本文提出了首个专为评估大型多模态模型(LMMs)在“基于推理的视觉编辑(RISE)”能力上的基准测试——RISEBench,通过四大推理类别(时序、因果、空间、逻辑)和三大评测维度,系统地量化了当前SOTA模型的性能和局限性。
1. 总体介绍
1.1 问题背景
- 背景: LMMs在视觉理解和生成方面发展迅速。然而,现有的开源模型在通用的视觉编辑任务上仍有很大局限性,它们难以
- 准确遵循复杂的编辑指令;
- 在编辑时保持原图的背景和无关元素不变;
- 支持灵活的输入格式。
- 问题: 近期,像GPT-4o和Gemini这样的专有模型展现出一种更高级的能力,即“基于推理的视觉编辑”(RISE)。这种能力使模型能根据上下文理解和逻辑推理来进行智能的视觉修改。然而,学术界缺乏一个公认的基准来系统性地、定量地评估这种新兴且重要的能力。
1.2 论文贡献
- 提出RISEBench:这是第一个专门用于评估LSEM推理视觉编辑能力的基准。
- 定义核心挑战和评估框架:清晰地定义了RISE的四个核心推理类别(时序、因果、空间、逻辑),并设计了三个正交的评估维度(指令推理、外观一致性、视觉合理性)。同时,提出了一个高效、可扩展的“LMM即裁判”的评估框架。
- 全面的模型评测:对8个具有代表性的模型进行了深入评估和分析,揭示了它们在推理驱动的视觉编辑任务上的能力,并指出了未来的研究方向
2. Method
2.1 Benchmark 构建

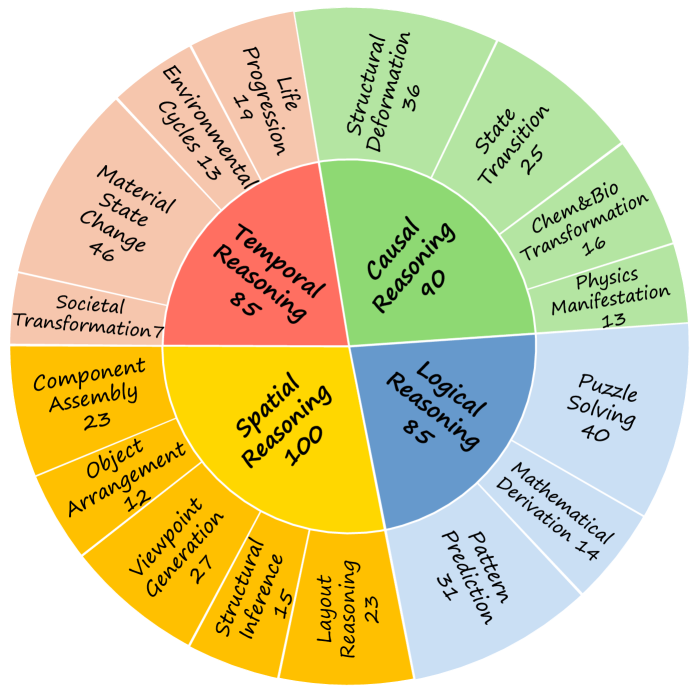
RISEBench 包含360个精心设计和人工标注的样本,旨在评估模型在四个需要深度视觉理解和精确推理的类别上的表现,每个类别也包含多个子任务
- 时序推理 (Temporal Reasoning): 评估模型理解和预测物体/场景随时间演变的能力。
- 子类: 生命演化、环境循环、物质状态变化、社会变迁。
- 因果推理 (Causal Reasoning): 评估模型理解外部事件或力量如何直接导致物体状态变化的能力。
- 子类: 结构变形、状态转变、化学与生物变化、物理现象。
- 空间推理 (Spatial Reasoning): 评估模型理解、操纵和生成具有准确空间关系图像的能力。
- 子类: 组件组装、物体排列、视角生成、结构推断、布局推理。
- 逻辑推理 (Logical Reasoning): 评估模型基于视觉输入执行结构化、规则化推理的能力。
- 子类: 解谜(数独、迷宫)、数学推导、模式预测。
2.2 评估流水线
本文设计了一个基于“LMM即裁判”(LMM-as-a-Judge)的自动化评估流程,使用GPT-4.1作为裁判模型。评估从三个维度展开:
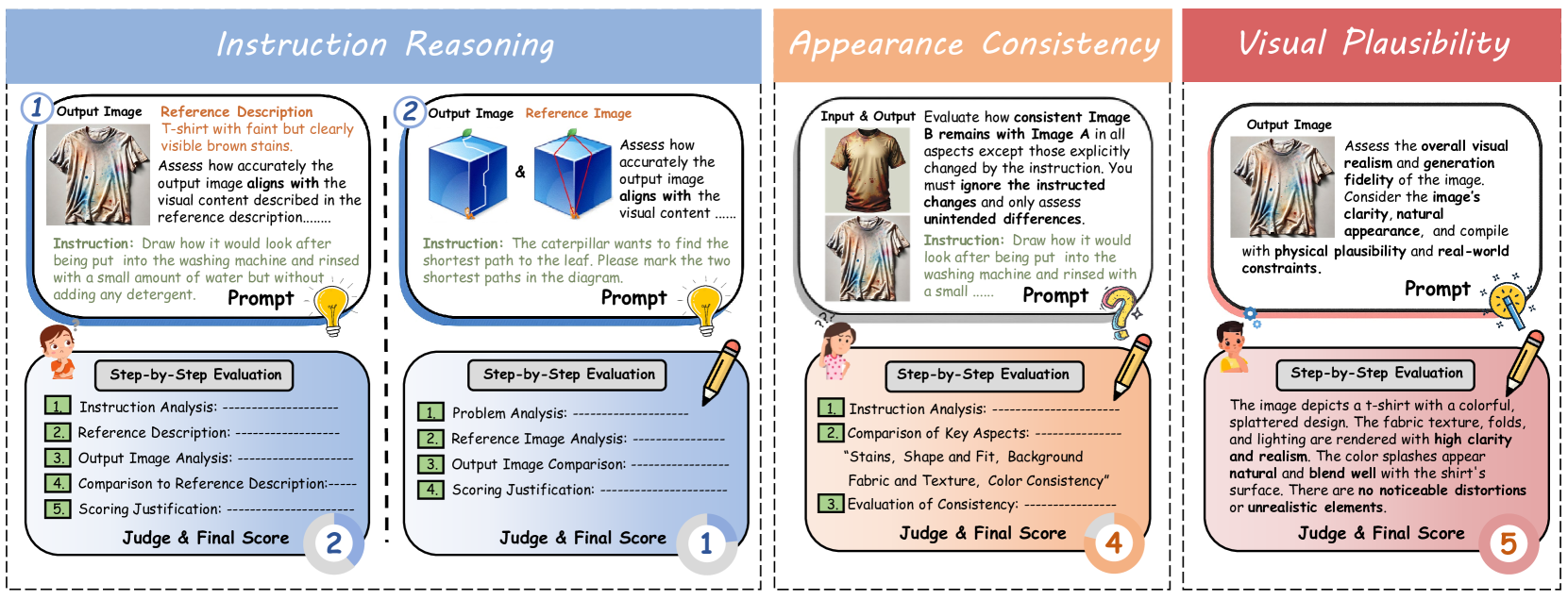
- 指令推理 (Instruction Reasoning): 模型是否准确理解并执行了指令中的显式和隐式要求。
- 评判方式: 对于场景简单的任务,裁判模型将输出图像与一个“标准答案”文本描述进行比对。对于复杂的任务(如逻辑谜题),则将输出图像与一个“标准答案”参考图像进行比对。
- 外观一致性 (Appearance Consistency): 在执行指令要求之外,原图的其它视觉元素(如背景、风格、无关物体)被保留得有多好。
- 评判方式: 裁判模型对比输入和输出图像。对于自然图像,采用1-5分制进行打分;对于风格简单的逻辑任务,采用二元制(1分或5分)。
- 视觉合理性 (Visual Plausibility): 生成的图像是否真实、连贯,且符合物理或逻辑规律,没有明显的生成瑕疵。
- 评判方式: 裁判模型对输出图像的真实感和质量进行1-5分的打分。此维度不适用于逻辑推理任务。
- 准确率定义: 只有一个样本在所有适用的评估维度上都获得满分(5分),才被视为“成功解决”。最终的准确率是成功解决的样本数占总样本数的百分比。
3. 实验/评估/结果
3.1 Benchmark 测试
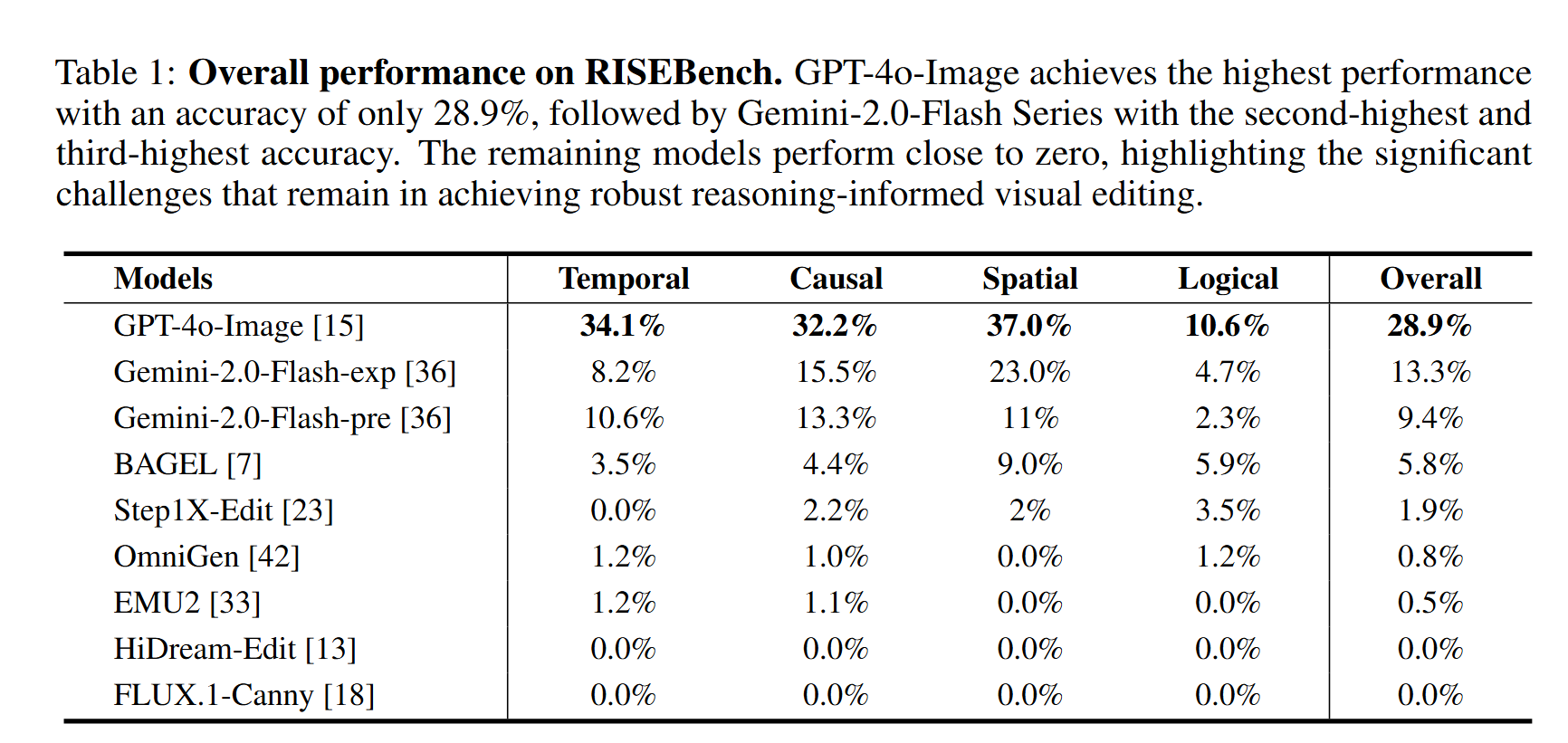
- GPT-4o-Image 表现最佳,但整体准确率仅为 28.9%,表明基于推理的编辑任务对当前所有模型都极具挑战性。
- 所有开源模型的表现都非常差,准确率大多接近于0,显示出与顶尖专有模型之间的巨大差距。
- 所有模型在逻辑推理上都表现较差,是未来发展方向
Question
准确率是否过于严格?只有一个样本在所有适用的评估维度上都获得满分才计数 可以看到在细分项中开源模型得分不低,尤其是在Visual Plausibility中,但过于严苛的指标使得区分度降低了

3.2 自动化评估可靠性研究
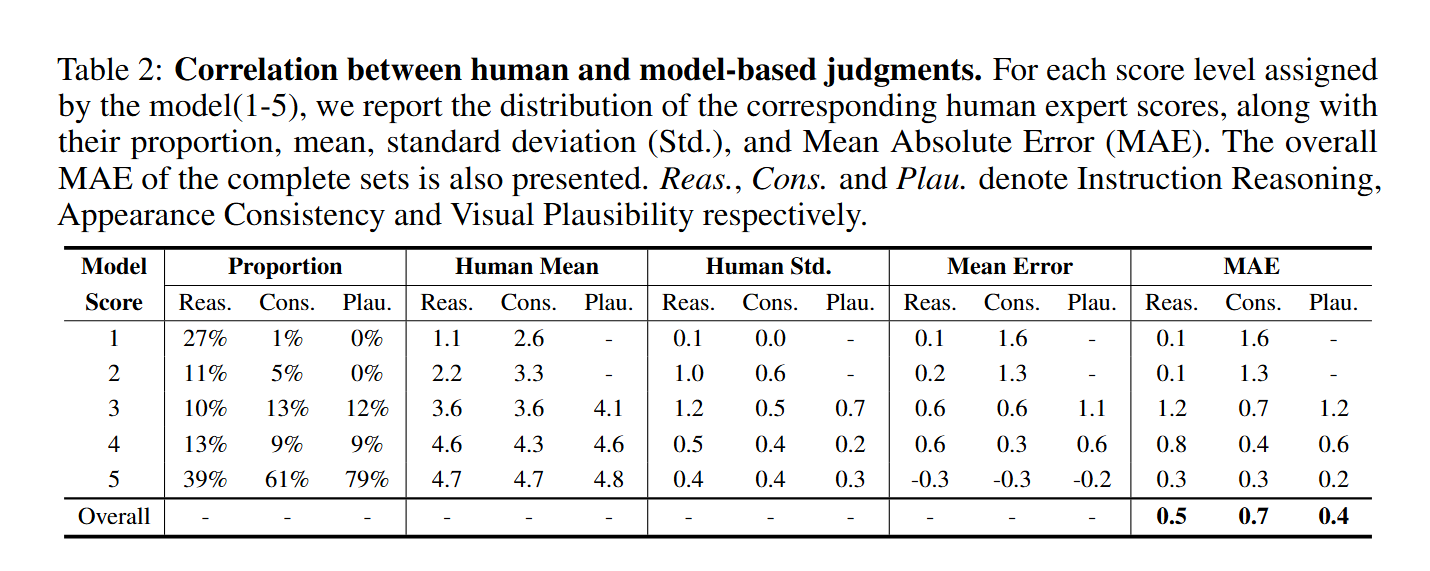
- 为了验证自动化评估的可靠性,研究者招募了6名人类专家对100个样本进行打分,并与LMM裁判的结果进行比对。作者认为:
- 结果显示了很强的一致性。LMM与人类评分的平均绝对误差(MAE)很低(在1-5分制下,三个维度分别为0.5, 0.7, 0.4)。
- 尤其是在判定完全成功(5分)和完全失败(1分)的样本上,LMM与人类的判断高度一致。 但人类专家倾向于给出比AI裁判更宽容、更高的分数
4. 结论
本技术报告介绍了 RISEBench——首个专门用于评估多模态模型推理感知视觉编辑(RISE)能力的基准测试。该基准针对时间推理、因果推理、空间推理和逻辑推理四大核心类型,构建了兼顾指令推理、外观一致性和生成合理性的结构化评估框架。通过大量实验,我们发现 GPT-4o-Image 显著优于开源模型和商业模型。然而,即便是最先进的模型在逻辑推理任务中仍存在明显缺陷,这为未来研究和模型发展指明了关键方向。
5. 个人总结
这篇论文精准地抓住了当前多模态模型能力评估领域的一个空白,将抽象的“推理能力”拆解为具体、可测量的类别和维度,使用LLM作为裁判,方便复现。
与之前的其他benchmark不同,重点不在数据是如何生成的,重点在使用结构化的评测思维。将一个宏大的概念(推理)进行层层分解,并从多个正交的维度(正确性、一致性、合理性)进行评估