一句话总结:Qwen3 将”思考模式”(长链推理)和”非思考模式”(快速响应)统一到单一模型中,并引入思考预算(Thinking Budget)机制让用户通过 token 预算控制推理深度。提供 0.6B 到 235B 的稠密和 MoE 模型,预训练 36T tokens 覆盖 119 种语言,后训练通过四阶段流程(冷启动 + 推理 RL + 模式融合 + 通用 RL)和强到弱蒸馏实现开源 SOTA。
Intro
Motivation
现有 LLM 生态存在一个分裂:像 GPT-4o 这样的通用聊天模型擅长快速响应,但在复杂推理上不够强;像 o1/o3 和 QwQ 这样的推理模型擅长深度思考,但推理延迟高且不适合简单任务。用户需要在不同模型间切换。
Qwen3 的目标:在一个模型中统一思考和非思考两种模式,用户可通过 chat template 或 thinking budget 自由控制。
核心创新
- Thinking/Non-Thinking Mode Fusion:单一模型同时支持两种模式,通过
/think和/no_think标志切换 - Thinking Budget:用户可通过限制思考 token 数来控制推理深度——模型在达到预算时自动停止思考并给出当前最佳答案
- Strong-to-Weak Distillation:利用大模型知识(logit 级蒸馏)高效训练小模型,仅需 1/10 GPU 时
- 119 种语言支持:预训练 36T tokens,语言数从 Qwen2.5 的 29 扩展到 119
- Dense + MoE 双架构:从 0.6B 到 235B(MoE 22B 激活)完整覆盖
Method 核心方法
Qwen3 的方法论核心是”thinking/non-thinking 双模统一”——通过四阶段后训练将推理和通用能力融合到单一模型中,并通过 Thinking Budget 实现推理时计算控制。
模型家族
| 版本 | 类型 | 总参数 | 激活参数 | 专家数 |
|---|---|---|---|---|
| Qwen3-0.6B | Dense | 0.6B | 0.6B | - |
| Qwen3-1.7B | Dense | 1.7B | 1.7B | - |
| Qwen3-4B | Dense | 4B | 4B | - |
| Qwen3-8B | Dense | 8B | 8B | - |
| Qwen3-14B | Dense | 14B | 14B | - |
| Qwen3-32B | Dense | 32B | 32B | - |
| Qwen3-30B-A3B | MoE | 30B | 3B | 128 |
| Qwen3-235B-A22B | MoE | 235B | 22B | 128 |
与 Qwen2.5-MoE 不同:128 专家 / 8 激活、细粒度专家分割、不使用共享专家。Dense 版本新增 QK-Norm、移除 QKV-bias。
预训练三阶段
| 阶段 | Tokens | 长度 | 重点 |
|---|---|---|---|
| S1 General | 30T | 4096 | 119 种语言打基础 |
| S2 Reasoning | ~5T | 4096 | STEM/编程/推理/合成数据 |
| S3 Long Context | 数百 B | 32768 | ABF + YaRN + Dual Chunk Attention |
Dense 模型:与 Qwen2.5 类似(GQA + SwiGLU + RoPE + RMSNorm),新增 QK-Norm 提升训练稳定性,移除 QKV-bias。
MoE 模型:128 专家 / 8 激活专家,细粒度专家分割(fine-grained expert segmentation),不使用共享专家(与 Qwen2.5-MoE 不同),采用全局批负载均衡 loss。
预训练(三阶段)
- General Stage(S1):30T tokens @ 4096 长度,覆盖 119 种语言,打基础
- Reasoning Stage(S2):~5T 高质量 tokens @ 4096 长度,提高 STEM/编程/推理/合成数据比例
- Long Context Stage:数百 B tokens @ 32768 长度,配合 ABF(RoPE base 频率从 10k 到 1M)、YaRN、Dual Chunk Attention 实现推理时 4x 长度扩展
39T 预训练数据中,通过 Qwen2.5-VL 从 PDF 提取文本、Qwen2.5-Math/Coder 生成合成数据,大幅扩充。
后训练(四阶段)
旗舰模型(235B)的四阶段流程:
-
Long-CoT Cold Start(冷启动 SFT):QwQ-32B 生成候选 + 严格过滤(>6 项过滤规则),最小化样本量和步数,仅建立基础推理模式框架
-
Reasoning RL(推理强化学习):3,995 对 query-verifier,GRPO 算法,大 batch size + 高 rollout 数 + off-policy 训练,控制模型熵稳定增长以平衡探索和利用。AIME’24 从 70.1 提升至 85.1(170 步)
-
Thinking Mode Fusion(模式融合 SFT):
- Thinking 数据:用 Stage 2 模型在 Stage 1 查询上做拒绝采样
- Non-Thinking 数据:编程、数学、指令遵循、多语言、创意写作、问答等
- 通过 chat template 中的
/think和/no_think标志控制模式 - 默认 thinking 模式;non-thinking 样本保留空思考块以保持格式一致性
-
General RL(通用 RL):全场景数据,对齐有用性和安全性
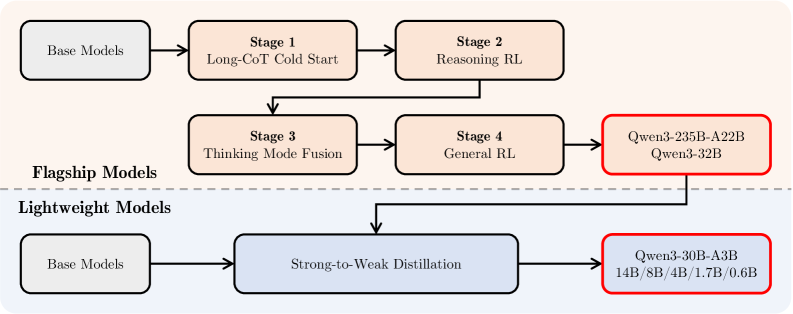
Figure 1: Qwen3 旗舰模型的后训练四阶段 pipeline——冷启动 SFT → 推理 RL → 模式融合 SFT → 通用 RL,将 thinking 和 non-thinking 统一到单一模型中。
Thinking Budget 机制
模式融合后,模型自然获得处理”中间状态”的能力——用户可设定思考 token 上限,达到时自动插入 stop-thinking 指令:
Considering the limited time by the user, I have to give the solution based on the thinking directly now.\n</think>
模型随即基于当前累积推理给出答案。这一能力完全涌现,无需显式训练。
Strong-to-Weak Distillation
小型模型(0.6B-32B)通过 logit 级蒸馏从大模型学习,而非重复完整的四阶段流程。效果:(1) Pass@1 更高;(2) Pass@64 更高(探索能力更强);(3) 仅需 1/10 GPU 时。
实验/评估/结果
Base Model 关键结论
- Qwen3-235B-A22B(MoE, 22B 激活)在 14/15 基准上超越 DeepSeek-V3-Base(37B 激活),总参数仅为 1/3
- Qwen3-32B(Dense)在 10/15 基准上超越 Qwen2.5-72B(不到一半参数)
- Qwen3-30B-A3B(MoE, 3B 激活)以 1/5 激活参数显著超越 Qwen2.5-14B
- 同规模 dense 模型的 STEM/编程/推理能力大幅超越 Qwen2.5
Post-Trained 旗舰模型(代表性结果)
| Benchmark | Qwen3-235B-A22B |
|---|---|
| AIME’24 | 85.7 |
| AIME’25 | 81.5 |
| LiveCodeBench v5 | 70.7 |
| Codeforces | 2,056 |
| BFCL v3 | 70.8 |
| MATH-500 | 超越 DeepSeek-V3 和 GPT-4o |
Thinking Budget 效果
增大思考 token 预算持续提升性能,验证了推理时计算扩展(inference-time compute scaling)的有效性。
蒸馏模型性能
小型 Qwen3 模型通过强到弱蒸馏,在同参数级别达到 SOTA,尤其在编程和数学推理上显著超越同规模 Qwen2.5。
结论
Qwen3 通过模式融合(thinking + non-thinking 统一)和思考预算机制提供了一种优雅的用户控制推理方案。强到弱蒸馏大幅降低了小模型的后训练成本。预训练的规模和覆盖面(36T tokens, 119 种语言)以及后训练的四阶段设计共同支撑了开源 SOTA 性能。
思考
优点
-
模式融合的工程优雅性:将 thinking/non-thinking 统一到单一模型,比”部署两个模型 + 路由”的方案优雅得多。chat template 级别的控制方案对开发者友好,且为 thinking budget 提供了实现基础。
-
Thinking Budget 的涌现特性:模型在没有显式训练”中途停止思考”的情况下自然获得了这个能力——这说明模式融合 SFT 阶段使用含空思考块的 non-thinking 数据和完整的 thinking 数据交替训练,实际上教会了模型”思考过程的任意前缀 + 直接给出答案”的泛化能力。这是一个精细的训练动力学设计。
-
Strong-to-Weak Distillation 的价值定位:明确展示 logit 级蒸馏(1/10 GPU 时)优于完整四阶段训练,为小模型的工业化生产提供了清晰的成本-质量取舍。
-
数据工程的系统化:从 PDF OCR(Qwen2.5-VL)到领域合成(Math/Coder),从多维度标注(30T+ tokens)到实例级数据混合优化,Qwen3 的数据管线体现了工业级 LLM 开发的成熟度。
-
全面开源:Apache 2.0 协议下开源 0.6B-235B 全系列,是目前最完整的开源 LLM 家族之一。
缺点与局限性
-
技术报告而非研究论文:作为技术报告,Qwen3 的叙述更偏向”我们做了什么”而非”为什么这样做有效”。关键的消融实验(如 QK-Norm 的作用、移除共享专家的影响、不同冷启动数据量的对比)严重缺失。
-
Thinking Budget 的评估不充分:虽然声称 thinking budget 有效,但论文只给出了趋势图而非详细的 benchmark 数值。用户在实际使用中如何选择最优预算、不同任务类型的最优预算差异等关键问题未得到回答。
-
模式融合的消融缺失:thinking/non-thinking 统一是否损害了各自模式的最优性能?如果分别训练两个专用模型,thinking 和 non-thinking 的性能是否会更好?这个 trade-off 未量化。
-
与 DeepSeek-R1 的方法论对比不足:GRPO 在 Qwen3 中的应用与 DeepSeek-R1 高度相似(都使用 GRPO、冷启动、拒绝采样、多阶段),但论文未讨论具体差异。这可能是因为技术报告的性质决定了它更关注”产品特性”而非”方法论贡献”。
-
119 种语言的评估代表性:虽然声称支持 119 种语言,但多语言评估仅依赖 MGSM、MMMLU、INCLUDE 三个基准,远不足以覆盖低资源语言的实际使用质量。