一句话总结:本文提出了一项名为“世界指令图像编辑” (world-instructed image editing) 的新任务,并为此精心构建了一个大规模数据集EDITWORLD,通过训练和优化一个能够理解并模拟物理世界动态变化的编辑模型,实现了对复杂、动态指令的真实响应,显著超越了现有方法。
1. 总体介绍
1.1 问题背景
- 现存问题: 现有的指令编辑模型虽然能处理“给男人戴上帽子”这类简单指令,但无法理解和执行涉及物理规律、时间流逝或因果关系的复杂指令,例如“如果这个男人滑倒了会发生什么?”。根本原因在于缺乏能够反映真实世界动态的训练数据
1.2 论文贡献:
- 提出新任务: 首次定义了“世界指令图像编辑”这一新任务,要求模型模拟真实或虚拟世界中的动态变化来编辑图像。作者将这些指令系统地分为7大类别。
- 构建新数据集 (EDITWORLD): 为了支持这项新任务,作者通过一个创新的两分支流程,利用多个大型预训练模型,构建了一个包含大量(输入-指令-输出)三元组的新数据集EDITWORLD。
- 提出新方法: 在此数据集上训练并改进了一个扩散编辑模型,并提出了一种后编辑策略来优化结果,使其在保持非编辑区一致性的同时,能更好地遵循复杂指令。该方法在新的任务上取得了SOTA(State-of-the-art)性能。
2. Method
2.1 世界指令
作者首先将世界指令分为两大类:真实世界和虚拟世界。并进一步细化为七个子类
- 真实世界: Long-Term (长期变化), Spatial-Trans (空间变换), Physical-Trans (物理变换), Implicit-Logic (隐式逻辑)。
- 虚拟世界: Story-Type (故事型), Real-to-Virtual (现实转虚拟), Exaggeration (夸张)。

2.2 EDITWORLD数据集的生成
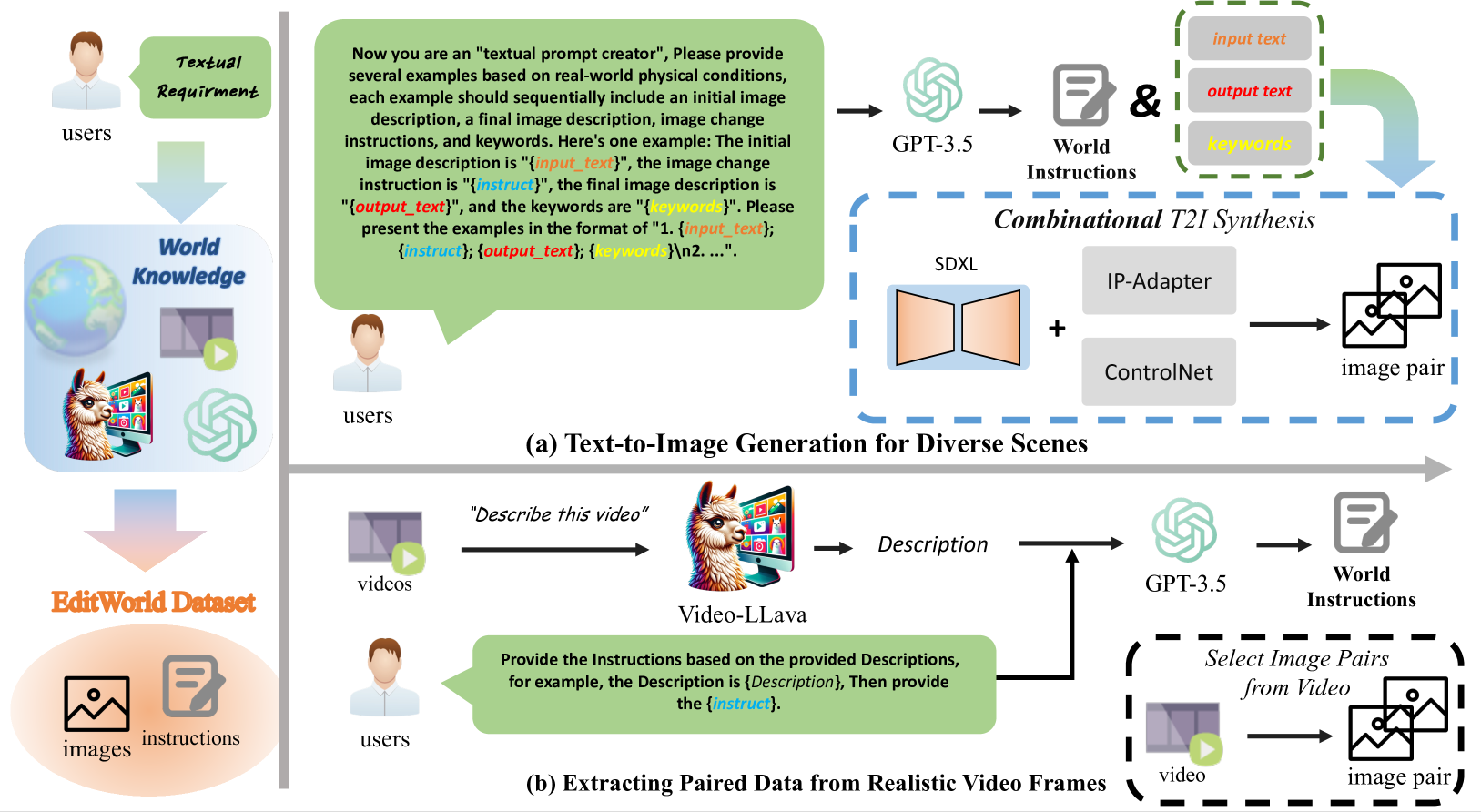
2.2.1 文本到图像生成 (Text-to-Image Generation)
- 指令生成: 利用精心设计的模板,让GPT-3.5生成包含“输入描述”、“编辑指令”、“输出描述”和“关键词”的文本四元组。
Prompt
现在你是一个“文本提示创建者”,请根据现实世界的物理情况提供几个例子,每个例子应依次包含初始图像描述、最终图像描述、图像更改指令和关键词。这是一个例子:初始图像描述是“{input_text}”,图像更改指令是“{instruct}”,最终图像描述是“{output_text}”,关键词是“{keywords}”。请按照“1. {input_text}; {instruct}; {output_text}; {keywords}\n2…”的格式呈现这些例子。
- 组合式T2I合成: 这是一个精巧的多阶段图像生成流程。
- 使用SDXL根据“输入描述”生成原始图像。
- 利用生成时与“关键词”相关的交叉注意力图,定位编辑区域并生成二值掩码。
- 在的掩码区域内,根据“输出描述”进行图像修复,生成初步的目标图像。
- 为了保证身份一致性和结构保留,使用IP-Adapter(提取的视觉特征)和ControlNet(利用目标图像的Canny边缘图)来引导和优化目标图像的生成。
- 最后,用一个多模态大语言模型(MLLM)作为判别器,从语义对齐、身份一致性和图像质量等角度筛选出最合理的图像对。
通过该文生图分支可获得的世界指令类型包括:长期演变型、物理转换型、隐式逻辑型、故事叙述型以及虚实转换型。
2.2.2 从真实视频中提取数据
- 从视频数据库(InternVid)中,挑选出两个能代表一个动作“开始”和“结束”的视频帧。这两帧需满足主体身份一致,但姿态或场景有显著动态变化。
- 使用视频语言模型Video-LLava来生成对这个视频片段(即动态过程)的描述。
- 使用GPT-3.5将上述描述转化为一句具体的编辑指令。
- 这样,起始帧、结束帧和生成的指令就构成了一个(输入-指令-输出)三元组。
该视频数据提取的三元组实例包含以下类型的世界指令:空间变换、物理变换、故事类型和夸张效果。
2.3 EDITWORLD的图像编辑模型
- 模型训练: 作者在他们构建的EDITWORLD数据集上,对InstructPix2Pix进行的微调。
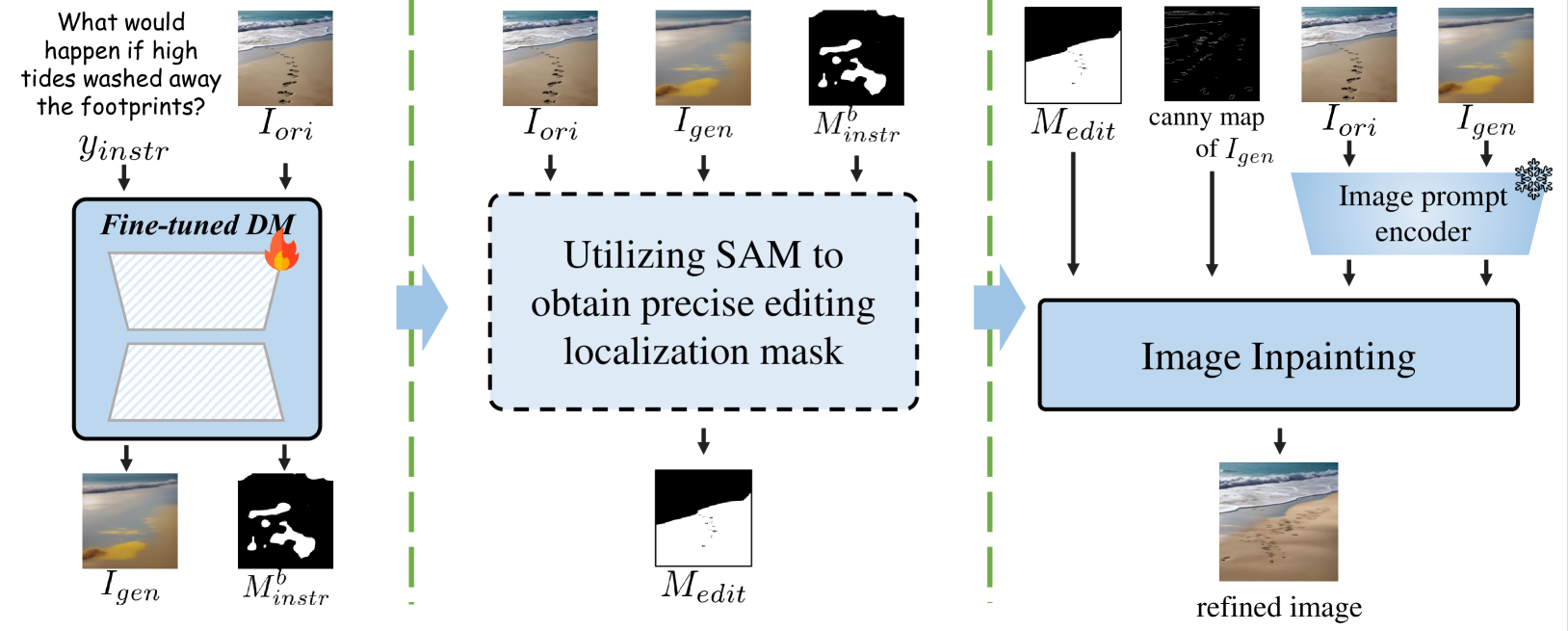
- 后编辑方法 (Post-Edit Method): 为了进一步提升编辑质量并保护非编辑区域,作者设计了一个后处理步骤。
- 模型先根据指令生成一个初步的编辑结果。
- 在推理时,从模型的注意力图中提取一个大致的编辑位置掩码。
- 使用SAM模型分别对原始图像和生成图像进行分割,并找到与重叠度最高的分割块,从而得到一个更精确的编辑掩码。
- 最后,在一个图像修复(Inpainting)流程中,结合、精确掩码、的Canny边缘图以及和的视觉特征,生成最终的、高质量的精修图像。这个过程确保了非编辑区域被完美保留。
3. 实验/评估/结果
3.1 实验设置
- 实验设置: 从文本到图像分支中随机选取 300 组数据三元组,并从视频分支中抽取 200 组数据样本用于测试。剩余数据用于训练 EditWorld 的图像编辑模型。
- 基线模型: 涵盖了多种文本和指令驱动的编辑方法,如DiffEdit, InstructPix2Pix (IP2P), MagicBrush (MB), MGIE等。
- 评价指标: 使用CLIP Score来衡量生成结果与目标文本描述的语义相似度,并引入MLLM Score:
- 具体而言,我们向 Video-LLava 模型提供编辑后的图像、输入输出文本及操作指令,其评分提示词设定为:“输入描述<input text>,编辑指令<instruction>,输出描述<output text>。请判断给定编辑图像是否成功完成编辑,若成功返回 1,失败返回 0”
3.2 实验结果
3.2.1 定量分析
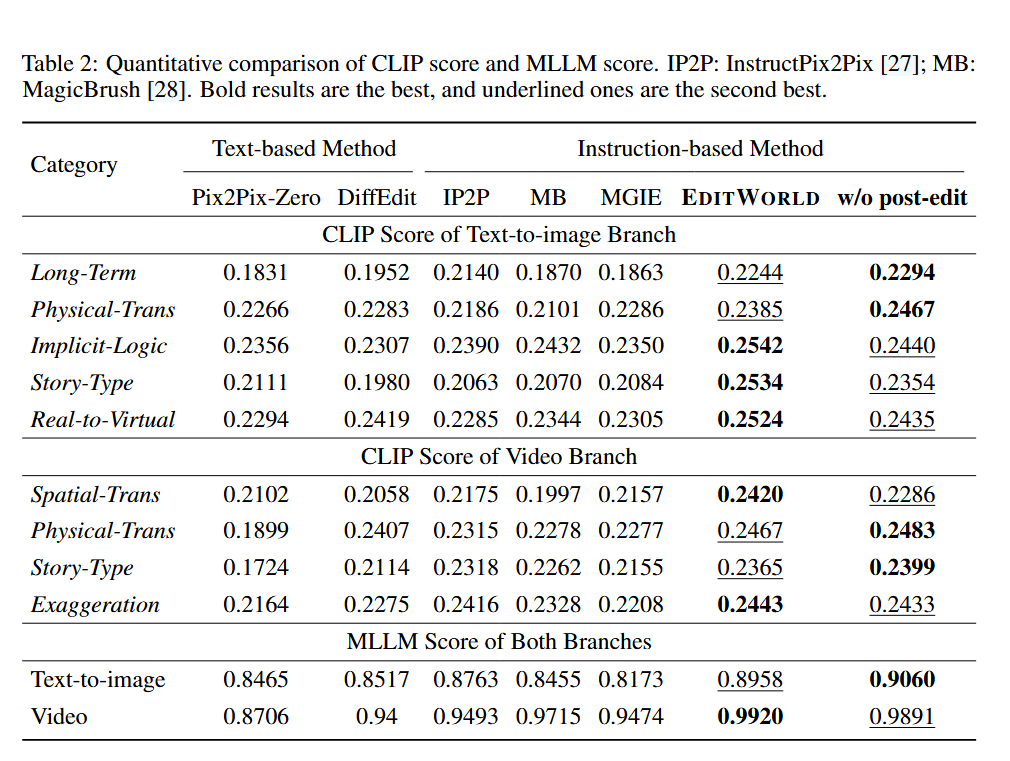
EDITWORLD在几乎所有类别的测试中,其CLIP Score和MLLM Score都显著高于所有基线方法。这证明了其在处理世界动态指令上的卓越能力。值得注意的是,即使没有后编辑步骤,模型的性能也已经非常强大,凸显了高质量数据集的关键作用。
3.2.2 定性分析

EDITWORLD则能生成符合逻辑和物理常识的高质量图像。
3.2.3 消融实验
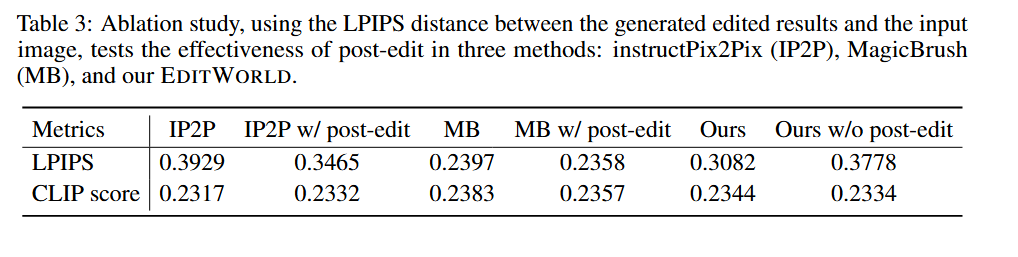
该实验验证了后编辑模块的有效性。结果显示,该模块在保持CLIP分数(编辑效果)的同时,显著提高了LPIPS分数(越低说明越相似),证明它成功地保护了非编辑区域不被修改。
4. 结论
我们提出了一种名为”世界指令图像编辑”的新图像编辑任务,该任务利用现实和虚拟世界中的不同场景为图像编辑提供操作指令。我们对这些指令进行分类、定义和示例说明,并运用 GPT、大规模多模态模型以及文生图模型,从海量视频和文本中获取图像编辑数据。基于这些数据,我们构建了世界指令图像编辑任务的量化评估指标,并利用收集的数据训练和改进图像编辑模型,在这一新型世界指令图像编辑任务中实现了最先进的(SOTA)性能表现。
5. 个人总结
最大的借鉴在于如何定义一个有价值的新问题,以及如何利用现有的AI工具链创造性地构建解决该问题所需的数据。