一句话总结:Magic-MM-Embedding 提出了一种基于视觉 token 压缩的高效 MLLM 通用多模态嵌入模型,通过将视觉 token 减少 75%(双线性插值)配合三阶段渐进训练策略(生成恢复 → 对比预训练 → MLLM-as-a-Judge 精调),在 MMEB 和 VisDoc 等 benchmark 上以更少的推理延迟实现了新的 SOTA。
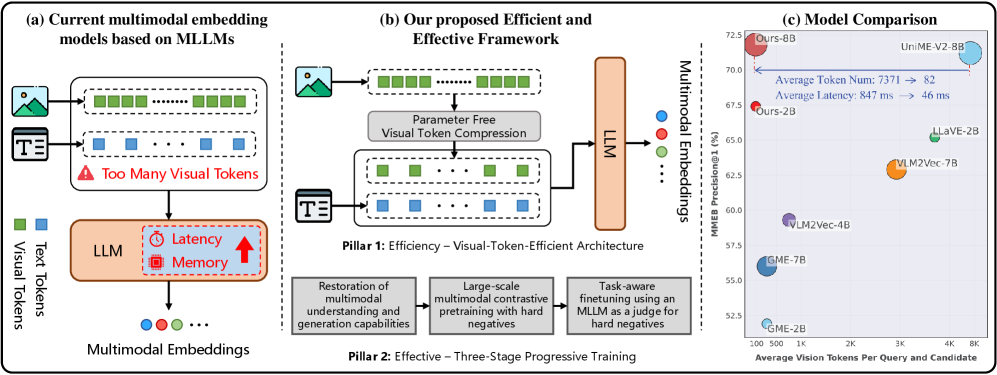
Figure 1: 打破 MLLM 嵌入模型的效率-性能 trade-off。(a) 标准 MLLM 嵌入器因处理冗余密集视觉 token 序列而产生高计算成本。(b) 提出视觉 token 压缩 + 三阶段渐进训练。(c) 在 MMEB 上以更少视觉 token 和更低延迟达到新 SOTA。
Intro
Motivation
CLIP 式双塔架构缺乏深度跨模态交互能力,MLLM 式嵌入模型虽强但面临严重瓶颈:标准架构将 ViT 输出的全部 patch token 直接注入 LLM,导致推理延迟和显存消耗随视觉 token 数量二次增长。对检索任务而言,目标是蒸馏多模态信息到 [EOS] token,大量冗余视觉 token 的贡献很小,效率问题亟待解决。
贡献
- 提出视觉 token 压缩架构 InternVL3-VTC:用无参数双线性插值将视觉 token 减少 75%,大幅降低推理延迟和显存
- 三阶段渐进训练策略:生成恢复→对比预训练(含全局 hard negative mining)→ MLLM-as-a-Judge 精调
- 训练了协同 reranker(pointwise+listwise),构建完整的 Embedder+Reranker 检索系统
- 在 MMEB(36 项任务)、VisDoc(24 项任务)和跨模态检索上均达到新 SOTA,仅用 25% 的视觉 token
Method 核心方法
1. 参数无关的视觉 Token 压缩
核心问题:标准 MLLM 将 ViT 输出的全量 patch token(如 InternVL 对 448² 图像产生 1024 个 token)注入 LLM,检索场景下大量 token 是冗余的。
方案:在 ViT 和 connector 之间插入双线性空间下采样 ,将 H×W 特征图空间维度各缩减 2 倍 → token 从 N 降至 N/4(75% 压缩)。
优势:参数无关(避免 learnable abstractor 的优化困难)、保留空间布局语义完整性。
嵌入提取:压缩后的 token + 文本 token → LLM → 取最后一个 token 的 L2 归一化隐藏态作为嵌入 ,用 InfoNCE 训练。
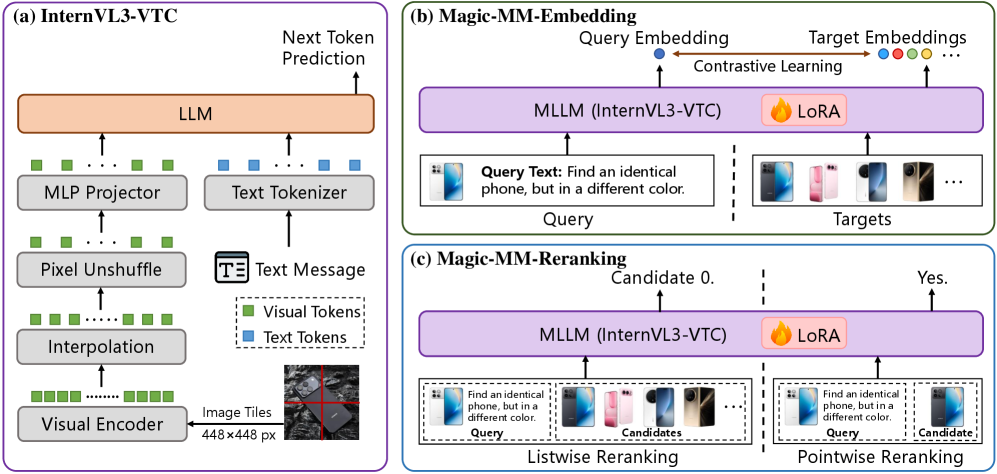
Figure 2: 高效通用多模态检索架构概览——(a) InternVL3-VTC:在 ViT 和 LLM 之间插入视觉 token 压缩模块,将视觉 token 减少 75%;(b-c) 基于 InternVL3-VTC 构建的高效通用多模态 Embedder 和 Reranker。
2. 三阶段渐进训练
Stage 1:多模态基础能力恢复
- 目标:重对齐压缩后的视觉特征与 LLM 语义空间
- 32M 多模态 instruct 数据,用 NTP loss 做生成训练
- 恢复基础理解和生成能力后再进入嵌入学习
Stage 2:多模态对比预训练
- 16M 检索样本(单模态/跨模态/融合模态)
- Warm-up 阶段:标准 InfoNCE + in-batch negatives
- Global Hard Negative Mining:从整个数据集中为每个 query 检索 hard negatives(位置 50-100,避免 top 中的 false negative)
Stage 3:MLLM-as-a-Judge 任务感知精调
- 用 Stage 2 模型检索 top-20 候选 → Qwen3-VL 判断相关性
- 扩展正样本集(发现未标注的 true positives)+ 构造高质量 hard negatives
- 1.5M 高质量多任务样本,插入 12 个 hard negatives
3. 协同 Reranker
- 基于 Stage 1 checkpoint 训练
- 联合 pointwise(Yes/No 判断)+ listwise(位置索引预测)训练
- 使用 Stage 3 的 judge-curated 数据进行训练
- 推理时:Embedder top-5 候选 → pointwise reranker 精排
4. 骨干和设置
- 骨干:InternVL3-VTC(1.9B / 8.1B)
- 48x NVIDIA A800 训练,Stage 2/3 使用 LoRA(rank=16)
- 图像 tiling:自然图像 MAX_NUM=1,视觉文档 MAX_NUM=4
实验/评估/结果
MMEB 通用多模态检索
在 36 个子任务上:
- 1.9B 版本:E 68.0 / E+R 70.2,超越 UniME-V2(67.4)
- 8.1B 版本:E 71.8 / E+R 72.8,超越 QQMM(70.7)、UniME-V2(71.2)
VisDoc 视觉文档检索
在 24 个子任务上:
- 1.9B:E 72.1 / E+R 73.3
- 8.1B:E 75.0 / E+R 75.8,超越 GME(75.2)
- 压缩 75% 视觉 token 后仍 SOTA,挑战了”细粒度检索需要高冗余 token”的假设
跨模态检索
在 Flickr30K/MSCOCO/ShareGPT4V/Urban1K/SugarCrepe 上全面 SOTA。SugarCrepe 上 2B 版本大幅领先 UniME-V2(91.6/82.6/94.2 vs 70.9/51.2/70.2)。
推理效率
- 2B 模型:MMEB query 延迟从 LLaVE 的 162.8ms 降至 29.9ms
- VisDoc candidate 延迟从 GME 的 153.8ms 降至 57.3ms
- 训练效率:2 epoch 从 53h 降至 23h(56% 加速),显存降低使 batch size 可增大
消融实验
- Warm-Up → +Global-HNM → +MLLM-Judge-FT → +Reranker:MMEB 从 62.9→65.4→68.0→70.2
- MLLM-based HN 始终优于 Rule-based HN
- 最优 hard negatives 数量:12 个
- 最优 LoRA rank:16
结论
Magic-MM-Embedding 证明:视觉 token 压缩不是性能 trade-off,而是策略性优势。通过三阶段渐进训练,压缩后的模型在 MMEB 和 VisDoc 上全面超越未压缩的竞争对手。这为大规模、延迟敏感的检索系统部署 MLLM 嵌入模型提供了可行路径。
思考
优点
-
问题定义精准:准确识别了 MLLM 嵌入模型的效率瓶颈——视觉 token 冗余。此前所有 MLLM 嵌入工作都在追逐性能而忽视了推理成本,这篇首次系统性地解决了效率问题。
-
三阶段训练设计精巧:Stage 1 生成恢复确保压缩不影响基础能力,Stage 2 建立判别力,Stage 3 用 MLLM-as-a-Judge 进行高质量数据筛选。各阶段目标明确,效果可累加。
-
无参数压缩方案的实用主义:双线性插值比 learnable abstractor 更简单、更稳定、更高效。这种”够用就好”的工程选择值得赞赏。
-
训练效率的提升:2 epoch 从 53h 降至 23h,不仅推理更快,训练也更快——这对工业部署非常关键。
缺点与待解决问题
-
压缩比的极限未探索:仅测试了 4x 压缩(25% token),更高的压缩比(如 8x、16x)的性能退化曲线未知。
-
无参数压缩可能不是最优:双线性插值对所有图像使用统一的压缩策略,可能丢失细粒度文档中的关键文字信息。可学习压缩可能在高压缩比场景更有优势。
-
与 GME 的差距来源未充分分析:在 VisDoc 上,standalone embedder 落后 GME,归因于”训练数据量差异”,但未做数据规模消融来验证。
-
MLLM-as-a-Judge 的成本:Stage 3 需要 Qwen3-VL 为每个 query-candidate 对做判断,这可能成为训练管线中的瓶颈。