一句话总结:Kimi K2.5 在 K2 基础上引入联合文本-视觉优化和 Agent Swarm 并行 agent 编排框架,通过 early vision fusion、zero-vision SFT、多模态联合 RL 以及 PARL(Parallel-Agent RL)实现 vison-text 双向增强和并行任务执行,在多个 benchmark 上达到开源 SOTA,推理延迟降低 4.5x。
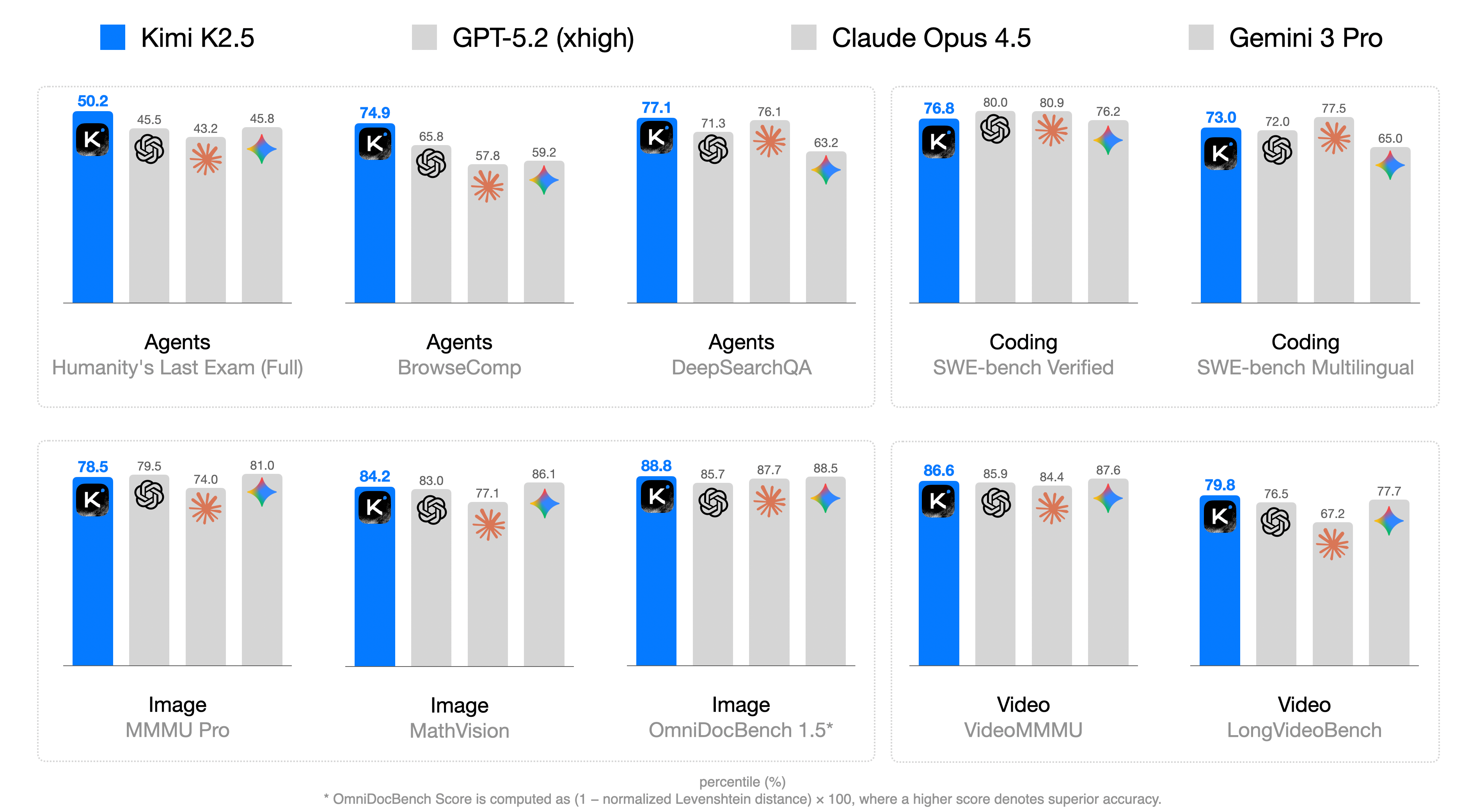
Figure 1: Kimi K2.5 主结果。
Intro
Motivation
Kimi K2.5 致力于解决两个关键问题:
- 文本与视觉如何联合优化而不互相冲突?传统方法将视觉作为后期附加组件,容易损害语言能力
- 串行 agent 执行的延迟和可扩展性限制?复杂任务(如大规模搜索/工程)需要并行分解
贡献
- 联合文本-视觉优化:early vision fusion + zero-vision SFT + 多模态联合 RL,视觉 RL 反过来提升文本性能
- Agent Swarm(PARL 框架):可训练 orchestrator 动态分解任务、创建子 agent 并行执行,延迟降低 3~4.5x
- MoonViT-3D:原生分辨率视觉编码器,支持 NaViT packing 和 4x 视频时序压缩
- Toggle 训练策略:交替「预算约束」与「标准缩放」阶段,提升 token 效率 25~30%
Method 核心方法
1. 联合文本-视觉优化
Native Multimodal Pre-training:
- 在固定 token 预算下,early fusion + 低 vision ratio(10%)优于 late fusion + 高 ratio(50%)
- K2.5 在整个训练过程中以恒定比例混合文本和视觉 token,在约 15T tokens 上联合预训练
Zero-Vision SFT:
- 仅用文本 SFT 数据激活视觉和 agentic 能力(视觉操作通过 IPython 程序代理完成)
- 发现 text-vision SFT 反而损害视觉/agentic 性能(缺乏高质量视觉数据),zero-vision 却泛化更好
- 原因:联合预训练已建立强 vision-text 对齐,能力自然跨模态泛化
联合多模态 RL:
- Outcome-based visual RL(视觉定位、图表理解、STEM 问题)
- 关键发现:视觉 RL 提升了文本性能(MMLU-Pro +1.7、GPQA-Diamond +2.1)
- 最终采用能力域(而非模态)划分 RL:同一能力域专家同时从纯文本和多模态 query 学习
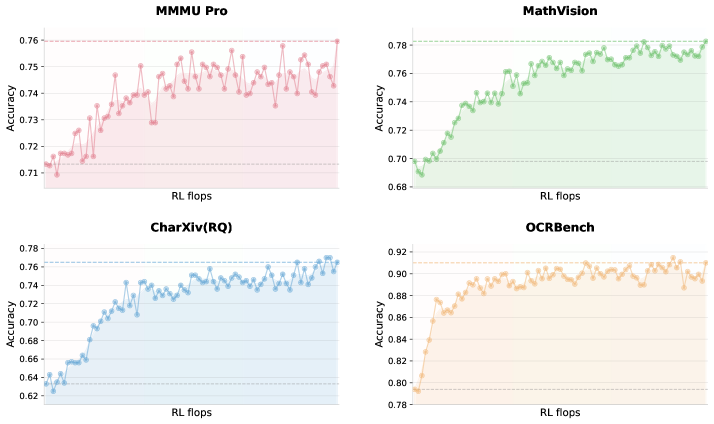
Figure 2: 从 zero-vision SFT 出发的视觉 RL 训练曲线。视觉 benchmark 性能随 RL FLOPs 扩展持续提升,验证了 zero-vision 激活 + 长 RL 即可获得鲁棒视觉能力。
- Toggle 策略:交替执行 Phase0(预算约束、条件惩罚超长输出)和 Phase1(标准最大 token 限制),降低 25~30% 输出 token 同时基本保持性能
RL 目标函数:
- Token-level clipping 稳定长轨迹多步工具使用 RL
- 生成式奖励模型(GRM):细粒度评估 helpfulness、answer readiness、上下文相关性、美学质量等
2. Agent Swarm
PARL(Parallel-Agent RL)架构:
- Trainable orchestrator + 冻结子 agent(来自固定中间 checkpoint)
- 解耦设计避免信用分配模糊和训练不稳定
Figure 3: Agent Swarm 架构。可训练的 orchestrator 动态创建专门的冻结子 agent,将复杂任务分解为可并行执行的子任务。
PARL 奖励函数:
- :防止 serial collapse(回退到单 agent 执行)
- :防止 spurious parallelism(无意义大量创建子 agent)
- 、 训练过程中退火到 0
Critical Steps 资源约束:按 computation graph 定义关键步骤,最长并行分支决定阶段耗时,激励均衡任务分解。
3. MoonViT-3D 架构
- 从 SigLIP-SO-400M 初始化,加入 NaViT packing 支持变分辨率
- 视频:连续 4 帧为 spatiotemporal volume,patch-level 时序平均实现 4x 压缩
- 图像和视频完全共享参数
4. 训练基础设施
- DEP(Decoupled Encoder Process):视觉编码器前向在所有 GPU 上均衡分配,舍弃中间激活,主 backbone 训练后再重算视觉 forward + backward
- 多模态训练效率达到纯文本训练的 90%
实验/评估/结果
主结果(部分)
| Benchmark | Kimi K2.5 | Claude Opus 4.5 | GPT-5.2 | Gemini 3 Pro | DS-V3.2 |
|---|---|---|---|---|---|
| AIME 2025 | 96.1 | 92.8 | 100 | 95.0 | 93.1 |
| HMMT 2025 | 95.4 | 92.9 | 99.4 | 97.3 | 92.5 |
| HLE w/ tools | 50.2 | 43.2 | 45.5 | 45.8 | 40.8 |
| SWE-bench Verified | 76.8 | 80.9 | 80.0 | 76.2 | 73.1 |
| BrowseComp | 60.6 | 37.0 | 65.8 | 37.8 | 51.4 |
| MMMU-Pro | 78.5 | 74.0 | 79.5 | 81.0 | - |
| OSWorld | 63.3 | 66.3 | 8.6 | 20.7 | - |
| VideoMMMU | 86.6 | 84.4 | 85.9 | 87.6 | - |
Agent Swarm
| Benchmark | Agent Swarm | 单 Agent | 提升 |
|---|---|---|---|
| BrowseComp | 78.4 | 60.6 | +17.8 |
| WideSearch | 79.0 | 72.7 | +6.3 |
| In-house Swarm | 58.3 | 41.6 | +16.7 |
- 延迟:WideSearch 达到 70% F1 时 3~4.5x 加速
Token 效率
| Benchmark | K2.5 | K2 Thinking | Gemini 3 Pro | DS-V3.2 |
|---|---|---|---|---|
| AIME 2025 | 96.1 (25k) | 94.5 (30k) | 95.0 (15k) | 93.1 (16k) |
| GPQA Diamond | 87.6 (14k) | 84.5 (13k) | 91.9 (8k) | 82.4 (7k) |
结论
Kimi K2.5 证明通过联合文本-视觉优化 + 并行 agent 编排可以同时提升性能与效率。Zero-vision SFT 是重要的方法论发现:多模态能力可以通过纯文本训练激活。Agent Swarm 将任务复杂性从线性缩放转变为并行处理。
思考
优点
- 文本-视觉双向增强是重要发现:视觉 RL 提升文本性能(MMLU-Pro +1.7),挑战了”多模态训练损害文本能力”的传统认知
- Zero-vision SFT 反直觉但有效:证明联合预训练建立的对齐可以实现能力跨模态泛化
- Agent Swarm 是具前瞻性的 agent 框架:PARL 的串行崩溃/虚假并行双奖励设计精巧,Critical Steps 作为资源约束实用
- DEP 训练基础设施创新:保持文本训练已有并行策略,对社区工程实践有参考价值
- Toggle 策略平衡质量与效率:预算约束阶段条件化,避免过早牺牲质量
缺点
- Agent Swarm 的实际部署复杂度:多个子 agent 并行需要大量推理资源,成本和延迟在低预算场景可能不如单 agent
- 与 Gemini-3.0-Pro 的 token 效率差距仍大:推理问题输出 25k vs 15k,工程实用性受限
- Agent Swarm 任务类型受限:主要在搜索场景评估,SWE 等代码场景未验证
- 视觉编码器的计算开销:支持 3.2M 像素输入,低端设备部署困难
- GRM 的复杂性和潜在偏差:多个 GRM rubric 虽设计精巧,但对齐成本和效果验证不足