1. 论文简介
1.1 研究问题:情感图像处理 (Affective Image Manipulation, AIM)
- 目标:根据用户提供的单一情感词(如“喜悦”、“恐惧”),修改输入图像,使其能够唤起观众特定的情感反应。
- 核心任务:
- 情感保真度:显著地唤起目标情感。
- 结构保持性 (Structure Preservation):尽可能保留原始图像的构图和核心内容。
1.2 本文核心贡献
- 提出 EmoEdit 框架:一个创新的、内容感知的AIM框架,通过修改图像内容来唤起情感,而不仅仅是调整颜色/风格。
- 构建 EmoEditSet 数据集:首个大规模(40,120个数据对)的AIM benchmark。数据为
(source, target, emotion, instruction)四元组,为指令驱动的情感编辑提供了坚实基础。 - 设计 Emotion Adapter:一个轻量级的即插即用模块,能让现有的扩散模型“学会”情感,实现了参数高效的微调。
- 提出 指令损失 (Instruction Loss):一种新的损失函数,用于在训练中捕捉语义层面的变化,显著提升了编辑的质量和逻辑性。
2. EmoEditSet数据集构建
任务:从海量情感图像中,自动挖掘出能够引发特定情感的具体视觉元素(情感因子)
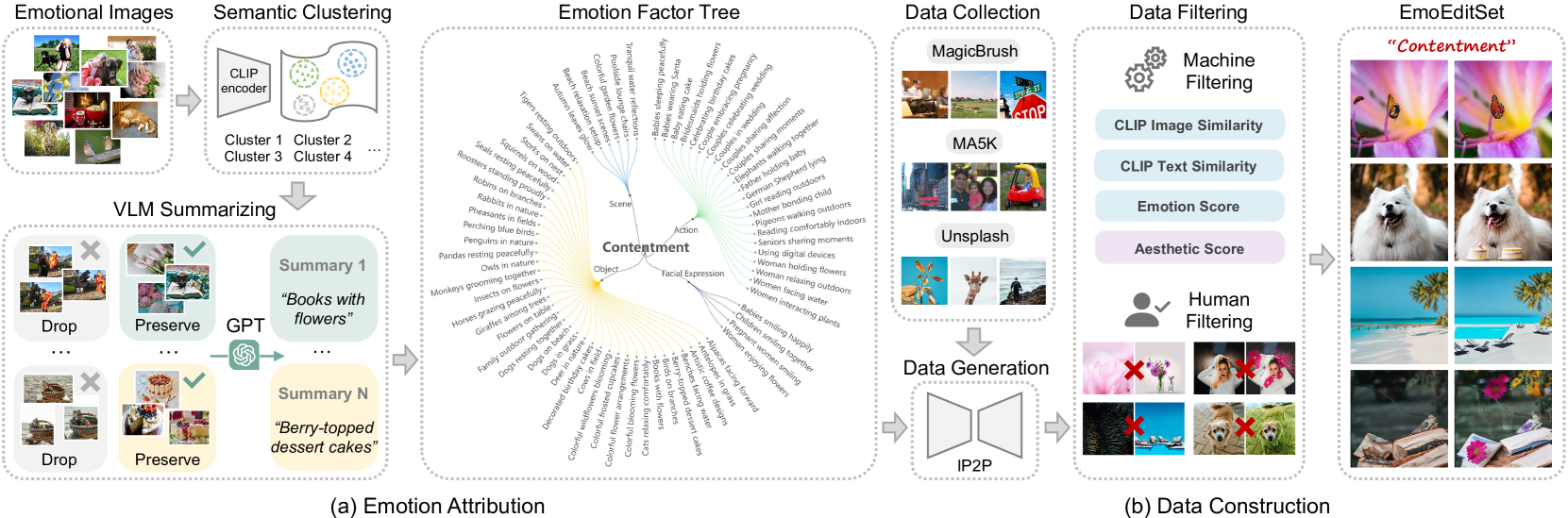
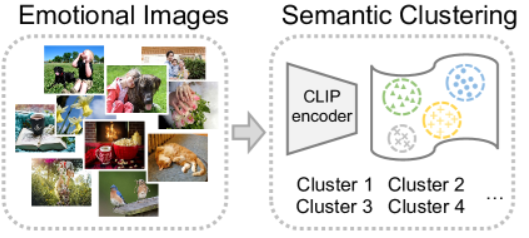
2.1 阶段1:情感归因(Emotion Attribution)
- 任务: 基于 EmoSet,使用各种代表性语义摘要构建情感因素树
- 步骤:
- 使用CLIP捕捉视觉语义,并进行聚类
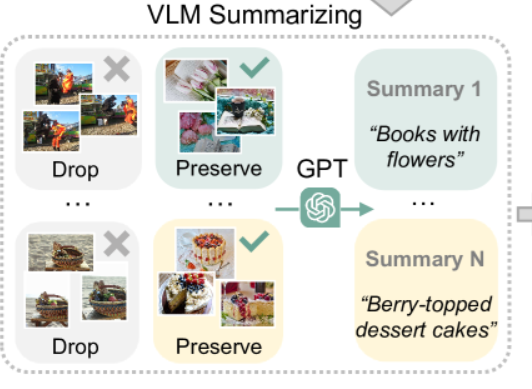
- 后处理,采用 GPT-4V 为每个聚类分配内容摘要
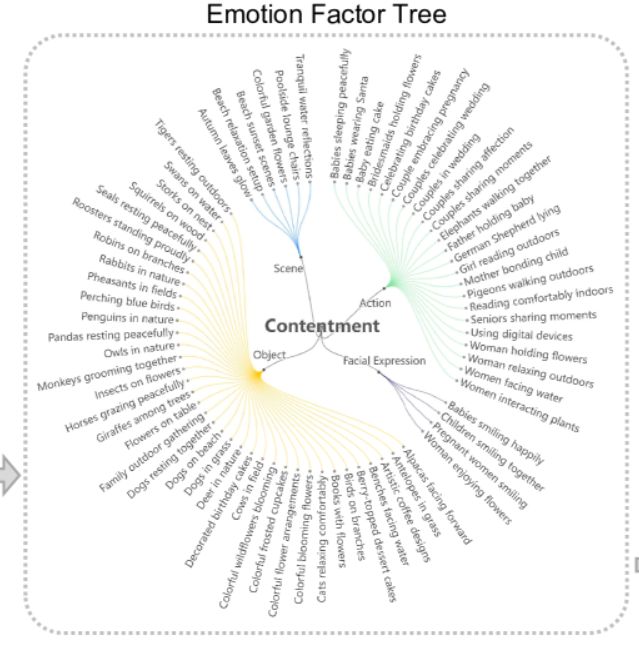
- 将聚类元素转为情感因素,分为物体、场景、动作和面部表情,构建起八颗分别以核心情感**(喜悦、敬畏、满足、兴奋、愤怒、厌恶、恐惧、悲伤)**为根的树。
- 使用CLIP捕捉视觉语义,并进行聚类
2.2 阶段2: 构建数据(Data construction)
- 任务:通过仔细收集、生成和过滤,构建具有高质量和语义多样性的配对数据集EmoEditSet
- 步骤:
- 使用MagicBrush、MA5K 和 Unsplash1得到更大的数据规模和更高的图像多样性

- 利用
IP2P构建情感数据,并进行人工与机器筛选,以三元组格式“源图像-情绪-目标图像“排列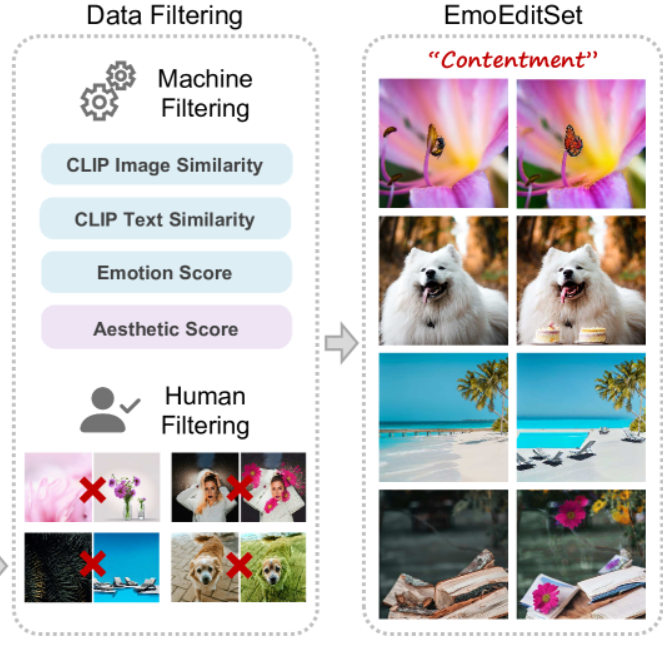
- 使用MagicBrush、MA5K 和 Unsplash1得到更大的数据规模和更高的图像多样性
Note
筛选指标:
- CLIP图像相似度:保证结构不发生剧变。
- CLIP文本相似度:保证编辑内容与指令相关。
- 情感分数 (Emotion Score):保证编辑后的图确实能引发目标情感。
- 美学分数 (Aesthetic Score):保证图片美观。
Info
IP2P: 一种基于人类指令的图像编辑方法:给定一张输入图像和一条指示模型如何操作的文本指令,我们的模型会遵循这些指令来编辑图像。为了获取该问题的训练数据,我们将两个大型预训练模型的认知相结合——一个语言模型(GPT-3)和一个文本到图像模型(Stable Diffusion),以生成一个包含大量图像编辑示例的数据集。
3. EmoEdit 模型方法
任务: 如何将抽象情感智能地应用于具体图像
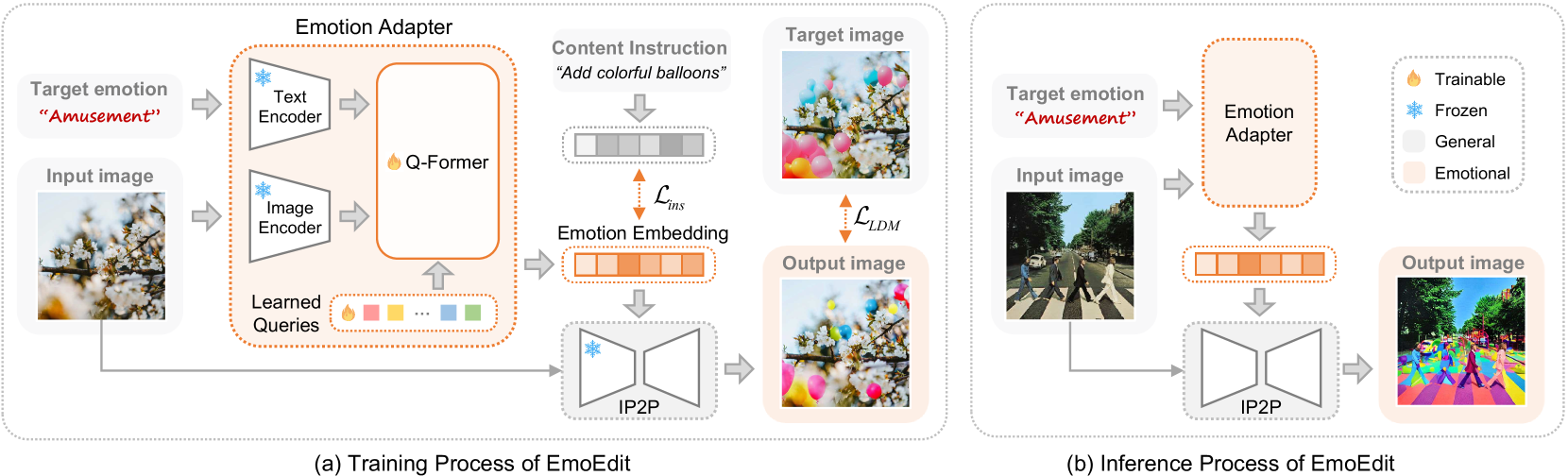
3.1 Emotion Adapter
- 动机:适配器(adapter)可以无缝地插入现有的扩散模型,而无需改变其原始结构
- 模型设计:Q-Former 能够利用一种模态的上下文信息来提升另一种模态的理解能力。我们将这一能力应用于构建 Emotion 适配器,其中目标情绪和输入图像被编码为 和 ,然后通过注意力机制进行融合。具体而言,学习到的查询 充当情绪词典,而 和 作为索引。自注意力机制首先根据目标情绪从该词典中选择相关语义(公式 1),而交叉注意力机制通过考虑情感上下文和输入图像来识别最合适的表示方式(公式 2): 其中 、、 是自注意力模块中学习到的参数,、、 是交叉注意力模块中的参数, 是键的维度。给定情感词典、目标情感和输入图像,我们的情感适配器迭代地整合这三个来源的信息,并生成最合适的情感嵌入 。
Note
, , 是三个可学习的权重矩阵。它们的作用就像是给输入信息赋予不同的“角色”。同一个输入 ,乘以 后就扮演“查询者”的角色,乘以 就扮演“被查询者”的角色,乘以 就扮演“信息提供者”的角色。q-query k-key v-value
3.2 训练策略
- 训练方式:冻结 IP2P 的主干网络,只训练 Emotion Adapter。
- 双重损失函数:
- 扩散损失 :
- 目的:保证像素级的生成质量。这是标准的扩散模型训练损失,确保图像清晰、纹理真实。
- 指令损失 :
- 目的:保证语义级的逻辑正确性。这是本文的关键创新。
- 做法:强制要求Adapter生成的改造计划 ,在语义上必须接近 EmoEditSet 中提供的真实编辑指令 的文本嵌入。
- 效果:极大地缓解了仅用扩散损失时产生的颜色溢出、内容不合逻辑等问题。
- 扩散损失 :
4. 模型评估
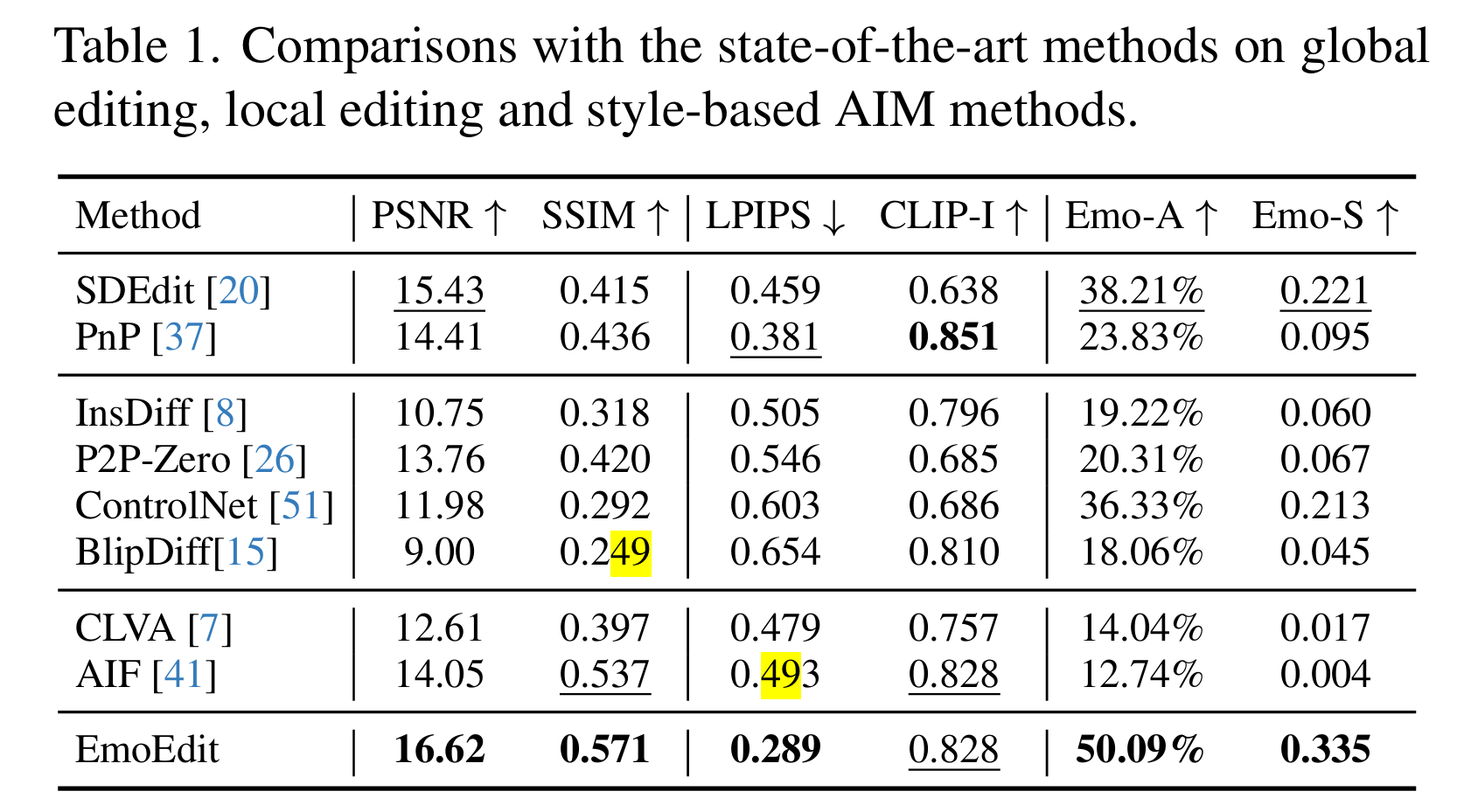
- 评估指标:
- 像素级 (保真度): PSNR, SSIM (越高越好)
- 感知级 (相似度): LPIPS (越低越好)
- 语义级 (一致性): CLIP-I (越高越好)
- 情感级 (有效性): Emo-A (情感准确率), Emo-S (情感增强得分) (越高越好)
- 结论: EmoEdit 在几乎所有指标上都显著优于其他方法,尤其是在情感指标 (Emo-A, Emo-S) 和图像保真度 (PSNR, SSIM) 上,证明其在情感唤起和结构保留之间取得了最佳平衡。
5. 启发
数据构建
在很多新的研究方向上,我们都面临“缺少高质量、大规模配对数据”的困境,可以通过 CLIP聚类 + VLM总结 的方式,设计了包含像素、语义、美学、任务特定(情感)等多个维度的过滤标准,并辅以人工审查,确保最终数据集的质量
PEFT
在算力有限的情况下应当积极考虑采用PEFT方法,冻结大模型参数,,只训练一个轻量级的插件模块,Q-Former和Emotion Adapter都是
指令损失
通过明确的内容指令指导训练过程,以提高图片生成质量