GoT 通过让多模态大语言模型先生成一个包含精确坐标的“生成式思维链”来指导扩散模型,从而实现了对图像生成与编辑前所未有的精确控制和可解释性。
1. 总体介绍
1.1 问题背景
背景:目前的图像生成和编辑方法大多直接将文本提示作为输入,缺乏对视觉构图和具体操作的显式推理过程。这导致它们在处理复杂场景时能力不足。
现有解决方案及其不足:
- 基于 Layout 的方法 (如 GLIGEN, LayoutGPT):这些方法允许用户通过边界框来控制对象位置。但它们通常将“布局规划”和“图像生成”视为两个分离的阶段,缺乏端到端的优化和推理的深度融合。
- 统一的 MLLM (如 Emu2):一些模型试图统一理解和生成任务,但它们并没有真正利用模型的推理能力来指导生成过程,更像是将不同的任务模块拼接在一起。
1.2 论文贡献
- 提出 GoT 范式: 首次提出将“思维链”思想引入视觉生成,将生成过程从直接映射转变为“先推理,后生成”的模式。
- 构建大规模 GoT 数据集: 通过自动化流程,构建了包含超过 9M 样本的 GoT 数据集,为训练这种推理-生成模型提供了数据基础。
- 设计统一的 GoT 框架: 开发了一个端到端的框架,包含一个能够生成 GoT 推理链的 MLLM,以及一个新颖的语义-空间指导模块 (SSGM),该模块能有效利用 GoT 推理链来指导 Diffusion 模型。
- SOTA 性能和新能力: 在文本到图像生成和图像编辑任务上取得了最先进的结果,并实现了独特的交互式生成能力。
2. Method
2.1 GoT 的核心理念
GoT 推理链的定义: 它是一种多模态的推理链,融合了语义(描述对象、属性、关系)和空间((x1,y1),(x2,y2) 格式的坐标)信息。
- 对于生成任务,它详细描述了场景中的每个元素及其位置。
- 对于编辑任务,它分解为:1. 描述原图 → 2. 识别被编辑对象及其位置 → 3. 描述修改操作 → 4. 描述编辑后的图像。
2.2 GoT 数据集构建
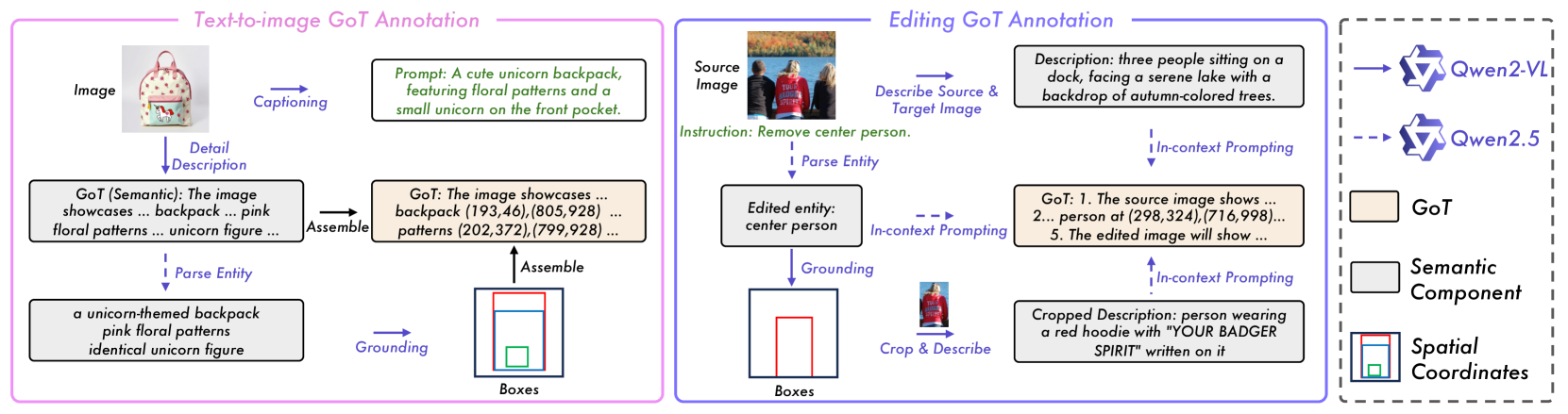
2.2.1Text-to-Image GoT Annotation
- 生成提示和详细描述: 给定一张图片,使用 Qwen2-VL 模型生成一个简短的提示 (作为 T2I 的输入) 和一段非常详细的场景描述 (作为 GoT 的语义部分)。
- 实体解析: 使用 Qwen2.5 从详细描述中抽取出所有的关键对象实体。
- 实体定位: 再次使用 Qwen2-VL,将上一步抽取的每个实体在原始图像中定位,并输出其边界框坐标。
- 组装 (Assemble): 将详细描述和每个实体的坐标信息整合在一起,形成最终的 T2I GoT 标注。
2.2.2 Editing GoT Annotation
- 描述源图和目标图: 给定编辑前后的图像对,使用 Qwen2-VL 分别生成详细的描述。
- 定位编辑区域: 通过对比两张图,模型(Qwen2-VL)可以识别出被修改的物体,并对其进行定位。
- 描述编辑细节: 对于被编辑的物体,将其裁剪出来,再让 Qwen2-VL 进行详细描述,以获取更精细的属性信息。
- 合成 GoT 推理链: 使用 Qwen2.5,结合源图描述、目标图描述、编辑指令和定位信息,通过精心设计的 In-context Prompting (上下文提示) 技术,自动生成符合格式的、逻辑连贯的 GoT 编辑推理链。
2.2.3 数据来源
- T2I: Laion-Aesthetics-High-Resolution (LAHR), JourneyDB, FLUX.1
- Edit: OmniEdit(单轮),SEED-Edit-Multiturn(多轮)
资源消耗极大:100*A100*24h*30d
2.3 GoT框架设计
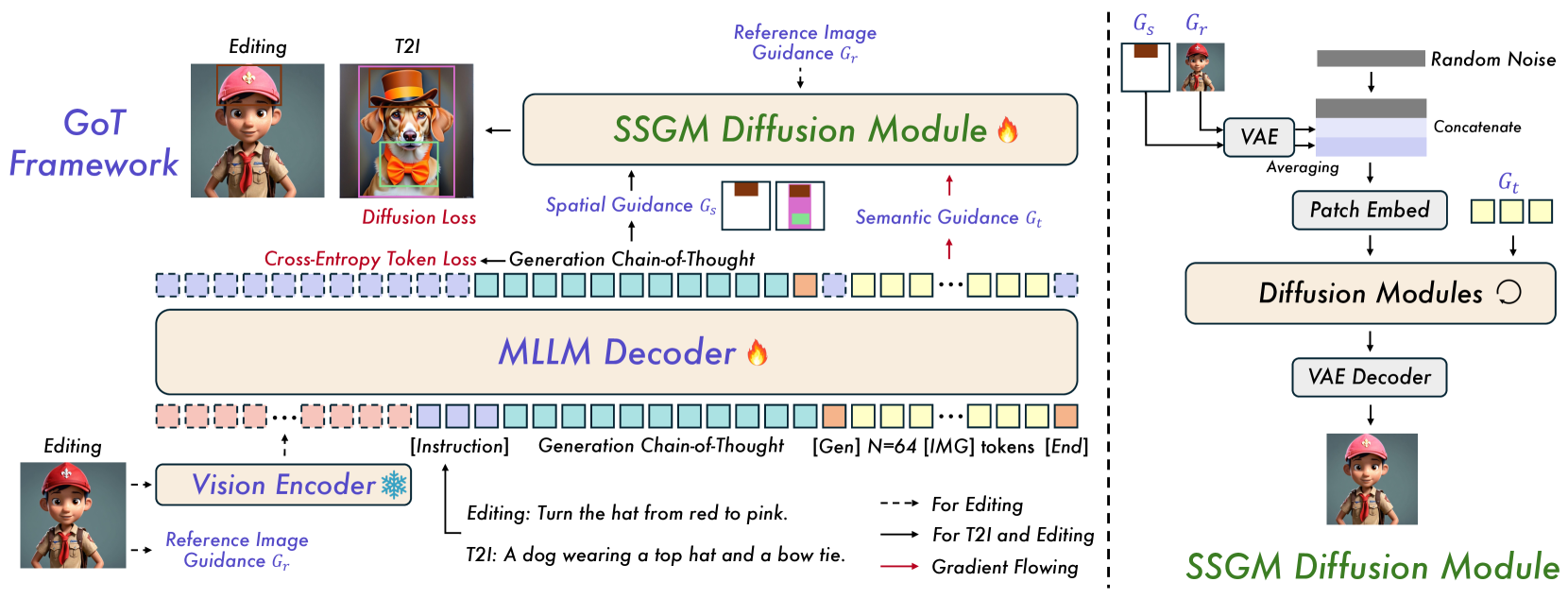
GoT框架主要由 MLLM 推理引擎和 Diffusion 生成模块两部分组成。
2.3.1 MLLM
基于 Qwen2.5-VL-3B 构建。对于编辑任务,它通过视觉编码器处理参考图像以理解源内容。在生成和编辑任务中,MLLM 都会生成 GoT 推理链,捕捉物体属性、关系、修改及边界框信息。推理链生成后,模型会生成图像起始标记及随后的 N=64 特殊[IMG]标记 从 MLLM 的输出中,会产生三种指导信号,送往 SSGM 模块:
- Semantic Guidance Gt (语义指导): 由 64 个 [IMG] token 的嵌入向量构成。
- Spatial Guidance Gs (空间指导): 从 GoT 推理链文本中解析出坐标,生成彩色掩码,再编码成 Gs。
- Reference Image Guidance Gr (参考图像指导): 对于编辑任务,原始图像被编码成 Gr。
2.3.2 SSGM Diffusion Module
扩散模块基于 SDXL 架构
-
空间指导 Gs 的注入:
- 路径: Gs (来自彩色掩码的潜变量) 与噪声 zt 进行通道拼接 (Concatenate)。
- 原理: 这是一种强约束。它直接在 U-Net 的输入层修改了潜变量的结构,相当于在每个空间位置上都打上了“标签”,告诉模型这个像素区域应该是什么。
-
语义指导 Gt 和参考指导 Gr 的注入:
- 路径: Gt (来自 MLLM 的 [IMG] token) 和 Gr (来自参考图像) 被送入 U-Net 内部的 Cross-Attention 层。
- 原理: 这是一种软约束。Gt 和 Gr 作为 key 和 value,与图像本身的特征 query 进行注意力计算,从而在语义和风格层面上影响生成过程。
-
VAE Patch Embed: 对于参考图像 Gr,除了通过 Cross-Attention 注入,它的 patch 嵌入也会与噪声进行加权平均 (Averaging),这是一种在 InstructPix2Pix 等工作中常见的技术,可以更好地保留原图的结构信息。