一句话总结:这篇是 MoE(Mixture-of-Experts)在现代深度学习中的奠基之作。提出了 Sparsely-Gated MoE 层——包含数千个专家前馈网络,通过可训练的门控网络为每个样本稀疏选择部分专家进行计算——在 10 亿词语言模型和机器翻译任务上以极低的计算代价实现了超过 1000 倍的模型容量提升,最终扩展至 1370 亿参数。
Intro
Motivation
深度学习的成功在很大程度上依赖于模型规模和训练数据量的扩展。但传统密集模型中所有参数对每个样本都激活,导致训练成本随模型规模平方增长。条件计算(Conditional Computation) 在理论上可以通过让网络的一部分按样本选择性激活来打破这个瓶颈,但在实践中一直未能成功——主要面临 GPU 分支效率低、批大小缩小、网络带宽瓶颈、负载不均衡和训练信号不足等挑战。
核心贡献
- 首次在深度网络中大规模实现条件计算:在 10 亿词 LM 上将模型容量提升 1000+ 倍,同时保持较低的计算开销
- 提出 Noisy Top-K Gating 机制:稀疏门控的可微训练方案
- 设计 负载均衡 策略:通过辅助 loss(importance loss + load loss)防止门控坍缩到少数专家
- 分层 MoE(Hierarchical MoE):两层门控进一步扩展专家数量
- 解决工程挑战:混合数据并行+模型并行、利用卷积性提升批大小
Method 核心方法
Sparsely-Gated MoE 层架构
MoE 层由 个专家网络 和一个门控网络 组成。对于输入 ,输出为:
当 时不需要计算 ,实现计算稀疏性。
专家是结构相同但参数独立的前馈网络(单隐藏层 ReLU)。在语言模型中,MoE 层以卷积方式嵌入 LSTM 层之间——对序列中每个位置独立路由到不同专家。
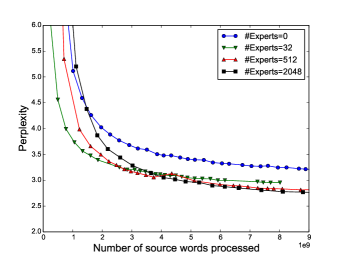
Figure 1: 嵌入在循环语言模型中的 MoE 层。稀疏门控函数为每个 token 选择 2 个专家进行计算,专家输出通过门控权重加权。
Noisy Top-K Gating
门控分为三步:
- 计算 logits:
- KeepTopK:只保留 top-k 值,其余设为 (Softmax 后为 0)
- Softmax 归一化
噪声项对负载均衡至关重要——它为门控引入随机性,使得负载均衡 loss 的梯度能够有效传播。 通常取 2-4。
负载均衡(Balancing Expert Utilization)
门控容易坍缩到总是选择同几个专家——这会导致那些专家被训练得更好,进一步拉大差距,形成恶性循环。
论文提出两个辅助 loss:
- :基于门控值的平方变异系数(CV),鼓励所有专家有相等的总权重
- :基于平滑估计的每个专家接收的样本数,鼓励相等的负载分布
分层 MoE(Hierarchical MoE)
当专家数量极大时,分两层门控:一层主门控选择 a 个”专家组”,每组内二次门控选择 b 个专家。每层 top-k=2,共激活 4 个专家。这降低了门控计算的分支因子。
工程优化
- 混合数据并行+模型并行:标准层和门控网络用数据并行,专家分布在模型并行设备上。 个设备时专家批大小扩大 倍
- 利用卷积性:将序列中所有时间步的 MoE 计算合并为一个大 batch
- 计算/通信比:通过增大专家隐藏层大小来提升计算和通信的比值
实验/评估/结果
10 亿词语语言模型(1 Billion Word LM Benchmark)
- 在固定计算预算(~8M ops/timestep)下:
- 4-expert MoE:perplexity 45.0(baseline)
- 4096-expert MoE:perplexity 34.1,降低 24%
- 高计算预算版本:4371M 参数,ops/timestep=142.7M,perplexity 28.0(vs 最佳发表结果 30.6)
1000 亿词语新闻语料(100B Word Google News Corpus)
- 扩展到 65536 专家(680 亿参数):perplexity 降低 39%(vs 计算匹配的 dense baseline)
- 在 131072 专家时出现退化,可能是过于稀疏导致
- 即使 99.994% 层稀疏性,计算效率仍保持 0.72 TFLOPS/GPU
机器翻译
- WMT’14 En→Fr:BLEU 40.56(vs GNMT 39.22,且训练时间更短)
- WMT’14 En→De:BLEU 26.03(vs GNMT 24.91)
- 多语言翻译:MoE 在 12 个语言对中的 11 对上超越多语言 GNMT,8 对上超越单语言 GNMT
专家专业化分析
专家确实按语法和语义分化——例如有专家专门处理含”plays a core/critical/leading role”的动词短语,另一个专门处理时序修饰语。
结论
首次在深度学习中实现大规模条件计算的实际收益。Sparsely-Gated MoE 使得模型容量可以扩展到数千亿参数,而计算成本仅温和增加。这为后来的 Switch Transformer、GShard、GPT-4 的 MoE 架构、DeepSeek-V2/V3 等所有现代稀疏模型奠定了基础。
思考
优点
-
开创性工作:这篇论文几乎定义了现代 MoE 的全部核心组件——Noisy Top-K Gating、负载均衡 loss、分层 MoE、混合并行策略。后来的 Switch Transformer、GShard、DeepSeekMoE 等都在这个框架上演进。
-
工程与算法的完美结合:不仅提出了算法创新(噪声门控、负载均衡 loss),还解决了实际部署的关键工程问题(批大小缩小、网络带宽、混合并行)。这种从原理到系统的穿透力在深度学习论文中罕见。
-
规模化验证:在 10 亿词和 1000 亿词两个规模上验证,证明 MoE 的优势随数据量和模型规模增长而扩大。这种多尺度实验设计值得借鉴。
-
专家可解释性:附录中展示了专家确实按语言学特征分化(如语义角色、句法结构),为 MoE 的”为什么有效”提供了直观理解。
缺点与局限性
-
架构过时:基于 LSTM 而非 Transformer。论文发表于 2017 年,在 Transformer 成为主流的背景下,LSTM 的 MoE 设计有其时代局限性。后来 Switch Transformer(2021)才将 MoE 引入 Transformer。
-
门控计算开销:Top-K 门控需要对所有 个专家打分(),当 上万时开销不可忽略。Switch Transformer 后来通过简化到 top-1 路由缓解了这个问题。
-
负载均衡 loss 是脆弱的:论文使用手工调节的系数(, ),这个超参数在不同设置下需要仔细调优。没有负载均衡 loss 时模型完全坍缩。
-
离散路由的梯度问题:KeepTopK 操作在非 top-k 位置产生零梯度,阻碍了那些专家的学习。论文依靠噪声和辅助 loss 间接缓解,但没有彻底解决。
-
训练不稳定:论文提到需要用 float32 精度(而非 bfloat16)来训练 MoE 层,否则会发散。这个稳定性问题在后来的工作中(Switch Transformer 的 selective precision)才得到更好的解决。