一句话总结:本文提出 Graph of Thoughts(GoT)框架,将 LLM 推理从 CoT 的链和 ToT 的树进一步推广为有向无环图(DAG),允许思维单元之间进行合并、聚合、精炼等图操作,在排序任务上相比 ToT 减少 62% 的计算成本的同时保持或超越性能。
Intro
Motivation
CoT 使用单链推理,ToT 使用树结构在每步探索多个分支,但这两种范式都无法充分利用思维之间的复杂依赖关系。在许多推理任务中:
- 多个思维分支可能产生互补信息,需要合并
- 某个思维可能是多个后续思维的共同前置条件
- 思维可以被精炼(refine)而不是简单替换
GoT 将思维建模为图中的节点,思维之间的依赖关系为边,从而支持更丰富的推理拓扑。这统一了并超越了 CoT(单链)和 ToT(树)。
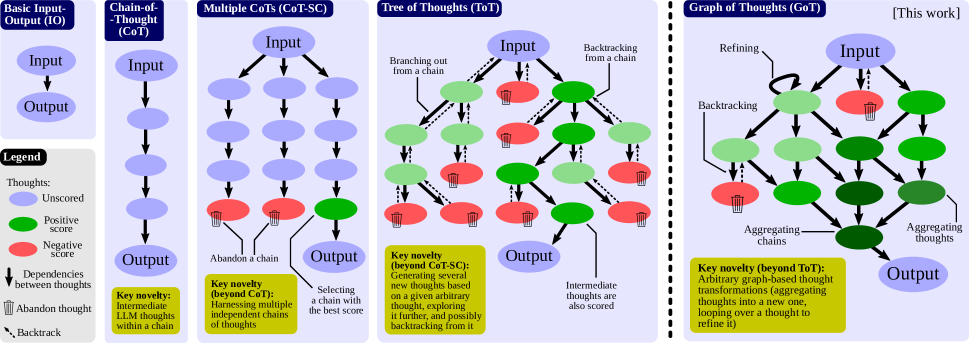
Figure 1: GoT 与 CoT、ToT 等推理框架的对比。CoT 是单链、ToT 是树、GoT 推广为有向无环图(DAG),支持更丰富的思维依赖关系。
GoT 的核心建模
GoT 用有向无环图 表示推理过程:
- 顶点 是思维单元(thoughts)
- 边 表示思维之间的依赖关系
- 图操作(transformations)定义如何从已有思维生成新思维
贡献
- 提出 GoT 框架,将 LLM 推理推广到图结构
- 定义了图推理的核心操作:聚合(Aggregation)、精炼(Refinement)、生成(Generation)
- 引入基于图的排序和评估机制
- 在排序任务上展示优于 ToT 的性能和效率(-62% 成本)
Method 核心方法
思维建模
GoT 中的思维是一个三元组(内容, 状态, 评分):
- 内容:思维的具体文本
- 状态:思维的处理状态(未处理/已处理)
- 评分:思维的质量评估
核心图操作
GoT 设计了三种核心操作将已有思维变换为新思维:
1. 生成(Generate):从一个或多个思维生成新的思维。类似于 CoT 的思维步进和 ToT 的分支生成。LLM 接收前序思维作为上下文,生成后续推理。
2. 聚合(Aggregate):将多个思维合并为一个。这是 GoT 相对于 CoT/ToT 的核心创新。例如在排序任务中,可以对不同子列表的排序结果进行归并。聚合能将并行探索的结果整合,减少冗余计算。
3. 精炼(Refine):基于反馈改进已有思维。类似于 self-refine,但被形式化为图操作。LLM 接收原思维和反馈信息(如评分),生成改进版本。
推理流程
- 构建初始思维(图中的叶子节点)
- 应用图操作递归生成新思维(图中的内部节点)
- 利用评分机制评估思维质量
- 最终思维即为推理结果
GoT 支持任意的有向无环推理拓扑——只要保证数据依赖关系形成 DAG,任何连接模式都是合法的。
排序架构示例
对于排序任务(GoT 的主要验证场景),设计了一个专门的多层架构:
- 底层:将序列分割为子序列,各子序列独立排序(并行生成)
- 中层:对子序列排序结果两两归并(聚合操作)
- 顶层:最终归并为完整排序结果
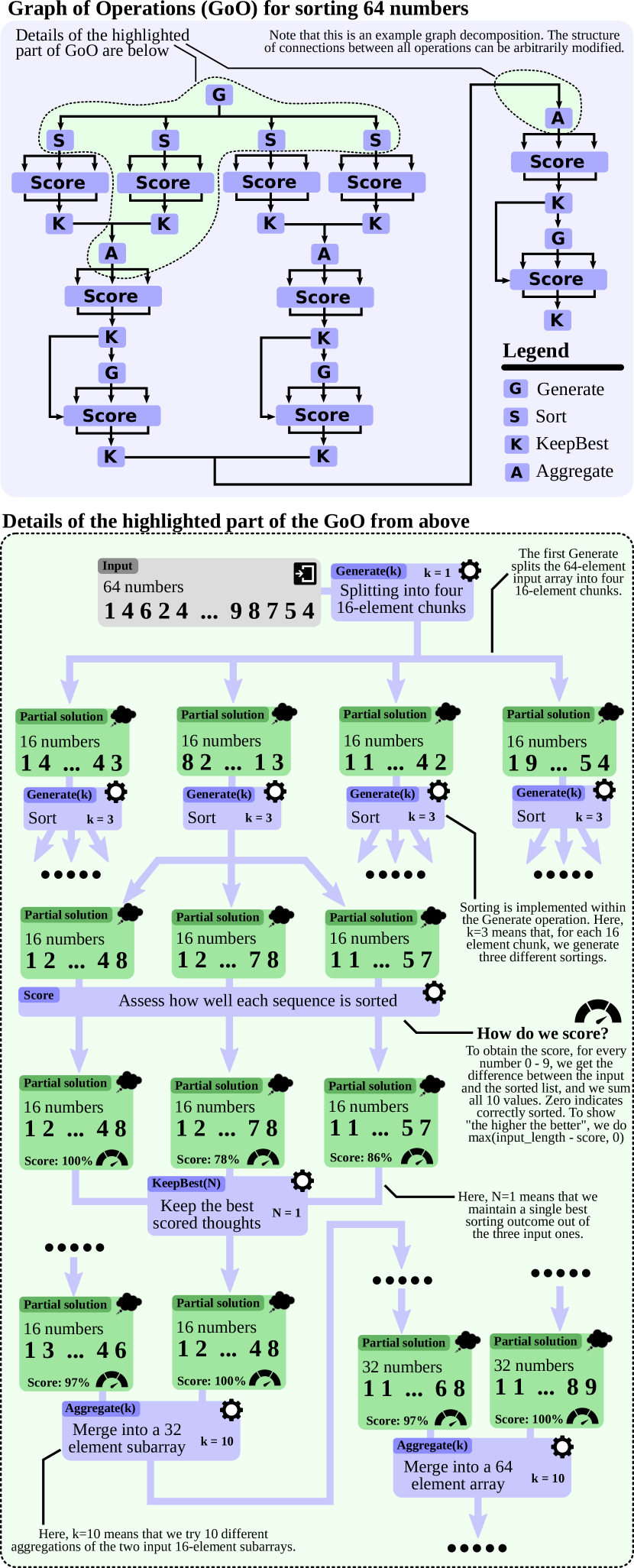
Figure 4: 排序任务的 GoT 图分解示例。子序列独立排序后通过聚合(Aggregate)操作归并,最终得分最高的结果被保留(KeepBest)。
实验/评估/结果
排序任务(核心验证)
| 方法 | 排序准确率(64 元素) | 计算成本 | 效率 |
|---|---|---|---|
| CoT | 基准 | 基准 | 1x |
| ToT | +提升 | ~3x CoT | 0.33x |
| GoT | 最优 | -62% vs ToT | ~1.6x CoT |
GoT 的排序准确率优于 ToT 和 CoT,尤其在长序列上;聚合操作将并行探索结果有效复用,计算成本比 ToT 降低 62%。随序列增长,GoT 的效率优势更加明显。
关键分析
| 组件 | 贡献 |
|---|---|
| 聚合操作(Aggregate) | 合并并行结果,避免冗余从头推理 |
| 评分机制(Scoring) | 识别高质量思维,引导后续操作方向 |
| DAG 拓扑灵活性 | 不同任务可设计不同图拓扑匹配内在结构 |
结论
GoT 将 LLM 推理从链/树推广到图,通过引入聚合、精炼等图操作,实现了更高效和更灵活的多步推理。图结构推理尤其适合具有天然分解-归并结构的任务。
思考
优点
-
概念上的统一与推广:GoT 将 CoT 和 ToT 统一为图推理的特例,是从链到树到图的自然演进。DAG 结构能表示更丰富的推理依赖关系。
-
效率提升有实证支撑:62% 的成本降低不是靠减少 LLM 调用次数,而是通过更智能的思维复用——聚合操作让并行分支的探索成果能被整合,避免了 ToT 中各分支独立从头推理的冗余。
-
形式化清晰:GoT 将推理过程形式化为图上的操作代数,有明确的数学定义,便于分析和实现。评分机制、状态管理和操作定义都有完整的规范。
-
模块化设计:GoT 的操作(生成、聚合、精炼)可以组合使用,图拓扑可以根据任务自由设计,提供了很大的定制空间。
缺点与局限性
-
实验范围较窄:主要实验集中在排序任务上。虽然排序是验证图推理的理想场景,但论文缺乏在更广泛推理任务(如数学、代码、常识推理)上的验证。这使其通用性存疑。
-
图拓扑需要人工设计:与 ToT 一样,GoT 的图结构需要针对每个任务手动设计,缺乏自动化的拓扑发现机制。这在实际部署中是很大的障碍。
-
与 RL-based 方法的差距:GoT 和 ToT 一样,是推理时的搜索策略,不做任何训练。在 o1、R1、k1.5 等通过 RL 训练的推理模型面前,GoT 的绝对性能差距很大。GoT 的贡献更多在方法论层面。
-
评分机制依赖 LLM:GoT 的质量评分同样依赖 LLM 自身,这在推理质量尚不高的场景下可能形成恶性循环——模型无法准确评估自身推理的质量。
-
实践影响力有限:尽管概念优雅,GoT 在工业界的实际采用程度远低于 CoT 和 RL-based 推理方法。这主要是因为后续的 o1/R1 等工作证明,将推理能力通过训练内化到模型参数中比在推理时设计复杂的搜索策略更有效。