一句话总结:DINO 在 DETR 系列的基础上提出了三项关键改进——对比去噪训练(CDN)、混合查询选择(Mixed Query Selection)和 Look Forward Twice 框预测——使 DETR 类模型首次在 COCO 上超越经典 CNN 检测器达到 SOTA(63.3 AP test-dev),且仅需 12 个 epoch 训练即可达到 49.4 AP。
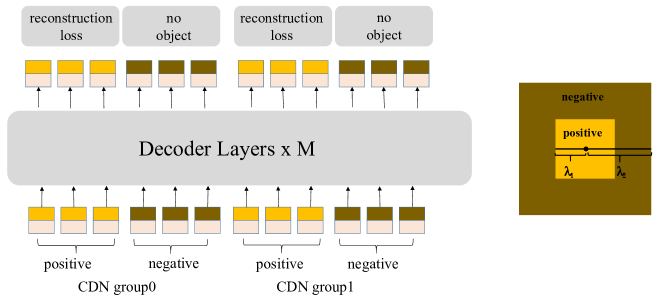
Figure 1: 对比去噪训练(CDN)机制示意图——为每个 GT 框同时生成正样本查询(噪声较小,应重建 GT 框)和负样本查询(噪声较大,应预测为背景)。正负样本的对比使模型学会区分”近处锚框”(要选)和”远处锚框”(要拒绝),有效抑制了 DETR 类模型的重复预测问题。
Intro
Motivation
DETR(Detection Transformer)开创了基于 Transformer 的端到端目标检测范式,消除了 NMS、anchor 设计等手工组件。然而:
- 训练收敛慢:DETR 需要 500 个 epoch 才能收敛,而 Faster R-CNN 只需 12-36 个 epoch
- 性能不及经典检测器:即使经过 DAB-DETR 和 DN-DETR 的改进,DETR 类模型在 COCO 上仍未超过 50 AP
- 可扩展性未经验证:没有 DETR 类模型在大规模主干网络和大数据集上的结果
核心主张
通过改进 DETR 类模型的三个关键组件,DINO 可以在训练效率、检测精度和可扩展性上全面超越经典检测器:
- 对比去噪训练(CDN):不仅提供正样本锚框(去噪目标),还提供负样本锚框(需拒绝的背景),解决重复预测和锚框混淆问题
- 混合查询选择(Mixed Query Selection):使用编码器输出初始化位置查询,但保持内容查询为可学习参数
- Look Forward Twice(LFT):利用后层细化后的框信息改善前层框预测的梯度更新
贡献
- 提出 DINO,DETR 类模型首次在 COCO 上达到 SOTA(63.3 AP test-dev)
- 对比去噪训练(CDN)有效抑制重复预测,对小物体 AP 提升尤其显著
- 仅用公开数据集(ImageNet-22K + Objects365)和较小模型(218M 参数)超越 Florence(637M+)、SwinV2-G(3B)等超大模型
- 证明端到端 Transformer 检测器在性能和效率上可以全面超越经典 CNN 检测器
Method 核心方法
DINO 在 DN-DETR 和 Deformable DETR 的基础上引入了三个关键改进:对比去噪训练(CDN)、混合查询选择和 Look Forward Twice,将 DETR 系列从”慢但有效”推进到”快且 SOTA”。
1. 对比去噪训练(CDN)
DN-DETR 仅使用正样本噪声查询(“从噪声锚框恢复真实框”),缺少拒绝不可行锚框的能力。
CDN 创新——正负样本对比:为每个 GT 框生成两类查询,按噪声大小区分:
- 正样本(噪声 < λ₁):噪声较小,应重建 GT 框
- 负样本(噪声 λ₁~λ₂):噪声较大无法恢复,应预测”无物体”(背景)
每个 CDN group 含 n 个正样本 + n 个负样本(n=GT 数量),使用多个 CDN group 提升鲁棒性。
效果分析:
| 问题 | CDN 如何解决 |
|---|---|
| 重复预测 | 负样本教会”拒绝远处锚框”,减少多锚框竞争同一 GT |
| 小物体检测 | 更好的锚框选择 → +7.5 AP_S(对小物体定位精度关键) |
| 训练效率 | ATD 指标证实 CDN 锚框更接近 GT,减少无用探索 |
2. 混合查询选择
DETR 解码器查询由两部分组成:位置部分(定位)和内容部分(语义)。
三种查询初始化策略对比:
| 策略 | 位置查询 | 内容查询 | 问题 |
|---|---|---|---|
| 静态(DETR/DN-DETR) | 可学习 | 全 0 | 无空间先验,收敛慢 |
| 纯查询选择(Deformable DETR) | Encoder 特征 | Encoder 特征 | 内容特征未经细化,含噪声混淆 |
| 混合(DINO) | Encoder 位置 | 可学习参数 | 取两者之长 |
核心洞察:Encoder 输出的内容特征是”未经细化”的初步特征——可能多物体混淆、信息不完整,直接用作内容查询会误导解码器。但位置信息(“哪里有物体”)已经可靠。因此分离处理:用可靠的位置信息初始化→好的空间先验;保持内容查询可学习→解码器自己学”什么是物体”。
3. Look Forward Twice(LFT)
Deformable DETR 使用标准辅助损失——每层独立优化(梯度从层 i 到层 i-1 被 detach),前层无法利用后层更准确的信息。
LFT:层 i 的参数同时受第 i 层和第 i+1 层的损失影响——后层的精细框信息可以**“反向”指导前层学习更好的初始框。实现:,其中 来自层 i-1 的未 detach** 版本(梯度流贯通两层)。
4. 模型总览
| 组件 | 配置 | 说明 |
|---|---|---|
| 主干 | ResNet-50/SwinL | 多尺度特征(4-5 尺度),含 FPN |
| 编码器 | Deformable Transformer Encoder | 多尺度可变形注意力增强特征 |
| 解码器 | Deformable Transformer Decoder | 900 查询 = 300 基础 × 3 任务模式 + CDN 查询 |
| 锚框 | 动态锚框 | 每层解码器逐步细化坐标 |
| 匹配 | 匈牙利匹配 | 二分图匹配(训练)+ Top-K 置信度(推理) |
实验/评估/结果
COCO 12-epoch 训练(ResNet-50)
| 模型 | AP | AP_S | AP_M | AP_L |
|---|---|---|---|---|
| Faster R-CNN | 37.9 | 22.4 | 41.1 | 49.1 |
| Deformable DETR | 41.1 | - | - | - |
| DN-Deformable-DETR | 43.4 | 24.8 | 46.8 | 59.4 |
| DINO-4scale | 49.0 (+5.6) | 32.0 (+7.2) | 52.3 | 63.0 |
| DINO-5scale | 49.4 (+6.0) | 32.3 (+7.5) | 52.5 | 63.9 |
仅 12 个 epoch,DINO 以大幅优势超越所有已有 DETR 类模型,小物体 AP 提升尤为突出。
COCO 更长训练(ResNet-50)
| 模型 | Epochs | AP |
|---|---|---|
| DN-Deformable-DETR | 50 | 48.6 |
| DINO-4scale | 24 | 50.4 (+1.8) |
| DINO-5scale | 24 | 51.3 (+2.7) |
24 epochs 即超越 DN-DETR 50 epochs 的结果。
SOTA 对比(SwinL + Objects365 预训练)
| 模型 | Params | Backbone 预训练 | 检测预训练 | AP test-dev |
|---|---|---|---|---|
| SwinV2-G (HTC++) | 3.0B | IN-22K-ext-70M | O365 | 63.1 |
| Florence-CoSwin-H | 637M+ | FLD-900M | FLD-9M | 62.4 |
| DINO-SwinL (ours) | 218M | IN-22K-14M | O365 | 63.3 |
DINO 以更少的参数(1/15 of SwinV2-G)、更小的预训练数据(1/60 of Florence),达到了更高的 AP。这是首次端到端 Transformer 检测器登顶 COCO 排行榜。
消融实验(逐步叠加三个改进)
| 模型 | AP |
|---|---|
| Optimized DN-DETR | 44.9 |
| + Pure Query Selection | 46.5 |
| → Mixed Query Selection | 47.0 (+0.5) |
| → + Look Forward Twice | 47.4 (+0.4) |
| → + Contrastive DN (DINO) | 47.9 (+0.5) |
三个改进各自贡献约 0.5 AP,且相互促进。
收敛速度
DINO 在 12 epoch 处的 AP 超过 DN-DETR 在 50 epoch 处的 AP,收敛曲线全面占优。
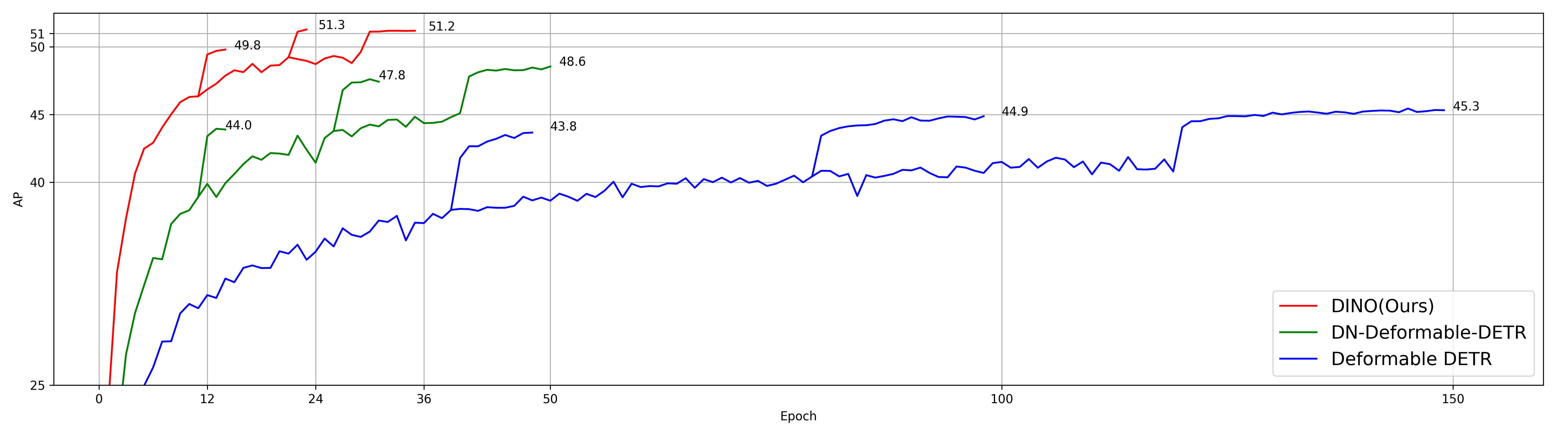
Figure 2: DINO 与先前 DETR 类模型的收敛速度对比——DINO (4-scale) 在 12 epochs 处的 AP 即超过 DN-Deformable-DETR 50 epochs 的结果,收敛速度提升约 4 倍。三条改进(Mixed Query Selection、LFT、CDN)各自贡献了稳定的性能提升。

Figure 3: COCO 12-epoch 训练结果对比(ResNet-50 主干)——DINO 以 49.0 AP(4-scale)和 49.4 AP(5-scale)大幅超越所有已有 DETR 变体,尤其在小物体 AP(AP_S)上以约 7 个点的优势证明了 CDN 去噪机制对小物体的特殊作用。
结论
DINO 通过三个精心设计的改进——对比去噪训练、混合查询选择和 Look Forward Twice——使 DETR 类模型在训练效率和最终性能上全面超越经典 CNN 检测器。DINO 首次将端到端 Transformer 检测器确立为 COCO 的 SOTA,标志着目标检测领域的主流方法从 CNN 向 Transformer 的范式转移。
思考
优点
-
三个改进的设计质量都很高:CDN 解决重复预测、Mixed Query Selection 解决内容查询的误导、LFT 解决梯度隔离问题。每个改进都针对一个明确诊断出的瓶颈,做到了”精准手术”而不是”大杂烩”。
-
CDN 的理论洞察:正负样本对比的思想不仅在实验上有效,在理论上也合理——教会模型”什么是近处锚框(要选)v.s. 远处锚框(要拒绝)“是解决 DETR 二分匹配不稳定的根本方法。
-
混合查询选择的 subtle 设计:仅用位置、不用内容——这个看似微小的差异背后是对”编码器输出还不够成熟”的深刻理解。简单的 ablation 证明了纯查询选择中的内容信息确实会误导解码器。
-
开源和真实 SOTA:DINO 是第一个在 COCO 排行榜上登顶的端到端 Transformer 检测器,而且用的是公开可复现的数据和模型,对比 Florence/SwinV2-G 的非公开数据优势明显。
-
12-epoch 的结果意义重大:在工业场景中,训练速度直接决定迭代效率。DINO 12 epoch = DN-DETR 50 epoch,这是巨大的工程红利。
缺点与待解决问题
-
NMS-free 但不完全端到端:虽然去掉了 NMS,但训练中仍有二分匹配(Hungarian matching)这一离散步骤。这是 DETR 类方法的结构性约束,DINO 没有突破。
-
可变形注意力的依赖性:DINO 仍依赖可变形注意力(Deformable Attention)的计算效率,这是一种视觉特定的算子——从追求通用架构的角度,不是最理想的。
-
对小物体的改进主要来自 CDN:如果去掉 CDN,DINO 对小物体的检测是否还能保持优势?缺少对所有三个改进在小物体维度上的分解 ablation。
-
大模型训练的计算成本:SwinL + Objects365 预训练 + COCO 微调,虽然参数少,但训练时间仍然可观(64 GPU 预训练 26 epochs + 16 GPU 微调 18 epochs)。
与已有 Wiki 的连接
- 关联概念:目标检测、DETR、端到端检测器、二分匹配、可变形注意力、去噪训练
- 关联实体:DAB-DETR、DN-DETR、Deformable DETR、Swin Transformer
- 关联论文:YOLO、Swin Transformer
- 关联比较:DETR 类模型演进 DETR → DAB → DN → DINO
- 关联比较:单阶段 vs 两阶段目标检测器