一句话总结:Switch Transformer 对 MoE 的路由机制做了极简化——从 top-k 路由简化为 top-1(每次每个 token 只激活一个专家),并配套设计了容量因子(capacity factor)、选择性精度(selective precision)和 expert dropout 等训练稳定化技术,在相同计算预算下实现了相比 T5 最高 7 倍预训练加速,最终将模型扩展至 1.6 万亿参数。
Intro
Motivation
MoE 层通过让不同样本激活不同参数实现条件计算,理论上可以打破”参数越多计算越多”的瓶颈。然而 MoE 的广泛采用一直受限于三个问题:模型复杂度(多专家路由设计复杂)、通信成本(专家分布在多设备上的 all-to-all 通信)和训练不稳定(离散路由导致训练发散)。此前 MoE 论文甚至必须使用 float32 才能稳定训练。
核心贡献
- 提出 Switch Routing:将 top-k 路由简化为 top-1,在保证模型质量的同时大幅简化路由计算
- 设计 容量因子(Capacity Factor) 机制:为每个专家设定固定处理容量,通过缓冲处理路由不均衡
- 提出 选择性精度(Selective Precision):仅在路由函数内部使用 float32,其余保持 bfloat16,实现稳定训练且几乎不损失速度
- 引入 Expert Dropout:在 fine-tune 时增加专家层的 dropout 率,缓解过拟合
- 展示 蒸馏压缩:将稀疏大模型蒸馏到小稠密模型,压缩 99% 参数仍保留 28% 的质量提升
- 结合数据、模型和专家并行,训练出 1.6 万亿参数模型
Method 核心方法
架构对比:Dense vs MoE vs Switch
| 属性 | Dense Transformer | Sparsely-Gated MoE | Switch Transformer |
|---|---|---|---|
| FFN 每 token | 1 个 dense FFN | Top-K (K≥2) 专家 | Top-1 专家 |
| 路由计算 | 无 | Softmax + KeepTopK | Softmax + argmax |
| 每专家 batch | N/A | tokens/N × K | tokens/N(减半) |
| 负载均衡 | 无需 | Importance + Load loss | 单一辅助 loss |
| 通信量 | 无 all-to-all | all-to-all(K 路) | all-to-all(1 路) |
Switch Routing:从 Top-K 到 Top-1
原版 MoE 从 N 个专家中选择 top-k 个(k>1),Switch Transformer 简化为 top-1:
好处有三:(1) 路由计算量减半以上;(2) 每个专家的 batch size 减半,因为每个 token 只去一个专家;(3) 路由实现和通信成本都降低。
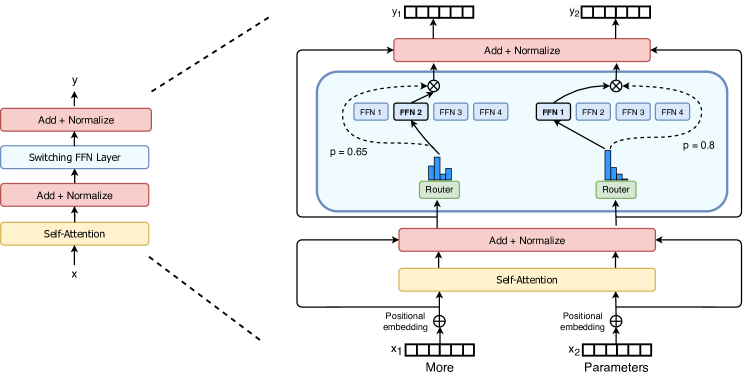
Figure 2: Switch Transformer encoder block 结构。将 Transformer 中的 dense FFN 替换为稀疏 Switch FFN 层(浅蓝色),router 为每个 token 独立选择一个 expert。
容量因子(Capacity Factor)
由于 TPU 需要静态确定 tensor 形状,每个专家需要预设容量:
容量因子 > 1.0 提供缓冲。当某专家过载(overflow),多余 token 通过残差连接直接跳至下一层。实验发现较低的 capacity factor(1.0-1.25)反而效果更好。
负载均衡 Loss
简化为单一辅助 loss:
其中 是分配给专家 i 的 token 比例, 是 router 概率分配比例。 在所有实验中效果良好。
选择性精度(Selective Precision)
只对 router 函数内部的局部计算使用 float32,路由产生的 dispatch/combine 张量转回 bfloat16 再进行 all-to-all 通信。这实现了接近 bfloat16 的速度和 float32 的稳定性。
Expert Dropout
Fine-tune 时在非专家层使用小 dropout(0.1),在专家 FFN 层使用大 dropout(0.4),有效防止了稀疏模型在小数据集上的过拟合。
混合数据+模型+专家并行
- 纯专家+数据并行:每个 core 负责一个专家和一部分数据,通过 all-to-all 通信交换 token
- 混合三者:,n 路数据并行,m 路模型并行,结合专家并行
实验/评估/结果
预训练加速(C4 Corpus)
| 模型 | 达到相同质量所需时间 |
|---|---|
| T5-Base | 基线 |
| Switch-Base(64专家) | 7x 加速 |
| Switch-Base vs T5-Large(3.5x FLOPs) | 2.5x 加速 |
- 固定计算预算下,专家数越多,模型质量越高(256 专家 14.7B 参数 model 远超 T5-Base 223M)
- 固定时间预算下,Switch Transformer 同样显著优于 dense 模型
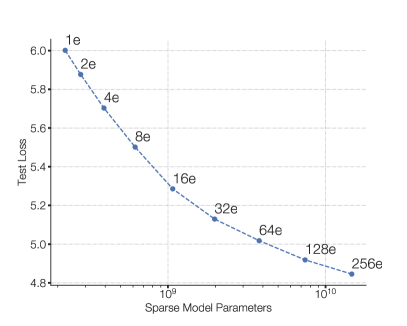
Figure 4: Switch Transformer 的缩放特性。左:固定 FLOPS/token 下增加专家数持续提升质量。右:Switch-Base 64 expert 达到 T5-Base 同等质量仅需 1/7 的训练步数。
下游 Fine-tune
- GLUE: Switch-Base 86.7 vs T5-Base 84.3
- SuperGLUE: Switch-Base 79.5 vs T5-Base 75.1(+4.4)
- SQuAD: Switch-Base 87.2 vs T5-Base 85.5
- Winogrande: Switch-Large 83.0 vs T5-Large 79.1
蒸馏压缩
- 将 14.7B 参数的 Switch 模型蒸馏到 223M T5-Base,保留 28% 的质量增益,压缩率 99%
- 蒸馏 fine-tuned SuperGLUE 模型:保留 30% 增益,压缩率 97%
多语言
- 在 101 种语言的 mC4 上,所有 101 种语言均获得提升
- 91% 语言实现 4x+ 加速
万亿参数级
- Switch-C:1.6T 参数,2048 专家(仅专家并行),训练稳定
- Switch-XXL:395B 参数,64 专家,相比 T5-XXL 4x 预训练加速
- 知识类任务(TriviaQA, NQ)上已超越 T5-XXL,推理类任务仍有提升空间
结论
Switch Transformer 通过极简化路由(top-1)、训练稳定化技术(选择性精度、容量因子、expert dropout)和混合并行策略,将 MoE 从”可行但困难”变成”简单且高效”。稀疏模型在 speed-accuracy Pareto 曲线上持续优于稠密模型。
思考
优点
-
极简主义方法论:从 top-k 到 top-1 是最核心的简化,证明”少即是多”。这篇论文的核心哲学是:把 MoE 中一切不必要的复杂度砍掉,反而得到更好的结果。
-
工程细节的诚实披露:选择性精度、小初始化、expert dropout 这些看似小的工程改进,对实际训练至关重要。论文没有掩盖这些”不优雅”的工程技巧,反而详细记录,极具实践价值。
-
蒸馏的前瞻性:早在 2021 年就探索了稀疏大模型到稠密小模型的蒸馏,展示了压缩 99% 参数仍保留 ~30% 增益的可行性。这个思路在后来 DeepSeek-R1 的蒸馏工作中被发扬光大。
-
多语言验证的完整性:在 101 种语言上全部获得提升,证明 MoE 不是只在英语上有效的 trick。
缺点与局限性
-
top-1 路由丢失了专家组合的能力:原版 MoE 的 top-k 路由允许不同专家的知识组合,Switch 的 top-1 放弃了这种组合能力。虽然后续的 DeepSeekMoE 通过细粒度专家+共享专家部分恢复了组合能力,但 Switch 的设计本质上是”专业化”而非”组合”。
-
容量因子是硬截断:overflow 的 token 直接跳过专家处理,这是一个粗糙的工程妥协。附录中提出的 No-Token-Left-Behind 方案并未带来收益,说明这个问题的解决远比想象复杂。
-
训练稳定性仍未彻底解决:Switch-XXL 仍有不稳定问题,选择性精度和小初始化只是缓解而非根治。后来的 DeepSeek-V2/V3 采用了 Aux-Loss-Free 负载均衡等更优雅的方案。
-
基于 T5(Encoder-Decoder)而非 Decoder-only:论文发表于 2021 年,彼时 GPT 系列还未完全主导。现代 LLM 普遍采用 decoder-only 架构,Switch Transformer 的并行设计需要适配。
-
下游 fine-tune 收益不及预训练:预训练的加速比(7x)未完全转化为下游任务的优势。论文也坦诚地讨论了上游困惑度与下游效果的脱节,这在后来的 MoE 工作中仍然是开放问题。