggingface.co/datasets/printblue/EmoArt-130k.
Footnotes
-
Joseph A Mikels, Barbara L Fredrickson, Gregory R Larkin, Casey M Lindberg, Sam J Maglio, and Patricia A Reuter-Lorenz. 2005. Emotional category data on images from the International Affective Picture System. Behavior research methods 37 (2005), 626–630. ↩
-
Elise S Dan-Glauser and Klaus R Scherer. 2011. The Geneva affective picture database (GAPED): a new 730-picture database focusing on valence and normative significance. Behavior research methods 43 (2011), 468–477. ↩
-
Jana Machajdik and Allan Hanbury. 2010. Affective image classification using features inspired by psychology and art theory. In Proceedings of the 18th ACM international conference on Multimedia. 83–92. ↩ ↩2 ↩3
-
Kuan-Chuan Peng, Tsuhan Chen, Amir Sadovnik, and Andrew C Gallagher. 2015. A mixed bag of emotions: Model, predict, and transfer emotion distributions. In Proceedings of the IEEE conference on computer vision and pattern recognition. 860–868. ↩ ↩2
-
Quanzeng You, Jiebo Luo, Hailin Jin, and Jianchao Yang. 2016. Building a large scale dataset for image emotion recognition: The fine print and the benchmark. In Proceedings of the AAAI conference on artificial intelligence, Vol. 30. ↩ ↩2 ↩3
-
Rameswar Panda, Jianming Zhang, Haoxiang Li, Joon-Young Lee, Xin Lu, and Amit K Roy-Chowdhury. 2018. Contemplating visual emotions: Understanding and overcoming dataset bias. In Proceedings of the European Conference on Computer Vision. 579–595. ↩ ↩2
-
Panos Achlioptas, Maks Ovsjanikov, Kilichbek Haydarov, Mohamed Elhoseiny, and Leonidas J Guibas. 2021. Artemis: Affective language for visual art. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11569–11579. ↩ ↩2 ↩3
-
Jingyuan Yang, Qirui Huang, Tingting Ding, Dani Lischinski, Danny Cohen-Or, and Hui Huang. 2023. Emoset: A large-scale visual emotion dataset with rich attributes. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 20383–20394. ↩ ↩2 ↩3
-
Laurent Mertens, Elahe Yargholi, Hans Op de Beeck, Jan Van den Stock, and Joost Vennekens. 2024. Findingemo: An image dataset for emotion recognition in the wild. Advances in Neural Information Processing Systems 37 (2024), 4956–4996. ↩ ↩2
-
Stability AI. 2022. Stable Diffusion v2.1 Model Card. https://huggingface.co/stabilityai/stable-diffusion-2-1. Accessed: 2025-05-28. ↩
-
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. 2021. Zero-shot text-to-image generation. In International conference on machine learning. Pmlr, 8821–8831. ↩
-
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. 2022. Photorealistic text-to-image diffusion models with deep language understanding. Advances in neural information processing systems 35 (2022), 36479–36494. ↩
-
Quanzeng You, Jiebo Luo, Hailin Jin, and Jianchao Yang. 2015. Robust image sentiment analysis using progressively trained and domain transferred deep networks. In Proceedings of the AAAI conference on Artificial Intelligence, Vol. 29. ↩ ↩2
-
Alireza Taheri and Batool Maazallahi. 2020. A Review of the Book How Can Art Change Your Life? Pizhuhish nāmah-i intiqādī-i mutūn va barnāmah hā-yi ̵̒ulūm-i insāni (Critical Studies in Texts & Programs of Human Sciences) 20, 6 (2020), 185–202. ↩
-
Ali Mollahosseini, Behzad Hasani, and Mohammad H Mahoor. 2017. Affectnet: A database for facial expression, valence, and arousal computing in the wild. IEEE Transactions on Affective Computing 10, 1 (2017), 18–31. ↩
-
Damian Borth, Rongrong Ji, Tao Chen, Thomas Breuel, and Shih-Fu Chang. 2013. Large-scale visual sentiment ontology and detectors using adjective noun pairs. In Proceedings of the 21st ACM international conference on Multimedia. 223–232. ↩
-
Lucia Vadicamo, Fabio Carrara, Andrea Cimino, Stefano Cresci, Felice Dell’Orletta, Fabrizio Falchi, and Maurizio Tesconi. 2017. Cross-media learning for image sentiment analysis in the wild. In Proceedings of the IEEE international conference on computer vision workshops. 308–317. ↩
-
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023). ↩
-
Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Dollár, and C Lawrence Zitnick. 2015. Microsoft coco captions: Data collection and evaluation server. arXiv preprint arXiv:1504.00325 (2015). ↩
-
Peter Young, Alice Lai, Micah Hodosh, and Julia Hockenmaier. 2014. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Transactions of the association for computational linguistics 2 (2014), 67–78. ↩
-
Black Forest Labs. 2024. Flux.1 AI. https://flux1ai.com/. Accessed: 2025-05-28. ↩ ↩2
-
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. 2023. Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952 (2023). ↩
-
Stability AI. 2024. Stable Diffusion 3.5 Large Model Card. https://huggingface.co/stabilityai/stable-diffusion-3.5-large. Accessed: 2025-05-28. ↩
-
Junsong Chen, Chongjian Ge, Enze Xie, Yue Wu, Lewei Yao, Xiaozhe Ren, Zhongdao Wang, Ping Luo, Huchuan Lu, and Zhenguo Li. 2024. Pixart- : Weak-to-strong training of diffusion transformer for 4k text-to-image generation. In European Conference on Computer Vision. Springer, 74–91. ↩
-
Daiqing Li, Aleks Kamko, Ehsan Akhgari, Ali Sabet, Linmiao Xu, and Suhail Doshi. 2024. Playground v2. 5: Three insights towards enhancing aesthetic quality in text-to-image generation. arXiv preprint arXiv:2402.17245 (2024). ↩
-
PromptHero. 2022. OpenJourney Model Card. https://huggingface.co/prompthero/openjourney. Accessed: 2025-05-28. ↩