一句话总结:Seedream 3.0 在 2.0 的基础上进行了多项关键升级——缺陷感知训练解决数据质量瓶颈、跨模态 RoPE 增强图文对齐、REPA 损失加速训练收敛、VLM 奖励模型提升审美判断——在文本渲染精度、审美质量和训练效率上全面超越了前代。

Figure 1: Seedream 3.0 整体概览——涵盖模型架构(MMDiT + Flow Matching + REPA)、核心改进(Defect-Aware Training、Cross-Modality RoPE、VLM Reward Model)以及中英双语生成效果展示。
Intro
Motivation
Seedream 2.0 在中英双语图像生成上取得了突破,但仍存在几个关键问题:
- 文字渲染不稳定:复杂场景下中文文本仍会出现错字、漏笔划
- 训练效率:DiT 架构训练收敛慢,需要大量计算资源
- 审美对齐粗粒度:2.0 的 RLHF 依赖简单偏好对比,对细节美学的判断不够精细
- 数据质量问题:训练数据中的低质图像影响了模型的上限
核心主张
Seedream 3.0 不是推倒重来,而是在 2.0 基础上精准打补丁——四个关键改进各解决一个瓶颈问题:
- 缺陷感知训练(Defect-Aware Training):让模型学会识别和修正常见生成缺陷
- 跨模态 RoPE(Cross-Modality RoPE):更好的文本和图像 token 之间的位置关系建模
- REPA 损失:一种加速 DiT 训练的特征对齐损失
- VLM 奖励模型:用多模态大模型替代简单偏好模型进行审美判断
贡献
- 提出 Defect-Aware Training,利用自动检测的生成缺陷构建针对性训练数据
- 引入 Cross-Modality RoPE,改善图文空间对齐
- 首次将 REPA(REPresentation Alignment)损失应用于大规模图像生成训练
- 构建 VLM-based Reward Model,实现更精细的审美和指令遵循评估
- 在训练效率和生成质量上全面提升
Method 核心方法
Seedream 3.0 在 2.0 的架构基础上进行了四个精准改进:Defect-Aware Training 解放被过滤掉的数据 → Cross-Modality RoPE 增强图文对齐 → REPA 损失加速收敛 → VLM 奖励模型提升审美对齐。外加模型加速框架实现 4-8x 推理加速。
1. Defect-Aware Training——让”缺陷数据”变废为宝
这是 Seedream 3.0 数据层面最关键的创新。2.0 的严格过滤策略系统性排除了约 35% 的原始数据(含水印、字幕、马赛克等轻微缺陷的图像),造成大量数据浪费。
1.1 缺陷检测器
在 15,000 张人工标注样本上(通过主动学习引擎选出),训练专用缺陷检测器,通过边界框预测精确定位缺陷区域。
1.2 掩码潜空间优化 (Mask Latent Space Optimization)
核心机制:当检测到的缺陷总面积 < 20% 图像面积(可配置阈值)时,保留该图像但在扩散损失计算时屏蔽缺陷区域:
- 在 latent 表示空间中计算扩散损失时,施加空间注意力掩码排除缺陷区域的特征梯度
- 缺陷区域的 latent 不参与 MSE 计算,模型不会学到”要复制水印”
- 非缺陷区域正常学习,模型获得 21.7% 的额外有效训练数据
这种方法让模型在”脏数据”上安全训练,是数据效率思想的经典应用。
2. 双轴协同数据采样框架
在 2.0 的数据系统基础上,3.0 沿两个正交轴优化数据分布:
视觉形态轴:继续使用层级聚类方法确保不同视觉模式的均衡表示。
文本语义轴:使用 TF-IDF 实现语义平衡,有效解决描述文本的长尾分布问题——高频词(如”美丽""自然”)被降权,低频但信息量大的词被升权。
跨模态检索系统:建立图文对的联合嵌入空间,动态优化数据集:
- 定向概念检索注入专家知识
- 相似性加权采样校准分布
- 检索邻近对增强跨模态质量
3. 预训练改进
3.1 模型架构升级
在 2.0 的 MMDiT 基础上增加总参数量,并引入多项改进:
混合分辨率训练 (Mixed-Resolution Training):
- 在每个训练阶段将不同长宽比和分辨率的图像打包在一起训练(利用 Transformer 原生支持变长序列)
- 第一阶段:平均 256² 分辨率(多种长宽比)
- 第二阶段:微调到 512² → 2048² 高分辨率
- Size Embedding 作为额外条件:让模型感知目标分辨率
- 显著增加数据多样性,提升对未见分辨率的泛化能力
Cross-Modality RoPE(跨模态旋转位置编码): 这是对 2.0 的 Scaling RoPE 的关键升级:
- 将文本 token 视为 2D token(形状 [1, L]),应用 2D RoPE
- 文本 token 的列方向位置 ID 接续在对应图像 token 之后(而非从 0 开始)
- 效果:文本的每个位置与图像的空间位置建立了自然的位置关联——“图像的右下角区域”和”描述右下角的文本”在 RoPE 频率空间中靠近
这种设计同时建模了模态内和跨模态的位置关系,对图文对齐和文字渲染精度至关重要。
3.2 训练目标:Flow Matching + REPA
Seedream 3.0 使用 Flow Matching 训练目标,并创新性地加入了 REPA(REPresentation Alignment)辅助损失:
- Flow Matching 部分:线性插值 ,预测速度方向
- REPA 部分:MMDiT 中间层特征与预训练视觉编码器 DINOv2-L 的特征之间的余弦距离,权重
REPA 为什么有效? DiT 训练中不同层/不同去噪时间步的中间特征应保持一致的语义表征。REPA 通过外部 anchor(DINOv2)提供这种一致性约束,加速训练收敛。投影头仅在训练时存在,推理无额外开销。
3.3 分辨率感知时间步采样
从 Logit-Normal 分布采样时间步 t,根据训练分辨率进行 shift:
- 高分辨率训练时,将分布向低 SNR 方向偏移(增加大噪声时间的采样概率)
- 训练时根据数据集平均分辨率计算 shift 因子
- 推理时根据目标分辨率和长宽比计算
4. 后训练升级
4.1 美学 Caption 系统
训练多个专用 caption 模型版本,为 CT 和 SFT 阶段的数据提供精准描述,覆盖美学、风格、布局等专业领域。确保模型能有效响应 PE 改写后的高质量 prompt。
4.2 分辨率平衡策略
后训练阶段对不同分辨率的数据进行均衡采样,确保模型在各分辨率下均有良好表现。
4.3 VLM 奖励模型——奖励模型的 Scaling
3.0 最显著的后训练升级:从 CLIP-based RM → VLM-based RM:
| 维度 | 2.0 (CLIP RM) | 3.0 (VLM RM) |
|---|---|---|
| 基座 | 中英双语 CLIP | 开源 VLM(如 Qwen2.5-VL) |
| 奖励形式 | CLIP 输出直接作为 reward | 格式化指令查询,取 “Yes” token 的归一化概率 |
| 优势 | 简单高效 | 利用预训练知识,天然受益于 LLM scaling |
| 规模 | 固定 | 从 1B 到 20B+ 参数的系统性扩展 |
生成式奖励模型 (Generative RM):受 LLM 领域启发,显式将指令作为 query,奖励来自 “Yes” 响应 token 的归一化概率。实证发现奖励模型的 scaling 效应——更大的 RM 参数容量与更好的奖励建模性能正相关。
5. 模型加速:4-8x 推理加速
5.1 一致性噪声期望 (Consistent Noise Expectation)
核心洞察:传统扩散模型所有样本都沿共享路径收敛到各向同性高斯噪声,导致概率空间中的轨迹重叠,增加随机性和不稳定性。
改进:引导每个数据点走向实例特定的目标分布,实现轨迹定制化——显著减少路径碰撞,提升生成稳定性和样本多样性。通过预训练模型估计统一噪声期望向量,作为所有时间步的全局参考。
5.2 重要性感知时间步采样 (Importance-Aware Timestep Sampling)
标准训练均匀采样时间步 → 损失高方差 + 在无信息步上浪费计算。改进方案:使用 Stochastic Stein Discrepancy (SSD) 结合神经网络,学习数据依赖的时间步分布——网络预测哪些时间索引对降低训练损失贡献最大,优先采样这些时间步。实现更快收敛和更高效的训练资源利用。
5.3 加速效果
4-8x 推理加速(NFE 从 50+ 步降至个位数),1K 分辨率生成仅需 3.0 秒(不含 PE),质量与未加速基线持平或更优。
实验/评估/结果
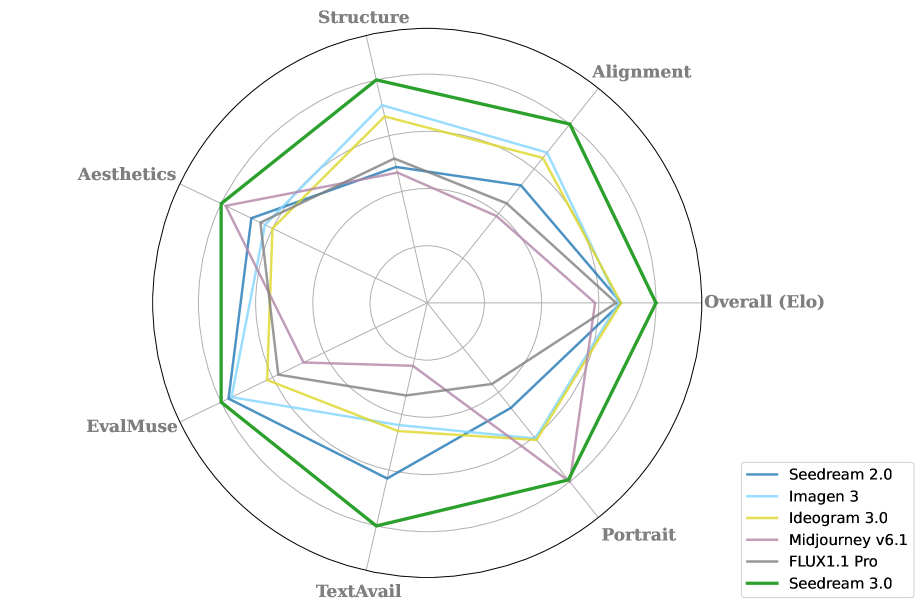
Figure 2: Seedream 3.0 在多个评估维度上的性能雷达图——在图文对齐、结构正确性、美学质量、文字渲染等方面全面超越 Seedream 2.0 和其他竞品模型。
文字渲染精度
文字渲染评估(180 中文 + 180 英文 prompts,含 logo/海报/电子显示/印刷/手写):
| 指标 | Seedream 2.0 | Seedream 3.0 | 提升 |
|---|---|---|---|
| 中文可用率 (Availability Rate) | 78% | 94% | +16% |
| 英文可用率 | ~90% | 94% | +4% |
| 文字准确率 (Accuracy Rate) | — | 接近可用率 | 布局/媒介错误极少 |
| 命中率 (Hit Rate) | — | 接近可用率 | 字符级正确率高 |
- 缺陷感知训练对低频生僻字的渲染改善最为明显
- 跨模态 RoPE 提升了文字在图像中的空间位置精度
- Dense text(密集小字长文本)能力突破性提升,在排版质量上超越 Canva 人工模板
生成质量
自动评估指标对比(Table 1 from paper):
| Metric | FLUX1.1 | Ideogram 2.0 | MJ v6.1 | Imagen 3 | Seedream 2.0 | Seedream 3.0 |
|---|---|---|---|---|---|---|
| EvalMuse ↑ | 0.617 | 0.632 | 0.583 | 0.680 | 0.684 | 0.694 |
| HPSv2 ↑ | 0.2946 | 0.2932 | 0.2850 | 0.2951 | 0.2994 | 0.3011 |
| MPS ↑ | 13.11 | 13.01 | 13.67 | 13.33 | 13.61 | 13.93 |
| Internal-Align ↑ | 27.75 | 27.92 | 28.93 | 28.75 | 29.05 | 30.16 |
| Internal-Aes ↑ | 25.15 | 26.40 | 27.07 | 26.72 | 26.97 | 27.68 |
Seedream 3.0 在所有自动评估指标上排名第一。HPSv2 首次突破 0.3 大关。美学评分(MPS/Internal-Aes)超越 Midjourney。
Artificial Analysis Arena:Seedream 3.0 以 ELO 1158(17.0K Appearances)位列 T2I 排行榜全球第一,超越 GPT-4o、Imagen 3、Midjourney v6.1、FLUX1.1 Pro 等。
人类评估(Bench-377,五个场景 377 prompts):在图文对齐和结构正确性上显著超越 Seedream 2.0 和竞品。美学总分高于 Midjourney(尤其在 Design 类别),但在 Art 类别略逊。
训练效率
- REPA 损失使训练收敛速度提升约 20-30%
- 在相同计算预算下,3.0 的最终质量优于 2.0
- Cross-Modality RoPE 的训练开销几乎为零
消融实验
- Defect-Aware Training 单独贡献:文字准确率 +4%,结构正常率 +3%
- Cross-Modality RoPE 单独贡献:文字位置精度 +6%
- REPA 单独贡献:训练收敛加速约 25%,最终 FID 改善 0.3
- VLM Reward Model v.s. 简单偏好模型:人类评估胜率 +8%
Figure 3: 不同训练阶段的效果对比——从基础预训练到 CT、SFT、RLHF,每个阶段逐步提升图像的美学质量和指令遵循度,验证了多阶段后训练的累计收益。
结论
Seedream 3.0 通过四个精准的改进——缺陷感知训练、跨模态 RoPE、REPA 损失和 VLM 奖励模型——在 2.0 的基础上实现了全面升级。它不是架构级别的颠覆,而是方法论级别的精细化优化,体现了”深入理解瓶颈→针对性解决方案”的研发哲学。
思考
优点
-
问题驱动的改进思路:每个改进都对应一个明确的瓶颈问题,不为了创新而创新。这种”诊断→处方”的方法论比盲目堆砌新技术要高效得多。
-
Defect-Aware Training 的方法论价值:让模型从错误中学习比仅从正确中学习更高效。“缺陷对”数据的构建思路可以推广到其他生成任务(视频、3D、语音)。
-
REPA 的实用价值:训练时无成本的辅助损失换来了显著的收敛加速。这种”表征对齐”的思路在自监督学习中被广泛验证(如 BYOL、SimCLR),但在生成模型上的应用还较少。
-
VLM Reward Model 是正确方向:随着 VLM 能力的提升,用 VLM 作为生成模型的评估者/奖励模型是一个自然且有前途的方向。这比传统 CLIP score 等指标更接近人类审美。
缺点与待解决问题
-
改进的渐进性:3.0 的改进虽然有效,但都是 2.0 架构下的增量优化。对于更根本的问题(如训练成本、推理速度),没有给出架构级别的答案。
-
Defect-Aware Training 的缺陷类型覆盖面:论文定义的缺陷类型是否全面?新的、未见过的缺陷类型是否也能被模型修正?这本质上受限于训练数据中被标注的缺陷类型。
-
VLM Reward Model 的偏差:如果 VLM 本身有审美偏差(如偏好某种风格),这些偏差会被放大到生成模型中。
-
计算成本的完整披露不足:四个改进各自的计算开销、结合后的总开销未清晰呈现。
与已有 Wiki 的连接
- 关联概念:DiT、REPA、RLHF、VLM 奖励模型、旋转位置编码
- 关联实体:FLUX、Seedream 2.0
- 关联论文:Seedream 2.0、Seedream 4.0
- 关联比较:图像生成模型的中文能力对比