一句话总结:Kimi K2 是月之暗面发布的 1T 参数(32B 激活)MoE 开源模型,提出 MuonClip 优化器实现 15.5T tokens 零 loss spike 预训练,通过大规模 agentic 数据合成 pipeline 和 RL(RLVR + self-critique rubric reward)在 SWE-bench Verified 65.8、tau2-Bench 66.1 等 agentic benchmark 上达到开源 SOTA。
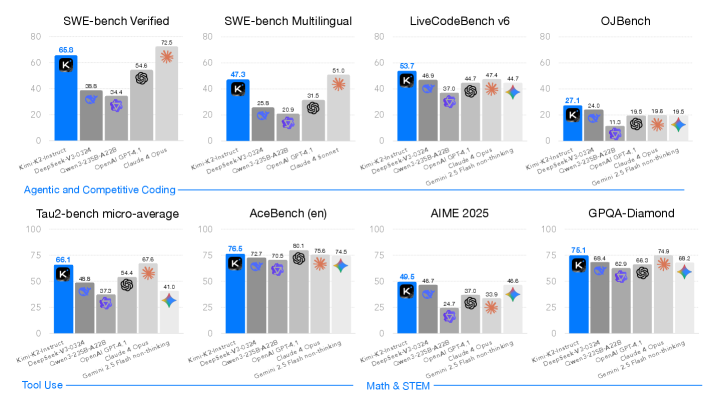
Figure 1: Kimi K2 主结果,非思考模式下的对比。
Intro
Motivation
LLM 正从静态模仿学习转向 Agentic Intelligence——自主感知、规划、推理并在复杂环境中行动。实现这一转变面临两大挑战:
- 预训练 token 效率:高质量数据供给有限,每 token 的学习信号密度成为关键缩放系数
- 后训练 agentic 能力:多步推理、长期规划、工具使用在自然数据中稀缺,需要大规模合成 agentic 轨迹 + RL
贡献
- MuonClip 优化器:集成 Muon 的高 token 效率与 QK-Clip(注意力 logit 权重裁剪)的稳定性
- 大规模 agentic 数据合成 pipeline:生成数千工具、代理和任务,通过模拟环境 + 真实沙箱生成多样化 tool-use 演示
- 统一 RL 框架:结合可验证奖励(RLVR)与 self-critique rubric reward,覆盖从数学推理到开放域对话
Method 核心方法
1. 预训练:MuonClip + Rephrasing + 超稀疏 MoE
Kimi K2 的核心主张是 token efficiency——在高质量人类数据日益稀缺的约束下,最大化每个训练 token 的学习信号。
MuonClip 优化器:Muon [Keller et al.] 比 AdamW token 效率更高(相同计算预算下 Muon 显著优于 AdamW),但大规模训练中注意力 logit 容易爆炸。现有缓解策略不足:logit soft-cap 在前向截断但点积仍可过度增长;QK-Norm 不适用于 MLA(Key 矩阵在推理时未完全物化)。
QK-Clip 机制:对每个 attention head h,定义 max logit 。当 超过阈值 时,对投影权重做 per-head 缩放:
对 MLA 架构单独处理: 和 各缩 , 缩 ,共享的 不修改(避免跨头效应)。MuonClip = Muon + weight decay + consistent RMS + QK-Clip,全程 15.5T tokens 无 loss spike。
数据重写(Rephrasing):
| 领域 | 方法 | 效果 |
|---|---|---|
| 知识数据 | chunk-wise 自回归重写 + 保真度验证 | 10x rewrite → SimpleQA 28.94(vs 原始 10 epoch 23.76) |
| 数学数据 | ”学习笔记”风格重写 + 多语言翻译 | 提升 token 的信息密度 |
超稀疏 MoE 架构:
- 1.04T 总参数 / 32.6B 激活,384 experts(激活 8 个,sparsity 48)
- 61 层、64 attention heads(比 DeepSeek-V3 的 128 减半以降低长上下文推理开销)
- 基于 DeepSeek-V3 的 MLA + MoE 架构
Sparsity Scaling Law:固定激活专家数(8 个),增加总专家数→sparsity 8→48,相同 FLOPs 下 loss 持续下降。sparsity 48 相比 sparsity 8 在相同 val loss 下 FLOPs 减少 1.69x。
训练配置:15.5T tokens,MuonClip + WSD 学习率调度(前 10T constant LR 2e-4,后 5.5T cosine decay 至 2e-5),结尾 annealing + 32K long-context activation(400B tokens),YaRN 扩展到 128K。
2. 后训练
大规模 Agentic 数据合成:
- 三个阶段:Tool spec 生成 → Agent + Task 生成 → Multi-turn Trajectory 生成
- 工具来源:3,000+ 真实 MCP 工具(GitHub)+ 20,000+ 合成工具(领域演化生成)
- 生成数千 agent、Rubric-based 任务和轨迹
- 真实沙箱(Kubernetes)执行代码和 SWE 任务,提供真值反馈
- 质量过滤:LLM judge 评估轨迹,仅保留成功案例
RL 框架:
- RLVR Gym:数学/STEM(diverse coverage + moderate difficulty)、逻辑推理、编码/SWE(真实 GitHub PR/issues)、安全(对抗攻击 pipeline)
- Self-Critique Rubric Reward:以 K2 actor 生成 > K2 critic 配对评估 > 闭环 critic 精炼,将可验证 RL 信号蒸馏为判断能力
- PTX Loss:高质量数据的辅助损失,防止灾难性遗忘
- Temperature Decay:探索期高温度 → 后期衰减,收敛高质量输出
RL 基础设施:
- 训练和推理引擎 co-located
- 分布式 checkpoint engine 实现 < 30 秒全参数更新
- 支持长轨迹的 partial rollout 和并发 rollouts
实验/评估/结果
Post-training 主结果
| Benchmark | Kimi-K2-Instruct | DeepSeek-V3-0324 | Claude Opus 4 | GPT-4.1 |
|---|---|---|---|---|
| SWE-bench Verified (Agentic) | 65.8 | 38.8 | 72.5 | 54.6 |
| SWE-bench Multilingual | 47.3 | 25.8 | 51.0 | 31.5 |
| LiveCodeBench v6 | 53.7 | 46.9 | 47.4 | 44.7 |
| AIME 2025 (Avg@64) | 49.5 | 46.7 | 33.9 | 37.0 |
| GPQA-Diamond (Avg@8) | 75.1 | 68.4 | 74.9 | 66.3 |
| tau2-Bench (avg) | 66.1 | 46.9 | 64.9 | 56.0 |
| ACEBench | 76.5 | 72.7 | 75.6 | 80.1 |
| Tau2 telecom | 65.8 | 32.5 | 57.0 | 38.6 |
| IFEval | 89.8 | 81.1 | 87.4 | 88.0 |
| SimpleQA | 31.0 | 27.7 | 22.8 | 42.3 |
- LMSYS Arena:开源第 1、总榜第 5(3,000+ 投票)
- 工具调用:tau2-Bench telecom 65.8(远超 DS-V3 的 32.5)
- SWE-bench multi-attempt: 71.6
Base 模型
- MMLU 87.79、MMLU-Pro 69.17、SimpleQA 35.25(全面超越 DeepSeek-V3-Base)
- EvalPlus 80.33(vs V3 的 65.61)
结论
Kimi K2 通过 MuonClip + agentic 数据合成 + 统一 RL 框架,在 agentic 能力上建立开源 SOTA。但复杂推理任务上 token 消耗较大,单次 prompt 构建完整软件项目的成功率仍不如 agentic coding framework。
思考
优点
- MuonClip 的工程价值高:QK-Clip 思路简洁(per-head logit cap → weight rescale),解决了 Muon 在大规模上的训练不稳定问题
- Agentic 数据合成 pipeline 是完整的方法论:从工具合成到 agent 生成到轨迹生成 + 质量过滤,可规模化复用
- RLVR + self-critique 的双轨 RL 框架设计合理:可验证任务用 outcome reward,开放任务用 self-critique,闭环 critic 精炼是关键创新
- Sparsity Scaling Law 研究:证明增加 sparsity(384 个 experts)持续提升性能
- 诚意开源:发布 base 和 post-trained checkpoint
缺点
- 对 DeepSeek-V3 的架构依赖度高:MLA + MoE 设计与 V3 几乎相同,主要创新在优化器和数据侧
- Self-critique reward 的主观性风险:模型既是 actor 又是 critic,可能存在自我偏差放大
- SWE-bench 与 Claude 的差距仍明显:65.8 vs 72.5/72.7,且多语言差距更大(47.3 vs 51.0)
- Agent 推理效率问题:论文自己指出复杂推理或工具定义不清晰时 token 消耗过大
- 安全性评估不全面:主要在红队测试层面,缺乏系统性的安全对齐分析