一句话总结:SAIL-Embedding 是字节跳动(抖音)提出的全模态嵌入基础模型,支持文本+图像+音频任意组合输入,通过动态 hard negative mining、自适应多源数据平衡、MRL 多粒度表示、COSENT 排序损失、mICL 跨模态对比、Stochastic Specialization Training 和协作感知推荐增强训练(CRE: Seq2Item + ID2Item 蒸馏),在抖音推荐系统的 i2i 和 q2i 检索任务上全面超越 CLIP 式和 VLM 式基线,线上带来 +0.5% 7 天 LT 增益。
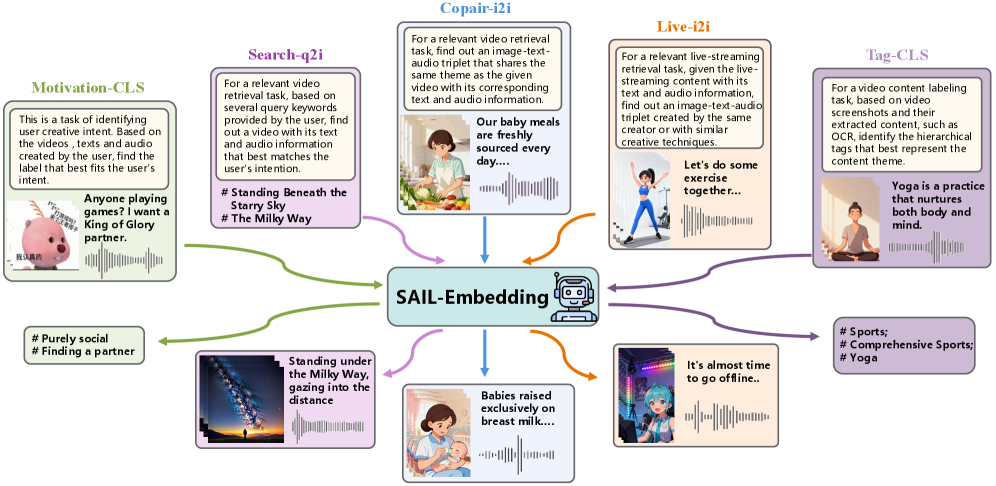
Figure 1: SAIL-Embedding 能力总览——支持全模态嵌入任务,包括分类、q2i 检索、i2i 检索等。
Intro
Motivation
现有嵌入模型在工业部署中面临三大挑战:
- 模态受限:大多数方法仅用图+文,但抖音视频包含封面帧、关键帧、标题、标签、BGM、ASR 转录等多模态信息,任一模态缺失都会严重损害推荐和搜索效果
- 训练不稳定:基于 MLLM 的嵌入模型需要精心设计的优化策略
- 工业域鸿沟:开源数据集训练出的模型在抖音短视频等工业场景表现不佳
贡献
- 支持文本+视觉+音频的全模态嵌入,适用任意模态组合
- 动态 hard negative mining + 自适应多源数据平衡
- 多阶段训练:内容感知渐进训练→协作感知推荐增强(CRE)
- Stochastic Specialization Training + Dataset-Driven Pattern Matching
- 工业级验证:抖音线上 LT +0.5%,排名模型 AUC +0.1%
Method 核心方法
1. 全模态架构
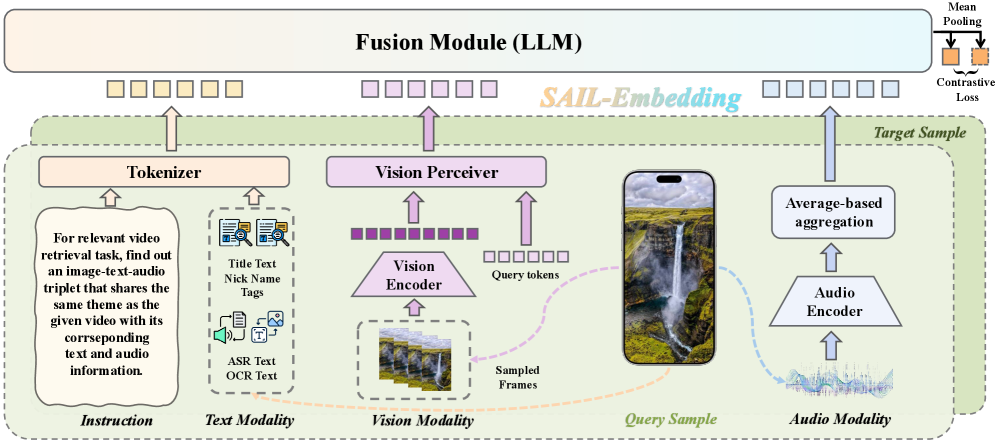
Figure 4: SAIL-Embedding 模型架构总览——文本(标题/OCR/ASR)、视觉(ViT+Visual Perceiver)、音频(CLAP)三模态 token 拼接后输入 LLM,通过 tanh+mean pooling 获得统一多模态嵌入,用对比学习训练 query-target pairs。
- 文本:标题、OCR、ASR、作者名、标签等多字段拼接,随机 drop 适应线上缺字段场景
- 视觉:ViT 骨干 + Visual Perceiver(16 个可学习 latent query token)压缩视频帧 tokens
- 音频:CLAP 模型提取(短音频 repeat-and-pad,长音频分块+mean pooling),统一为 1 个 token
- 融合:三模态 token 拼接 → LLM 双向注意力 → tanh + mean pooling → 最终嵌入
2. 训练目标(多 loss 组合)
- NCE-MRL(Matryoshka Representation Learning):在 128/768/1536 三个维度上同时优化,支持推理时灵活降维
- COSENT loss:基于余弦相似度的排序损失,增强文本检索的细粒度排序
- mICL loss:多模态 In-Context Learning,对视觉和文本分别做模态内对比
- Late fusion loss:门控融合视觉嵌入和多模态嵌入,保留视觉保真度
3. 动态 Hard Negative Mining
- 为每个数据集自适应确定最优相似度阈值 (最大化 F1 score)
- 高于阈值→false negative 过滤,低于阈值但最高的一批→hard negatives
- 避免了固定全局阈值的次优问题
4. 自适应多源数据平衡
- 用 Sinkhorn 算法度量各训练集与验证集的语义相似度
- 根据相似度分配采样权重(soft selection),替代人工调参
- 保持数据质量和分布多样性的平衡
5. Stochastic Specialization Training
- 每步随机选一个数据集,整个 batch 全部来自该数据集
- 增大单域有效 batch size,降低域间梯度方差
- 新增数据集只需简单配置,无需修改训练逻辑
6. Dataset-Driven Pattern Matching
- 将 CLIP 目标推广为 modality-to-modality 范式
- 每种模态组合动态构造 query-target 对(ITC/IIC/VTC/VVC/TTC/OOC)
- 一个样本在一次前向中评估所有可行匹配
7. 协作感知推荐增强训练(CRE)
- Seq2Item 蒸馏:用户历史观看序列(10 个视频)→ 聚合表示 → 与目标视频做对比学习
- 4 种兴趣建模:内容/协作 × 单峰/多峰
- ID2Item 蒸馏:对齐模型输出与推荐系统的 ID embeddings
- 主任务(220M 样本)+ 辅助 i2i 任务(20M),多任务防止内容感知能力退化
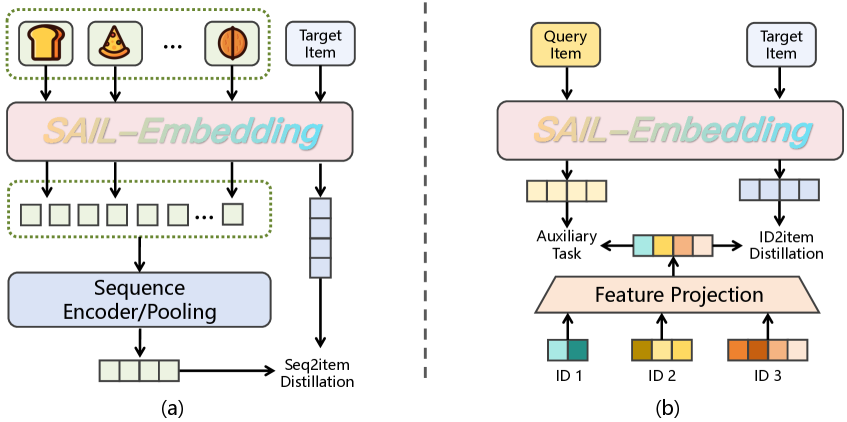
Figure 7: 推荐增强训练(CRE)——(a) Seq2Item 蒸馏:用户历史观看序列聚合后与目标视频做对比学习;(b) ID2Item 蒸馏:对齐 SAIL-Embedding 输出与推荐系统 ID embeddings,实现内容理解与协同信号的桥接。
实验/评估/结果
i2i 检索(21 个任务)
- 在搜索和协作感知场景下一致大幅超越 CLIP 式和 VLM 式基线
- Brand Vehicle: Recall@50 从 45.97 提升至 52.03
- Brand Phone: Recall@50 从 66.31 提升至 72.54
q2i 检索(9 个任务)
- 全面超越 Doubao-Embedding、Qwen3-Embedding 等纯文本嵌入模型
- Short Video-q2i: Recall@50 从 78.53 提升至 86.53
- Longtail-q2i: AUC 从 84.02 提升至 91.22
协作感知增强(CRE)效果
- NMI: +5%,正负样本在聚类中更可分离
- Kendall 一致性: +3.8%,检索排序更稳定
- Gid-i2i Recall@50: +7.23% 大幅提升
线上实验
- 抖音 Feed 排名:AUC +0.1%
- 抖音精选 7 天 LT:+0.5%
- 冷启动 LT30:+0.05%
- 语义 ID(SID)在召回/粗排/精排/重排各阶段均有持续收益
结论
SAIL-Embedding 展示了全模态嵌入模型在工业推荐系统中的巨大价值。通过音频模态的加入、精心设计的训练策略和协作感知增强,模型不仅在离线 benchmark 上全面领先,在抖音的线上实验中也带来了显著的商业指标提升。
思考
优点
-
工业级全模态的标杆:这可能是目前最全面的工业级多模态嵌入模型论文。文本+视觉+音频的全模态支持、MRL 多粒度表示、多 loss 组合、从预训练到推荐增强的完整训练管线——每个环节都体现了工业落地的深度思考。
-
音频模态的价值被充分证明:SAIL-Embedding 相比 VLM 式模型的显著提升,很大程度上来自音频模态(BGM、ASR)的加入。这提醒社区:在短视频场景中,音频不是可选的加分项,而是必要的信息源。
-
CRE 训练的巧妙设计:Seq2Item(捕捉用户兴趣序列)+ ID2Item(对齐推荐系统表示)的组合,既保留了内容理解能力,又融入了协同信号。这种”桥接”设计是多模态嵌入走向推荐系统的关键一步。
-
训练策略的系统性:动态 HN mining、自适应数据平衡、Stochastic Specialization、Pattern Matching——每项技术都解决了工业训练中的具体痛点。
缺点与待解决问题
-
模型细节和训练成本未充分披露:作为工业论文,骨干 LLM 的具体选择、参数量、训练 GPU 小时等关键信息模糊。
-
全模态支持的边界条件:当某些模态缺失时(如纯图文场景),模型的鲁棒性如何?论文提到了随机 drop 策略,但未给出模态缺失的消融分析。
-
与学术 benchmark 的对齐不足:论文的评估主要在抖音内部数据集上,缺乏与标准学术 benchmark(如 MMEB)的对齐,使得学术社区难以直接比较。
-
模型不开源:作为工业模型,不开源可以理解,但削弱了社区可复现性。