一句话总结:Kimi k1.5 将 RL 训练的上下文窗口扩展到 128k,通过 partial rollouts(部分回滚)和 online mirror descent 算法实现高效长上下文 RL 训练。长 CoT 模型在 AIME(77.5)、MATH-500(96.2)、Codeforces(94th percentile)等指标上与 OpenAI o1 持平;同时提出 long2short 方法将长 CoT 的推理能力压缩到短 CoT 模型中。
Intro
Motivation
语言模型预训练的扩展受限于高质量数据的可用量。RL 提供了一条新的扩展轴——模型通过探索和奖励自主学习,不再受限于静态数据集。然而已发表的 LLM + RL 工作未能产生有竞争力的结果。
Kimi k1.5 的核心洞察:上下文长度是 RL 扩展的关键维度——更长的上下文允许模型进行更多”隐式搜索步骤”(反思、纠错、回溯),从而在不需要 MCTS、价值函数、过程奖励模型等复杂技术的前提下达到强推理性能。
核心贡献
- 128k 上下文 RL 训练:通过 partial rollouts 技术在不大幅增加计算成本的前提下扩展 RL 上下文
- Online Mirror Descent 策略优化:推导长 CoT 的 RL 形式化,使用离线策略梯度 + L2 正则化
- Long2Short:通过模型合并、最短拒绝采样、DPO 和 long2short RL 将长 CoT 推理能力压缩到短 CoT 模型
- 多模态 RL:文本+视觉联合训练
- RL 基础设施:混合部署(Megatron + vLLM)、partial rollouts、代码沙箱等工程优化
Method 核心方法
Kimi k1.5 的方法论核心是”将规划算法扁平化为自回归生成”,通过 OMD(Online Mirror Descent)变体 RL + Partial Rollouts + Long2Short 压缩实现长上下文推理。
Long2Short 方法对比
| 方法 | 机制 | 效果 |
|---|---|---|
| Model Merging | 长/短 CoT 模型权重平均 | 最简单,保留长 CoT 能力的同时缩短输出 |
| Shortest Rejection Sampling | 采样 n 次选最短正确响应 | 直接有效,但依赖拒绝采样质量 |
| DPO | 最短正确=正例,更长=负例 | 通过偏好对显式学习简洁推理 |
| Long2Short RL | RL + 长度惩罚 + 降低 rollout 长度 | 端到端优化,最灵活 |
关键视角转换:传统规划算法在搜索树上通过价值估计引导搜索方向,但由于思维(thoughts)和反馈(feedbacks)都可以表示为语言 token 序列,实际上规划算法等价于一个对推理步骤序列的映射 。
这意味着:我们不需要显式构建搜索树——可以通过 RL 训练模型直接在自回归生成中执行”隐式搜索”。上下文长度类似于传统规划算法的计算预算。
Policy Optimization:Online Mirror Descent 变体
每轮迭代以当前模型 为参考,优化 KL 正则化目标:
最终梯度形式与 policy gradient 类似,但使用 off-policy 采样 + L2 正则化,且不使用价值网络。核心观点:在长 CoT 训练中,应当鼓励模型探索多样化的推理路径(包括错误路径和回溯),而非仅奖励正确路径。这与传统 RL 中用价值函数做信用分配的思路根本不同。
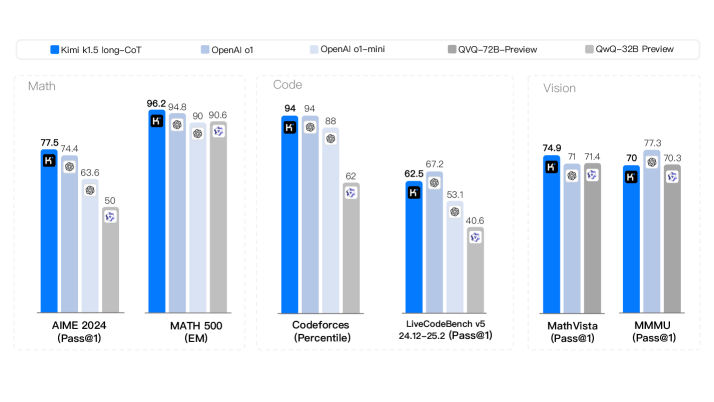
Figure 11: Kimi k1.5 的模型架构。支持文本+图像的交错输入,通过大规模 RL 增强推理能力。
Length Penalty(长度惩罚)
防止 overthinking(推理过长):
- 在正确答案中:更短的响应获得更高奖励
- 在错误答案中:长响应获得更强惩罚
- 采用 warmup 策略:先无惩罚训练,再引入恒定长度惩罚
Partial Rollouts
将超长响应分段,跨 RL 迭代复用:
- 设定固定输出 token 预算
- 超长的 rollout 在迭代中跨段存储,下一轮继续生成
- 利用 replay buffer 重用之前的 rollout 片段
- 支持重复检测和早期终止
这本质上是用时间换空间——通过增加迭代次数来容纳更长的响应,避免单次 rollout 耗尽系统资源。
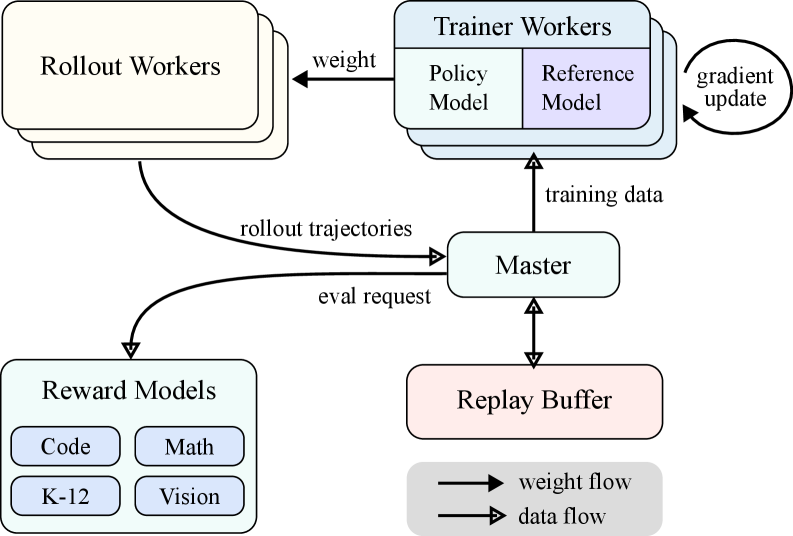
Figure 3: Kimi k1.5 的 RL 训练系统。(a) rollout 阶段和训练阶段的迭代同步流程;(b) partial rollout 的跨迭代分段复用机制。
采样策略
- Curriculum Sampling:从简单到困难逐步训练
- Prioritized Sampling:按 概率采样,聚焦模型薄弱区域
Long2Short:上下文压缩
四种方法将长 CoT 能力转移到短 CoT 模型:
- Model Merging:长 CoT 和短 CoT 模型权重平均
- Shortest Rejection Sampling:对同一问题采样 n 次,选最短的正确响应用于 SFT
- DPO:最短正确响应作为正例,更长响应(含正确和错误)作为负例
- Long2Short RL:在 RL 训练中加入长度惩罚并大幅降低最大 rollout 长度
实验/评估/结果
长 CoT(Kimi k1.5 long-CoT)
| Benchmark | k1.5 | o1-mini | o1 |
|---|---|---|---|
| MATH-500 | 96.2 | 90.0 | 94.8 |
| AIME 2024 | 77.5 | 63.6 | 74.4 |
| Codeforces | 94%ile | 88%ile | 94%ile |
| MathVista | 74.9 | - | 71.0 |
短 CoT(Kimi k1.5 short-CoT)
| Benchmark | k1.5 short | GPT-4o | Claude 3.5 Sonnet |
|---|---|---|---|
| MATH-500 | 94.6 | 74.6 | 78.3 |
| AIME 2024 | 60.8 | 9.3 | 16.0 |
| LiveCodeBench | 47.3 | 33.4 | 36.3 |
| MMLU | 87.4 | 87.2 | 88.3 |
短 CoT 模型在推理任务上比 GPT-4o 和 Claude 3.5 Sonnet 提升最高 550%。
关键消融
- 上下文长度扩展:模型性能和响应长度随训练同步增长,更难的 benchmark 增长斜率更陡
- 负梯度的重要性:使用 ReST(只拟合最佳响应,无负梯度)的方法在样本效率上显著劣于使用负梯度的 RL
- Curriculum Sampling:先全量数据 warmup、再聚焦难题的策略显著优于均匀采样
- Long2Short 对比:Long2Short RL 的 token 效率最高,在 AIME 上用 ~3,272 tokens 平均达到 60.8 pass@1
结论
Kimi k1.5 证明了通过长上下文 RL(128k)+ 改进的策略优化(online mirror descent + 长度惩罚 + partial rollouts),可以在不使用 MCTS/价值函数/PRM 等复杂技术的前提下达到与 o1 持平的推理性能。Long2Short 方法进一步证明了长 CoT 的推理能力可以被高效压缩到短 CoT 模型中。
思考
优点
-
“规划扁平化”的理论视角:将规划算法中的搜索树扁平化为自回归 token 序列,然后用 RL 训练模型执行隐式搜索——这个视角统一了推理时搜索和训练时 RL,具有很强的理论启发性。
-
Partial Rollouts 的工程价值:这是论文中最独特的工程贡献。通过跨迭代复用 rollout 片段,解决了长上下文 RL 的核心计算瓶颈。这个技术不局限于 Kimi,对任何需要长 rollout 的 RL 训练都具有普适价值。
-
Long2Short 的实用导向:很多推理工作只关注”最强的长 CoT 模型”,但实际部署往往需要短响应。Kimi 的 long2short 方法论(模型合并、最短拒绝采样、DPO、long2short RL)形成了一个完整的”推理能力压缩”工具箱。
-
RL 基础设施的完整披露:详细描述了 Megatron + vLLM 混合部署、checkpoint-engine、代码沙箱优化等工程细节,为工业界复现提供了重要参考。
-
长度惩罚的细致设计:区分正确答案和错误答案的长度惩罚,采用 warmup 策略避免初始训练阶段的性能损失——这些细节体现了对训练动力学的深入理解。
缺点与局限性
-
OpenAI o1 的 benchmark 数据来源不透明:论文中 o1 的性能数据一部分来自 OpenAI 官方报告,一部分来自第三方,某些 benchmark 上缺乏直接对比。77.5 AIME 是否真的”匹敌”o1 仍需独立验证。
-
Online Mirror Descent 的实现细节模糊:虽然给出了数学推导,但 参数的选择、迭代频率、采样数量 等关键超参数未披露。推导与具体实现之间的差距较大。
-
多模态 RL 的实验深度不足:虽然声称支持文本+视觉联合训练,但多模态部分的技术细节(视觉数据的具体构成、视觉编码器的训练策略等)被放在附录中且描述简略。
-
与 DeepSeek-R1 的对比缺失:论文发表于 2025 年 1 月,与 DeepSeek-R1 几乎同期。两篇论文的方法论有显著差异(Kimi 强调长上下文 + OMD,R1 强调 GRPO + 多阶段),但彼此未进行直接对比。这对社区判断两种路线的优劣造成困扰。
-
代码沙箱的局限性:仅 323/1000 的编程问题能通过测试用例生成进入训练集,意味着 RL 在编程任务上的训练密度可能不足,这可能解释了 LiveCodeBench 上 k1.5(62.5)与 o1(67.2)的差距。