一句话总结:DeepSeek-R1 首次通过纯强化学习(无需 SFT 冷启动)让 LLM 涌现出推理能力(R1-Zero),然后引入冷启动数据和多阶段训练(R1)进一步提升了推理的可读性和通用能力,最终性能与 OpenAI o1 持平。同时验证了推理能力的蒸馏比让小模型自己做 RL 更高效。
Intro
Motivation
OpenAI o1 系列通过推理时扩展(inference-time scaling)显著提升了复杂推理任务的性能,但有效推理时扩展的技术细节并未公开。此前的研究社区尝试了过程奖励模型(PRM)、MCTS 搜索等方法,均未能达到 o1 级别的通用推理性能。
DeepSeek 的核心探索:**LLM 能否通过纯 RL 自主发展出推理能力?**以及,冷启动数据和多阶段训练能否进一步提升?
贡献
- R1-Zero:首次公开验证纯 RL(无 SFT)可以激发 LLM 推理能力,AIME 2024 pass@1 从 15.6% 提升至 71.0%
- R1 多阶段训练流程:冷启动 SFT → 推理 RL → 拒绝采样 SFT → 全场景 RL
- 蒸馏 > RL(对小模型):从 R1 蒸馏到小模型的效果远超让小模型自己做大规模 RL
- 开源 R1-Zero、R1 及 6 个蒸馏模型(1.5B-70B)
Method 核心方法
DeepSeek-R1 的核心主张:纯 RL 可以在没有 SFT 冷启动的情况下激发推理能力(R1-Zero),再通过冷启动 SFT + 多阶段 RL 结合解决可读性问题(R1)。
训练范式对比:R1-Zero vs R1
| 维度 | R1-Zero | R1 |
|---|---|---|
| 起点 | DeepSeek-V3-Base(无 SFT) | 冷启动 SFT(数千条长 CoT 数据) |
| RL 算法 | GRPO | GRPO + 语言一致性奖励 |
| 奖励 | 准确率 + 格式(rule-based only) | 准确率 + 格式 + 语言一致性 |
| 可读性 | 差(多语言混杂、格式混乱) | 好 |
| 最终输出 | 仅研究价值 | 产品级(经拒绝采样+全场景 RL) |
| AIME 2024 | 71.0 | 79.8 |
R1-Zero:纯 RL 从 Base 模型出发
GRPO 算法:放弃传统 PPO 中与策略模型同大小的 critic 模型,改用 group 内相对评分估计 baseline:
奖励设计:
- 准确率奖励:数学题答对给 1(基于规则验证),代码题通过测试用例
- 格式奖励:强制把推理过程放在
<think></think>标签内 - 不使用神经奖励模型(避免 reward hacking)
模板设计:仅规定 <think> reasoning process </think> <answer> answer </answer> 结构,不预设任何反思、验证等策略,让模型自主发展。
关键现象:
- “Aha Moment”:模型在训练中自主学习到”等等,让我重新检查一下”的行为
- 响应长度随训练自然增长(数百到数千 token)
- 涌现出反思(reflection)和探索替代解法等复杂行为

Figure 2: DeepSeek-R1-Zero 在 AIME 2024 上的训练曲线。纯 RL(无 SFT)让 pass@1 从初始的 15.6% 提升至 71.0%,首次公开验证了 RL 可以独立激发推理能力。
R1:冷启动 + 多阶段训练
四阶段流程:
-
冷启动 SFT:收集数千条长 CoT 数据(few-shot 提示 + R1-Zero 输出精炼 + 人工标注),格式为
|special_token|<reasoning_process>|special_token|<summary>。目的:提升可读性,提供稳定起点 -
推理 RL:与 R1-Zero 相同的大规模 RL,但新增语言一致性奖励(惩罚中英混杂)与原始奖励直接相加
-
拒绝采样 SFT:
- 推理数据(~600k):从 RL checkpoint 做拒绝采样,使用 DeepSeek-V3 做生成式奖励判断,过滤掉语言混杂/冗长/格式混乱的样本
- 非推理数据(~200k):复用 DeepSeek-V3 的 SFT 数据
- 在 DeepSeek-V3-Base 上训练 2 epochs
-
全场景 RL:推理数据用规则奖励,通用数据用奖励模型(只评估最终 summary,不干扰推理过程);同时对齐 helpfulness 和 harmlessness
蒸馏
直接用 R1 生成的 800k 推理数据对 Qwen/Llama 小模型做 SFT(不做 RL),结果大幅超越小模型自己做 RL。
实验/评估/结果
R1 vs 前沿模型
| Benchmark | R1 | o1-1217 | DeepSeek-V3 |
|---|---|---|---|
| AIME 2024 | 79.8 | 79.2 | 39.2 |
| MATH-500 | 97.3 | 96.4 | 90.2 |
| Codeforces Rating | 2029 | 2061 | 1134 |
| SWE Verified | 49.2 | 48.9 | 42.0 |
| MMLU | 90.8 | 91.8 | 88.5 |
| GPQA Diamond | 71.5 | 75.7 | 59.1 |
| AlpacaEval 2.0 | 87.6 | - | 70.0 |
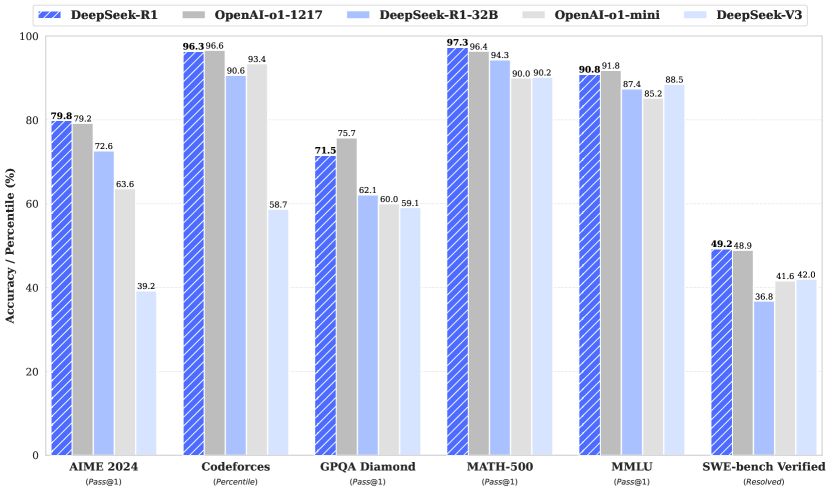
Figure 1: DeepSeek-R1 与 OpenAI o1-1217、DeepSeek-V3 的 benchmark 性能对比。R1 在 AIME 和 MATH-500 上超越 o1。
蒸馏模型
| Model | AIME 2024 |
|---|---|
| R1-Distill-Qwen-1.5B | 28.9 |
| R1-Distill-Qwen-7B | 55.5(超 QwQ-32B) |
| R1-Distill-Qwen-14B | 69.7 |
| R1-Distill-Qwen-32B | 72.6 |
| R1-Distill-Llama-70B | 70.0 |
蒸馏 vs RL(消融)
| 方法 | Qwen-32B AIME |
|---|---|
| QwQ-32B-Preview | 50.0 |
| R1-Zero-Qwen-32B(RL 10k+ steps) | 47.0 |
| R1-Distill-Qwen-32B(蒸馏) | 72.6 |
蒸馏效果远好于让小模型自己做 RL,且成本更低。
失败尝试
- PRM(过程奖励模型):难以定义细粒度步骤、步骤正确性自动标注困难、引入 reward hacking
- MCTS:token 生成空间指数级增长、细粒度 value model 训练困难、自搜索迭代提升受阻
结论
DeepSeek-R1 证明:(1) 纯 RL 可以激发 LLM 推理能力(R1-Zero);(2) 加入冷启动数据和多阶段训练能进一步提升可读性和通用能力(R1);(3) 大模型的推理模式可以高效蒸馏到小模型,效果超越小模型自己 RL。
思考
优点
-
“RL first”的激进实验:R1-Zero 是第一个公开的纯 RL 推理实验。从 base model 出发、无 SFT、规则奖励、简单模板——这种极简设置在之前被认为是不可行的。AIME 从 15.6% 到 71.0% 的结果彻底改变了社区对 RL 在推理中作用的认知。
-
Aha Moment 的定性价值:模型自主学习到”等等,我重新检查一下”这一现象不仅是性能的证明,更是对 RL 在推理中机制的可解释洞察——模型确实在学习”思考”,而非单纯记忆答案。
-
蒸馏 > RL 的结论影响深远:R1-Distill-Qwen-32B (72.6%) vs R1-Zero-Qwen-32B (47.0%) 的对比清晰表明:大模型的推理数据中包含的”推理模式”比小模型自己探索更丰富。这个结论直接影响了后续几乎所有开源推理模型的开发策略。
-
失败尝试的坦诚记录:公开记录 PRM 和 MCTS 的失败经验,为社区节省了大量试错成本。这种坦诚在竞争激烈的大模型领域难得。
-
开源力度:开源了 R1-Zero、R1、6 个蒸馏模型,覆盖面从 1.5B 到 70B,极大地推动了推理研究的民主化。
缺点与局限性
-
R1-Zero 的可读性问题未根治:R1-Zero 混合语言、格式混乱的问题在 R1 中通过冷启动数据缓解了,但 R1 仍然在非中英文查询中倾向于用英文推理。语言混合在深层可能反映了模型在推理阶段主要依赖英文训练数据。
-
RL 训练细节不透明:GRPO 的具体实现、奖励函数权重、训练步数和数据量等关键细节缺失或模糊。论文更偏向效果展示而非方法复现指南。
-
软件工程任务提升有限:R1 在 SWE-bench 上的提升(49.2 vs V3 的 42.0)远不如数学推理的提升幅度。大模型的推理能力在结构化代码工程中的迁移仍是未解决的问题。
-
蒸馏数据的污染风险:R1 蒸馏的 800k 数据来自 R1 自身的拒绝采样,其中可能包含 R1 的特异性偏差(如特定风格的推理格式),蒸馏模型可能会继承这些非泛化的特征。
-
通用能力与推理能力的 trade-off 未量化:R1 在 function calling、多轮对话、角色扮演等通用场景上不如 V3。论文承认这个差距但未提供深入分析或消融实验来量化”推理 RL 对通用能力的冲击”。