一句话总结:本文提出了 Chain-of-Thought(CoT)prompting 方法,通过在 few-shot 示例中插入中间推理步骤序列,引导大语言模型在回答前先进行逐步推理,从而在算术、常识和符号推理等复杂任务上显著提升性能。这篇论文是后续所有推理增强方法(ToT、GoT、o1、R1 等)的奠基之作。
Intro
Motivation
大语言模型在 scaling 后展现出强大的 few-shot 能力,但在需要多步推理的任务(如数学文字题、常识推理、符号推理)上仍表现不佳。标准的 input-output prompting 直接将问题映射到答案,缺乏中间推理过程。
核心思想
CoT prompting 的核心思想是在 few-shot 示例的 <输入, 输出> 对之间插入一系列自然语言形式的中间推理步骤(即思维链),引导模型在生成最终答案前先”展示推理过程”。这利用了语言模型自回归生成的特点——模型生成的推理 token 会影响后续 token 的分布,从而实现逐步推理。
贡献
- 提出 Chain-of-Thought prompting,一种简单而通用的推理增强方法
- 实验证明 CoT 在算术推理(GSM8K:从 ~18% 提升到 ~57% solve rate)、常识推理(StrategyQA、Date Understanding、Sports Understanding)和符号推理(最后字母拼接、硬币翻转)上均显著优于标准 prompting
- 证明 CoT 的效果与模型规模正相关——仅在足够大的模型(~100B 参数)上才能体现优势,小模型上 CoT 可能与标准 prompting 持平或更差
- 提供了 CoT 推理链的分析,展示了模型确实在执行有意义的中间推理而非简单模式匹配
Method 核心方法
Chain-of-Thought Prompting
CoT prompting 本质上是 few-shot prompting 的变体。标准的 few-shot 范式为:
CoT 将其替换为:
思维链是一系列自然语言句子,描述从输入到输出的中间推理步骤。例如对于数学文字题,思维链包含逐步的方程推导;对于常识推理,思维链包含背景知识调用和逻辑演绎。
实现方式
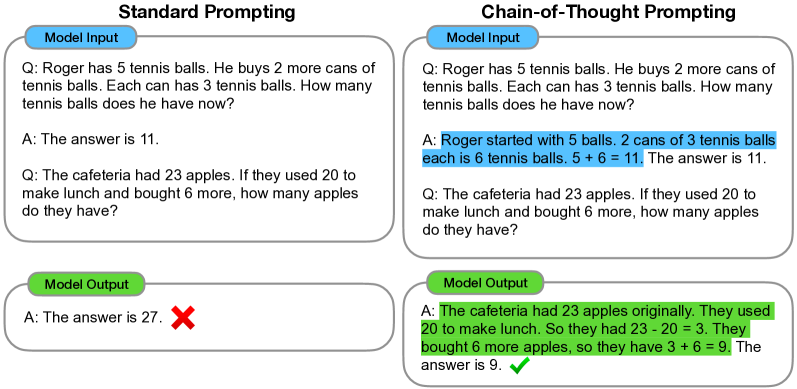
Figure 1: Chain-of-thought prompting 标准 prompting(左)与 CoT prompting(右)的对比。标准 prompting 直接从输入映射到输出,CoT 在中间插入推理步骤。
CoT 的实验设置极为简洁:
- 人工为每个任务手写 8 个左右包含推理链的 few-shot 示例
- 将这些示例拼接在测试问题前作为 prompt
- 让模型在测试问题后生成推理链和最终答案
与后来基于 RL 训练的方法(如 o1、R1)不同,CoT 不需要对模型进行任何训练或微调,完全通过推理时的 prompt 设计来激发模型的推理能力。
为什么有效?
论文给出了几个直觉性解释:
- 推理链将多步问题分解为中间步骤,每一步只需要较小的推理跳跃
- 生成推理链的过程提供了额外的计算——更多 token = 更多思考时间
- 推理链本质上是将隐式知识外化——模型在预训练中已经学到了推理模式,CoT prompting 只是激活了这些能力
实验/评估/结果
算术推理
在 GSM8K(小学数学文字题)上:
- LaMDA 137B + CoT 达到 ~57% solve rate,远超标准 prompting 的 ~18%
- PaLM 540B + CoT 达到 ~58%,结合外部计算器进一步提升
- 在 MultiArith、ASDiv、SVAMP 等多个算术基准上一致提升
关键发现:CoT 的优势只在模型规模足够大(~100B 参数级别)时才显现。在小模型上(如 8B、62B),CoT 反而可能降低性能。这说明推理能力是一种涌现能力。

Figure 4: CoT prompting 的效果与模型规模的关系。仅在足够大的模型(~100B 参数)上 CoT 才带来显著提升,小模型上 CoT 甚至可能降低性能——这是推理作为涌现能力的早期实证。
常识推理
在 5 个常识推理 benchmark 上:
- StrategyQA:PaLM 540B + CoT 达到 75.6%(提升 ~6%)
- Date Understanding / Sports Understanding:显著提升,接近或超过微调模型
符号推理
在两个符号推理任务(最后字母拼接、硬币翻转)上:
- 标准 prompting 在序列变长时性能急剧下降
- CoT 在长序列上保持高准确率,展现出长度泛化能力
- 在 OOD(out-of-distribution)长度上,CoT 仍能较好泛化
消融实验
- 只有方程没有自然语言:性能显著下降,说明自然语言推理链本身有价值
- 只有推理链没有最终答案:不可行
- 推理链顺序颠倒:性能大幅下降,说明顺序推理是必要的
结论
Chain-of-Thought prompting 是一种简单、通用的方法,通过在 few-shot 示例中引入中间推理步骤,可以显著提升大语言模型在需要多步推理的任务上的表现。CoT 的优势与模型规模正相关,这暗示推理能力是大规模预训练的涌现性质。
思考
优点
-
极简方法论:不需要任何模型训练、微调或架构修改,纯靠 prompt 设计。方法如此简单却效果显著,这种”简单而深刻”的方法论是经典论文的标志。
-
为后续工作打开空间:CoT 成为了整个推理增强范式的起点。ToT(多路径搜索)、GoT(图结构推理)、o1/R1(RL 训练推理能力)都可以看作 CoT 的自然延伸。从”单链推理”到”多路径搜索”到”自我进化”的演进脉络清晰可见。
-
涌现现象的实证证据:论文清晰展示了”模型越大,CoT 越有效”的模式,为推理作为涌现能力的观点提供了早期实验证据。
-
跨任务泛化:同一套方法(只需要更换 few-shot 示例)在算术、常识和符号推理上均有效,体现了方法的通用性。
缺点与局限性
-
需要人工编写示例:CoT 的 few-shot 示例需要针对每个任务手工设计推理链,不够自动化。后来的 Auto-CoT 等工作试图解决这个问题。
-
无法纠正错误:CoT 是单链推理,一旦某一步出错,后续推理全错。没有回溯、验证或自我纠错机制。这是 ToT 和 RL-based 方法的改进方向。
-
推理链的正确性无法保证:CoT 给出看似合理的推理过程,但模型可能生成逻辑上错误但语法流畅的推理。论文中 GSM8K 仍有 ~43% 的错误率。
-
仅对大规模模型有效:CoT 在小模型上无效甚至有害,这意味着推理增强方法天然地与资源门槛绑定。蒸馏和强模型指导等方法后来部分缓解了这个问题。
-
提示敏感:CoT 的效果对 few-shot 示例的写法很敏感,不同的示例组织方式可能导致较大的性能波动。论文没有系统研究 prompt 设计的影响。